Change Data Capture is having a moment. Why?
September 21, 2021

Change Data Capture (CDC) concepts have been around for 20+ years, but recently we’ve seen a step-change increase in discussion, companies, and tools in the CDC space. What’s going on? Why is CDC suddenly cropping up everywhere?
To make sure this wasn’t just a case of frequency illusion, I talked to four experts who have been working with CDC and related technologies for years and got their perspectives.
The experts
- Gunnar Morling, Open Source Software Engineer at Red Hat and Lead of Debezium.
- Adam Boscarino, Manager of Data Engineering at Devoted Health.
- Taron Foxworth, Developer Advocate at Meroxa.
- Arjun Narayan, CEO, and Cofounder of Materialize.
The verdict
CDC adoption is indeed accelerating. Why? People I talked to link it to:
I’ve compiled their insights and added takeaways for others evaluating CDC below.
What value does CDC provide?
Before we get into what is causing so many to turn to CDC now, let’s take a step back. What is the value that CDC provides? One way to look at it:
CDC architecturally decouples use-cases from the production database.
Databases are contended resources for organizations. One person’s index to speed up their reads slows down another person’s writes. As a consequence, databases are a centralized source of a lot of organizational horse-trading.
With CDC, getting the change feed out of the database takes a predictable amount of CPU and storage overhead, similar to enabling a read-replica. Once it’s out, the OLTP constraints disappear, and unlike batch ELT, it’s still live data.
Why is CDC adoption accelerating?
The first three theories revolve around “Technology Readiness”. Everyone I spoke with brought up the ecosystem’s stability and maturity as a cause of today’s accelerating adoption of CDC.
1. Stable log formats in the Source Databases
Adam Boscarino attributed it to improvements to the write-ahead log (WAL) or binlog of the upstream databases: “Many years ago, I helped set up a system around CDC using SQL Server, and it ended up being very brittle to the point CDC became a bad word at the company. Now thanks to work done in MySQL and Postgres, it is becoming the first option for many companies even if they don’t know they’re using it with SaaS products like Fivetran.”
Upstream databases like PostgreSQL and MySQL have gotten good at enabling log-based CDC. Their log formats have stabilized and provide all the information needed for CDC. MongoDB’s CDC story is getting better. The new generation of databases like CockroachDB and ScyllaDB now have CDC as first-class features.
How this impacts your decision to use CDC
If you’ve evaluated CDC in the past and found the blocker to be your source database, look again. Even the cloud providers are catching up: Google CloudSQL finally fixed a long-running issue blocking CDC functionality.
2. Maturity within the CDC tools themselves
Gunnar Morling has been at the forefront of CDC as the Debezium project lead.
“Debezium now offers CDC support for a variety of databases, exposing a largely unified event format, so consumers don’t have to care too much about the source of a particular change event.”
How this impacts your decision to use CDC
Ramping up with CDC today is a known and well-documented process, tools have emerged to cater to varying use-cases:
- Debezium has reached an inflection point. An ecosystem of connectors and tooling has started to grow up around it. Companies like Shopify are using it in production.
- SaaS products like Meroxa and Blitzz are packaging up CDC “as-a-service” for those who don’t want to manage infrastructure. Supabase is mainly an application platform but has a real-time subscriptions feature that uses CDC. Data platforms like FiveTran use CDC under the hood to move data from production DB to data warehouse faster.
3. Kafka ubiquity
Arjun Narayan sees Kafka adoption as inextricably linked to the usability of CDC. “Before Kafka, if you used a message bus downstream of a database, any contention or lag would require either:
- Dropping data on the floor (which doesn’t work in a CDC world because if you miss an insert, later deletes are problematic)
- Slowing the database down. If that is the case, you might as well query the database directly since you’re giving up the actual value (decoupling your use from imposing resource constraints on the source database).
Kafka is the first message bus that truly decouples subscribers from publishers – because it’s essentially an infinite buffer. No matter how bad a subscriber gets (because of crashes or whatnot), the broker absorbs the pain. Once you have Kafka, CDC becomes much more attractive as an architectural choice.”
How this impacts your decision to use CDC
- If you’re already using Kafka... Turning on CDC is a much smaller lift. If you’re evaluating CDC, you can think through whether you want this to be a part of an overall streaming transformation.
- If you've avoided Kafka because it wasn't worth the complexity overhead... Kafka has reached a level of ubiquity where "getting the benefits of Kafka" doesn't always require "managing a Kafka cluster". Cloud providers from the big three to Confluent and Heroku have multiple flavors of managed Kafka that give you more choices along the gradient between “self-hosted” and “fully-managed.” New offerings like Redpanda have even just taken the Kafka API and rebuilt the underlying software to be radically simpler and faster.
4. Industry Trends (Distributed Systems)
CDC isn’t growing in a vacuum. Its acceleration is aided by adjacent software trends that increase the need for a feed of data untethered from the transactional database.
Gunnar sees shifts in enterprise architectures that create a need for CDC: “The architectural shift away from monoliths to microservices amplifies the need for fast and efficient data exchange between the different services, as they shouldn’t share data stores, but at the same time don’t exist in isolation and often do need to exchange data amongst each other. CDC is means of doing that.”
