The live context layer for agents and apps
Transform siloed data into up-to-the-second context, just using SQL
Trusted by engineering leaders












Why is it so hard to keep up with demands for fresh context?

OLTP Databases
Siloed and can't handle data-intensive queries.

Data Lakehouse
Lacks the freshness and cost-efficiency required for online services.

Do-it-yourself
Complex to operate, often requiring specialized talent.
Introducing Materialize
Operate confidently with live context.

Backed by the best to bring a breakthrough in incremental computation to the enterprise.



Integrate data from any source
Continually and incrementally ingest data from your databases, ERPs, CRMs, and other systems, unify it, and clean it for downstream consumption. Materialize grows more powerful as you connect more sources. Use our secure and scalable SaaS or keep everything air gapped on prem. Materialize separates storage from compute, scaling beyond local memory giving you economical processing for your most demanding operational workloads.
Use SQL to create real-time data products
Transform raw updates into live, canonical business objects that can be queried directly or pushed to downstream systems in real-time. Use Materialize to build a trustworthy, up-to-the-second digital twin of your business that streamlines agent and microservice development. Our groundbreaking incremental computation engine performs the minimal work to keep things up to date as updates happen, without destabilizing your operational databases. Any engineer who knows SQL can now launch a new data product or contextual building block for AI in minutes.
Rapidly deploy use cases from a live context graph
Link your real-time data products into a continuously updated context graph that agents and services can query directly. Offload complex queries from your MCP endpoints and APIs onto incrementally computed data products with single-digit millisecond latency. Keep vector embeddings fresh as source data changes, enabling RAG that's so fresh it's interactive. Every application and agent stays grounded in a trustworthy, up-to-the-second view of your business.
Trusted by engineering and data teams
Support your most demanding AI initiatives with your existing team
Give agents real-time, contextual building blocks so they can discover and react to the data they need at scale. Link context with knowledge graphs so they know where to go next. Agent capabilities grow exponentially as new data products are added. Serve directly from Materialize or keep embeddings and search attributes up to date at a fraction of the cost.
Materialize seamlessly turns raw updates into semantically meaningful events. Use them to streamline microservice coordination, update downstream systems, or enable rule-based alerts.
Power demanding web and mobile experiences that correctly reflect user actions with sub-second latency.

Integrate Materialize into your existing stack
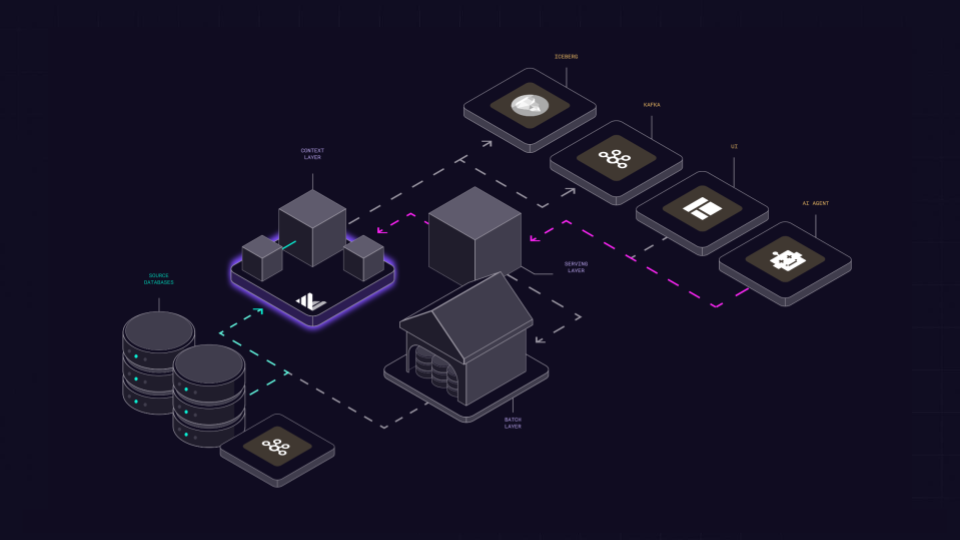
Lambda Architecture
Get a quick win by adding Materialize as a speed layer alongside your batch-based systems. This avoids the costly transformations required to keep up with live data and lets you see the impact of actions that would otherwise be too complex to calculate reactively.
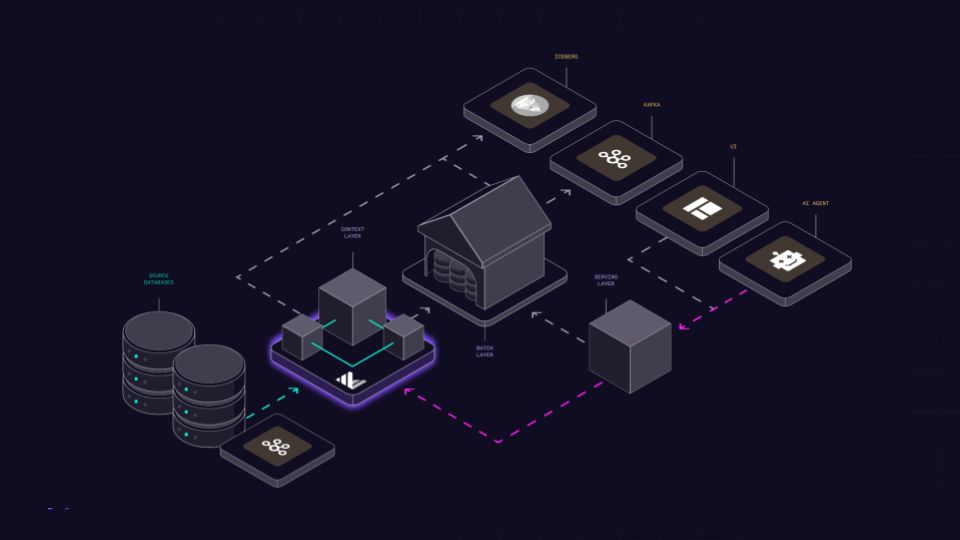
Kappa Architecture
Over time, use Materialize to create the authoritative representation of your business in the moment. Query Materialize directly while sending events downstream to power core processes or enable historical analysis.

"AI has put massive amounts of raw truth in play that we couldn't work with before. Materialize gives us a flexible platform for turning that into live context, in a way that matches how an agent would want to read it."
Read Customer Story Erik MunsonFounding Engineer, Day AI
Erik MunsonFounding Engineer, Day AI
"Our fraud losses have substantially decreased, and the infrastructure spend for this system has gone down by about 80 percent."
Read Customer Story Brandon RochonHead of Data, Neo Financial
Brandon RochonHead of Data, Neo Financial
"Loan eligibility rule calculation time decreased by 98.15%, dropping from 27 seconds to half a second."
Read Customer Story Wolf RendallDirector of Data Products, Vontive
Wolf RendallDirector of Data Products, Vontive