Taron Foxworth sees the shift to distributed systems accelerating with more than just enterprise-scale software teams too: “Now with the adoption of Functions as a Service (FaaS), deploying a microservice that responds to CDC events is a no-brainer, it gives us a powerful primitive for building event-driven systems.”
How this impacts your decision to use CDC
CDC is a major capability change towards the bottom of your stack. The stubbornly monolithic database is often the root cause of reasons not to adopt more of a distributed model, and CDC helps change that.
Because CDC changes the capabilities at such a low level, it means it’s worth thinking about: “We may be adopting CDC for X, but does it also change our options for Y and Z.”
Loop other teams at your company into the CDC evaluation process, and they may bring to light new capabilities that CDC can enable.
For example, you may first adopt CDC to decrease latency between the transactional database and business intelligence (BI) dashboards. But, the work required to adopt it may be equally valuable for faster search indexes, user-facing analytics, and powerful automation across multiple teams.
5. Evolution of Data Teams
Data Teams (Data Engineering, Analytics Engineering) are arguably the largest group of current CDC users and the group with the most to gain from CDC in terms of capabilities. This is intuitive: the field is developing faster.
Adam Boscarino captured this shift perfectly: “For years, I was on Data Engineering teams that were not resourced like engineering teams. We weren’t given access to deploy tools and were often stuck using whatever the Ops team had time to spin up (a single server, EC2 instance, etc.). Now we have the same ability to deploy applications as any other engineering team and can try things like Debezium or our own tools very easily. The role has pivoted from just ETL to more of a DevOps/DataOps type thing as a result.”
How this impacts your decision to use CDC
When data teams are staffed and funded to act as software engineers, they level up the entire business’s data capabilities. The new data team paired with modern data tools like those running CDC can make progress that outpaces business demands for data:
- Remove blockers caused by unavailable, broken, or stale data
- Automate processes that are currently unnecessarily slow and manual “human-in-the-loop” decision-making.
- Create new user-facing data capabilities for your customers.
Conclusion
Change data capture adoption has hit an inflection point due to a well-timed confluence of:
- “CDC Stack” (Database, CDC software, destination systems) becoming more mature.
- Industry trends creating more demand for data untethered from the production database
- Evolving data teams that act more like software engineers and demand the tooling to match.
As a result, the decision-making process for “should I adopt CDC to solve X” has evolved. Now, more than ever, It’s worthwhile to not only look at CDC-based solutions for specific data challenges within a company, but also “fan-out” and discuss how other teams might improve their own processes with CDC capabilities.
If you’re already using or setting up CDC, try Materialize.
Materialize lets you run traditional SQL queries on streams of data and get a materialized view that is always up-to-date. CDC events are perfect input to Materialize for creating real-time views to power business analytics, internal APIs, even user-facing analytics. Materialize is source-available and free to run in a single-node configuration, and we’re building a cloud product if you’d prefer not to run it yourself.
Appendix/Further reading on CDC
I've collected some good qualitative examples of the growing CDC ecosystem around the web:
- Blogs: Shopify Engineering on CDC, CapitalOne: Batch to Real-Time with CDC, DevotedHealth: Streaming to Snowflake with CDC
- New Companies: Meroxa, Blitzz, AirByte, FiveTran
- Offerings from Cloud providers: GCP DataStream
- Open Source Tools: Debezium, maxwell, wal2json
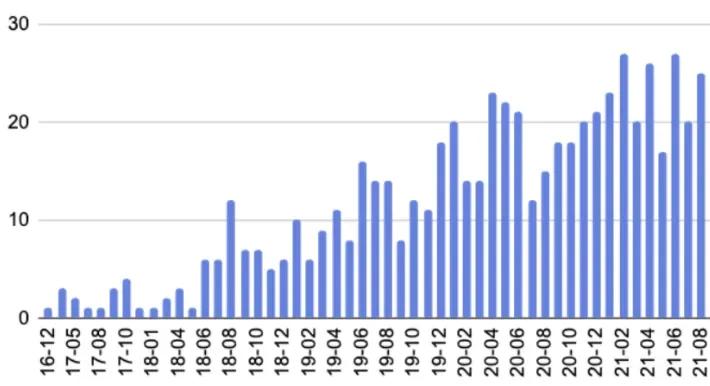
For more quantitative data points, here are question asked about Debezium on Stackoverflow over time:
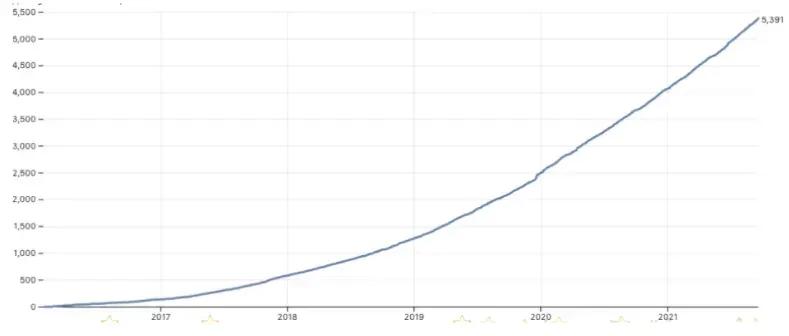
And here are Stargazers of debezium/debezium over time: