CMU DB Talk: Building Materialize
June 8, 2020

This is an edited transcript and video of a talk that I gave at Carnegie Mellon’s Database Group Seminar on June 1st, 2020, hosted by Andy Pavlo. You can watch it, or read along!
Introduction and Background
important
Materialize was first developed as a single downloadable binary. Early in 2022, we decided it was time to unbundle Materialize into a distributed system to unlock the next phase of scale. If you're interested in trying Materialize for yourself, register for access here!
For our agenda today, I’m first going to talk about streaming databases, and what they are. Then I’ll cover a little bit of background on the streaming ecosystem, and timely dataflow - the dataflow engine that’s at the heart of Materialize. Finally, I’ll talk about Materialize and give you a demo of it actually in action.
What is a streaming database? What I mean by this is that instead of being optimized for ad-hoc transactional or analytical queries, it is optimized for view maintenance on an ongoing basis over streams of already processed transactions.
Let’s rewind the clock about 30-40 years and talk about what data processing was like, and then build up some intuition for why this is a thing you might even care about, or even want.
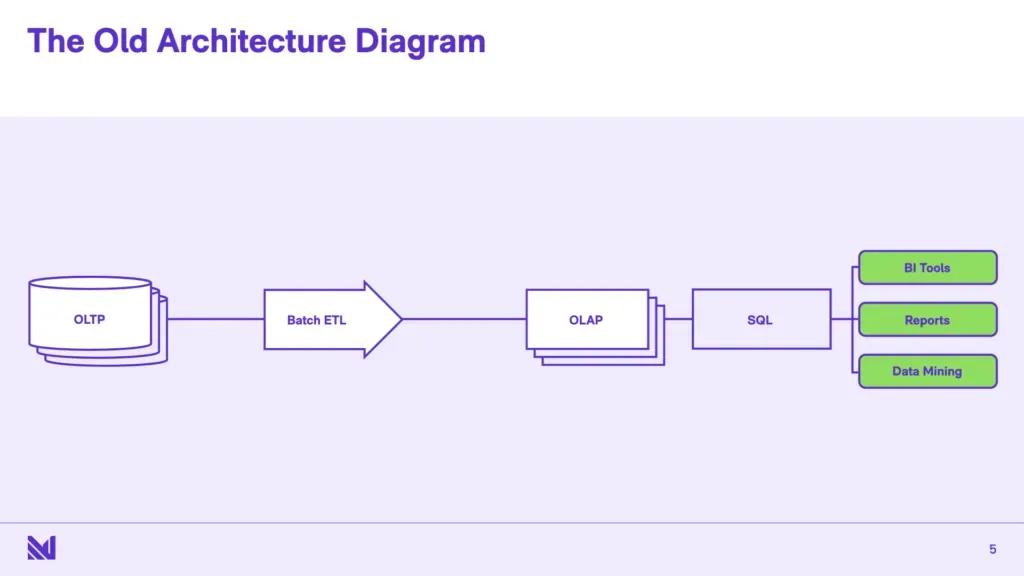
Traditionally, the world was divided into two broad categories: OLTP - Online Transactional Stores - and OLAP, or Online Analytical Stores. And of course you might have some different flavors of these, like a time series OLAP database, or a graph OLAP database or a graph OLTP database, but broadly speaking, most systems pretty much fall into one of these two categories.
They’re sort of architected very differently, right? The systems on the left - the OLTP systems - are designed for high concurrency, lots of transactions happening simultaneously, lots of writes, lots of reads, some of these grouped up into transactions that have to be atomically committed or rolled back... Meanwhile, on the right [in the OLAP systems], you don’t have writes, you don’t have concurrency, but you have other different things - so you have very complex large transactions, multi-way joins, subqueries, aggregating over large dumps of historical data. And this is sort of like a different set of constraints, a different set of things to optimize for. One could imagine that one ends up in a wildly different part of the design space when you’re looking at OLTP vs OLAP - and I’m sure that folks in this database seminar get that, and are quite familiar with it.
Running through some intuition - mostly because this is the intuition we use for benchmarking these systems, imagine you’re running an online store. So you’re taking orders, you’re keeping track of inventory, you’re shipping these orders out, this is the TPC benchmark view of the world: The OLTP systems are keeping track of live inventory, the major concerns are like, making sure you don’t sell something that you’ve run out stock of, ensuring that when you ship an order, this is reflected transactionally in the shipments table, so that if you have lots of people shipping outstanding orders, no two workers ship the same order, that sort of constraint.
On the other hand, the OLAP system allows “business analysts” to answer questions about the company as a whole. So someone at HQ, some sort of analyst is asking “are sales up this quarter?”. You might want seasonally adjusted inventory stock levels and look at it year-on-year, or ask questions like “What about North America sales versus Europe”, that sort of thing. And that sort of query requires grinding through all your data, potentially joining a bunch of tables together, things like that.
The two systems sort of end up with radically different physical layouts, execution engines, because they’re fundamentally optimizing for very different tasks. The right systems pretty much operate on static data that’s infrequently updated, they don’t really do locks or don’t really have to worry about isolation - a little bit - but not the way that OLTP systems have to. They’re optimized for really, really fast reads over lots of data. And on the other hand the OLTP systems pretty much can’t handle any large transactions - they’re designed for getting people in, getting them served, and getting them out, and never losing data, and never lying to anyone.
And in the old world, the stuff in the middle, the ETL, it’s just there to get stuff from the left to the right. ETL stands for “extract, transform, load”, and that’s exactly what’s going on. If you have two different formats because they’re optimized for two different things, to paint a broad brush - say row oriented for OLTP and column oriented for OLAP, you’re taking stuff from the format on the left, and transforming it, loading it into the format for the right.
Now the main problem with - like why should we even want to do something different from this workhorse architecture - is that OLAP systems fundamentally are working on outdated views of the world. They’re looking at day old stuff - sometimes for some companies its several days old - and even at best, it’s often hours behind. And there’s lots of useful things you might want to do that requires more recent data than a day old dataset.
They can connect directly to the OLTP system - perhaps connect to a read replica or something - and they can do up-to-date reads. Or, they have to make do with stale data.
Tf they’re trying to do up-to-date reads, they pretty much have access to the form that is optimized for those OLTP transactions, and otherwise they just have to work with old data.
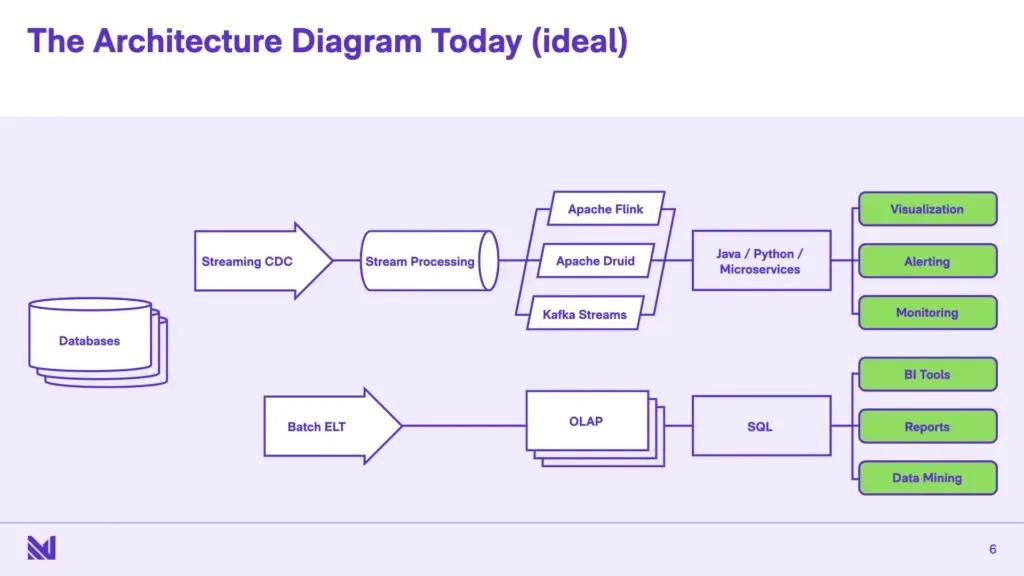
This isn’t a new problem - people recognized this even in the 1990s - and you definitely had some technologies for shipping data around from OLTP systems quickly - enterprise service buses and enterprise application integration platforms. And roughly, those systems evolved to what I would call this idealized version of the architecture today: you have, broadly speaking, two pipelines. You have a “streaming” pipeline for getting data out in real-time, and then you have a batch pipeline that’s very similar to what we had before. The streaming pipeline sends data live, whereas the batch pipeline still takes hours.
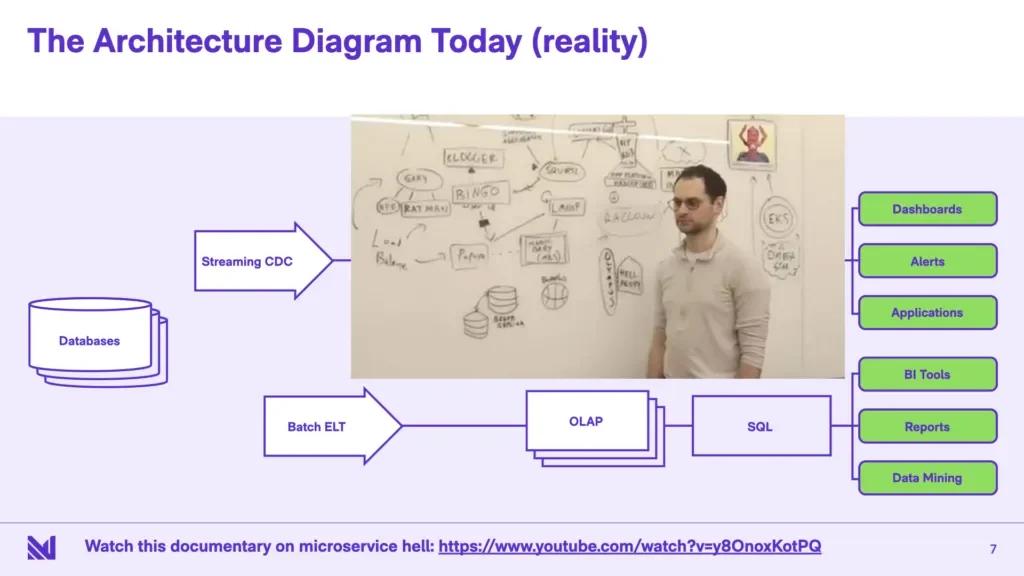
Now this is the idealized picture. So let’s look at this today. The reality is while the batch pipeline has gotten a lot better, the streaming pipeline is very, very nascent. You’re pretty much on your own for building things. The official term for this is “microservices” but I think the more technically accurate term is “the wild west”. A lot of “write your own join algorithm in application code, why don’t you do that!”, “use a NoSQL store on the side for state management, scale it up and scale it down yourself”. And these are all sort of papering over the real problem, which is that there really aren’t tools to help here.
There’s a youtube video, this is a screenshot from the video, I think it’s supposed to be a parody, but I think the more apt term for this is a documentary - it exactly captures the hellish world you get into, where you have to talk to about 14 different systems to get the state to compute the view that you’re trying to compute. And our goal is to make a lot of this a lot saner.
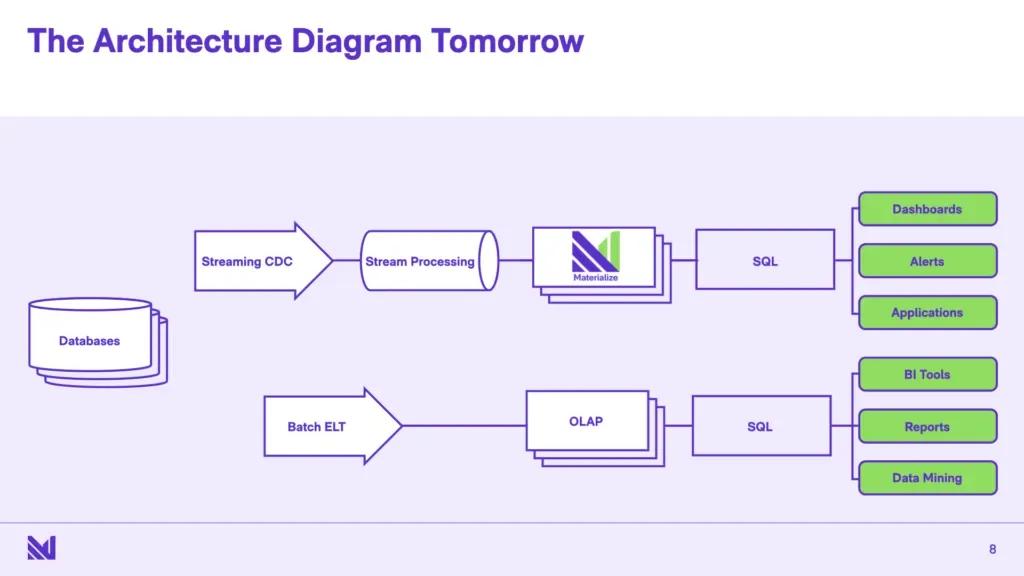
Like there’s so many of these microservices that are morally speaking - for the database audience - are just computing and keeping up to date materialized views. Not every microservice - there are certainly microservices that are doing transactional things - but many microservices are just computing materialized views over changing streams of data.
And the problem is that existing databases aren’t really architected for efficiently maintaining materialized views over rapidly changing data. And that’s exactly what Materialize is really about. It’s a database that’s just purely optimized for view maintenance. And I think this is something new - with like appropriate caveats for... When giving database talks, everything was already invented by somebody in the 80s, etc. etc. But commercially speaking, this is novel.
Again, the term “materialized view” isn’t a new one: many OLTP systems and OLAP systems often have support for materialized views. However, systems - like Materialize - that are designed for view maintenance can often handle substantially higher load for workloads that re-issue the same questions over and over again against fast changing data. I’ll get more specific about this later on in the talk, but ideally, you want to do work proportional to the amount of data that we have to keep around in the final result, rather than in proportion to the number of times the results need to be inspected. Just because a thousand people issue the same query to the same service, or the same dashboard issues the query a thousand times, we don’t have to pretend to be surprised 999 times that we’re seeing this join. We should maybe go ahead and incrementally maintain some amount of work.
What’s different about online view maintenance?

Before we get to what Materialize does, I’m going to give you some background on the streaming ecosystem, and thus, where Materialize fits in. Some disclaimers are necessary here because these are my opinions, and they are a little bit subjective. But I hope that they help give you an intuition for what I’m talking about.
First, queries are long-running. In contrast to e.g. OLAP systems, where queries are optimized by a query optimizer at execution time, streaming queries need to be optimal for approximately forever. So OLTP query systems or OLAP query systems can make a “best effort” guess at a query plan, and then collect runtime statistics, and on subsequent runs of the same query, they can switch up the plan. If you’re issuing 1000 queries, you can replan 1000 times. But in a OLVM - online view maintenance - system, once you create a view, it’s pretty much that replanning involves shutting down that view and restarting it from scratch, so this means that query planning is a lot higher stakes of a game. And second, query planning is itself a lot harder - because existing query planners - in say OLTP systems - will maintain an evaluation context, and often times bail and just use that context to recursively rerun, say a subquery. You just don’t have that option in a dataflow engine that needs to statically have a query plan totally planned out physically from the beginning. This also means that error handling is a lot more difficult: the show must always go on! Like you just have to find some way to keep making forward progress.
Second, this also means that there are no table statistics. Most of the query optimization literature in OLAP systems is totally oriented around the idea of getting really really good cardinality estimates of your tables, and using that to choose the perfect query plan. Streaming is a little bit like entering the matrix. So you can’t think about picking the perfect join ordering based on all your perfect cardinality estimates. You first have to realize that there is no perfect join ordering. You have to do all the joins at once, and be very robust to individual streams changing, you know, wildly swinging the number of events per second. Maybe joining a slow moving stream against a fast moving stream, and all of a sudden the slow moving stream is also a fast moving stream.
Andy: With a streaming workload, isn’t it often times like, say, there’s the fact table, and there’s the dimension tables. The dimension tables would be static. And in that case, you do know something about the dimension tables, so you could have some statistics. Or are you saying that in Materialize, like there are no fixed static tables.
Arjun: So one challenge here is that in a traditional OLAP context, you’ll have that. But in streaming, oftentimes people will do things like they will reissue the dimension tables, because they have become outdated. So you’ll suddenly see a whole lot of changes in your dimension stream, because they just got batch-ETL updated. And this can be catastrophic for some classes of query plans, that can end up quadratic if the table they assumed was not changing at all, suddenly changed. Now an OLAP warehouse wouldn’t care, because you’d throw everything away and replan everything [with the new cardinalities]. But in the streaming world, things that “don’t change” can occasionally change in ways that could be catastrophic to your query plan.
Andy: Is this a common? I can see people doing stupid things, but is that common enough? Like drop the whole dimension table and load it back in rather than doing an incremental update?
Arjun: Yeah, unfortunately, it is common. Sometimes it’s not even your fault - like its an upstream system’s fault - that’s doing a daily batch dump. What do you do if someone’s issuing a backup and reissuing [the dimension table]?
Again, this isn’t a lost cause - it’s just a set of constraints you have to optimize for. Obviously, some things are easier here. For instance, the writes are all ordered for us by the stream processor. Just like in OLAP systems, there’s no real concurrency control that we have to do. The events are pre-ordered for us, and our task is more to just be able to keep up with those events as they happen at very high data volumes, rather than do tricky admission control and locking, maintain serializable histories, etc.
And finally, we’re totally going to restrict ourselves to query patterns that are relatively well known. I say relatively well known and mostly repeated, because we do want to be able to do ad-hoc queries, what I do want to say is that an OLAP warehouse will probably beat us on truly ad-hoc query workloads on fixed, batch data. But you still want to leave some room for ad-hoc queries within similar patterns - like think queries that can reuse the same indexes and things like that.
What do we want from Streaming?

Now this is where - no holds barred - these are my opinions. Some of these folks may not agree with!
First, people want SQL. Writing streaming applications should be as easy as writing a CRUD app. You just write declarative queries for what you want, and you should get it. Writing imperative code should be a last resort. And when I say SQL, I really mean actual SQL - like the horrendous stuff - like the stuff that’s buried under the dark corners: 8-way joins, the GROUP BYs with HAVING clauses, the subqueries, correlated and uncorrelated, and all that. And hopefully I’m speaking to fellow cult members in this talk, but I bring this up because a lot of existing streaming engines don’t really support SQL. Without full support for joins, without support for arbitrarily non-windowed join conditions, it’s not really SQL.
Second, as a manifesto, If there’s no change, don’t do anything. This seems like something somewhat obvious to state, but existing stream processors have these massive hardware footprints even when sending relatively low amounts of data around, just because the queries are very complex. To rephrase this a bit, it should behave like postgres on your laptop. I’m running postgres on my laptop right now! I’m not issuing any queries against it, it just sits there quietly. Stream processors should also behave this way.
Third, Joins are absolutely crucial, and windowing joins should not be mandatory. A little bit about this: existing streaming frameworks mostly require that streaming joins be windowed along a temporal dimension. What this means is that, concretely, if you have input streams that are changing over time, the join condition is only evaluated over some fixed window of data. If you have two input streams, if you have input A and input B, and each stream gets new inputs over time (ΔA and ΔB), and we’re joining these two streams together, the join is only evaluated on some window [a subset of the streams]. And the window moves. Like a JOIN means that any event [from stream A] can match with anything [from Stream B].
Andy: do you support the Streaming SQL semantics? Like the sliding windows, the tumbling windows, or…?
Arjun: We intend to. We don’t consider that hard. The hard part is supporting joins that aren’t windowed. The joins that are over the entire [history of the stream]. Frankly, windows can be mostly expressed… just express your join condition declaratively over your streams, and if… if it’s possible for us [in Materialize] to only keep some subset of the state, leave that to us. We’ll take care of that. You just declaratively say what you want.
Andy: Absolutely. I always wondered… reasoning about the window types… I don’t think most people can do that. Having that be declarative is awesome.
Arjun: And fundamentally, existing systems force you to do that, because they are not capable of dealing with unwindowed joins. It’s a little bit of a sleight of hand where they say “hey! You can window your joins!” I didn’t ask if I can… I want to not do that.
Andy: Do you want to name names?
Arjun: No.
If you’re shocked as a database audience, I want to be clear that this mandatory windowing is unacceptable, and means you don’t really support joins. There are lots of useful streaming computations where the data changes slowly, or infrequently. To give you one example, consider a fraud detection algorithm for a credit card processor. It might join a few inputs: say a firehose stream of the geocodes of payments happening on the network, with your user-data.
But consider when you change your address: you probably do this basically never. But when you do, it should instantly be reflected in the computation, so that it doesn’t start issuing false positives! But also it can’t forget your address if your address moves “out of the temporal window” because you didn’t change it recently! We should expect more. While the system itself should only maintain the minimum footprint (e.g. if the query allows it, only remembering your last address, garbage collecting prior addresses, etc.), figuring this out should be on the system, not the user.
Materialize: Architecture
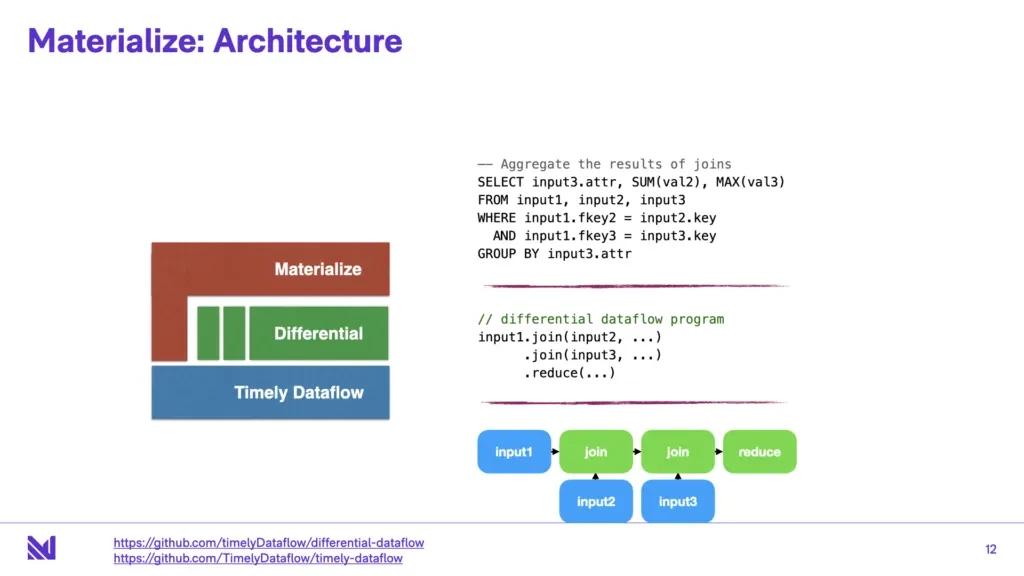
Alright, let’s get to Materialize. So now that we’ve got a little bit of the religion out of the way, let’s talk about how we deliver on these desiderata. Materialize is built on top of two projects, timely and differential dataflow.
The way to think about this layered architecture is that timely dataflow is the streaming compute engine at the heart of Materialize. It’s a scale-out stateful, cyclic dataflow engine. It allows folks to write arbitrary rust code as “operators”, and these operators run as part of dataflows in a scale-out cooperatively-scheduled fashion in a large cluster . More on this later, but for now just remember that these operators can be arbitrary programs that maintain arbitrary state, and pass messages between each other. The only interesting thing about these operators is that along with input data, they are also fed timestamps, and these operators need to “relinquish” the capability to emit outputs at times for the system as a whole to make progress. You can think of an operator as getting inputs at t1, t2, t3, and at some point the operator makes a statement, here’s some output, I’m done with t2. Any output I send will occur at times t3 or greater.
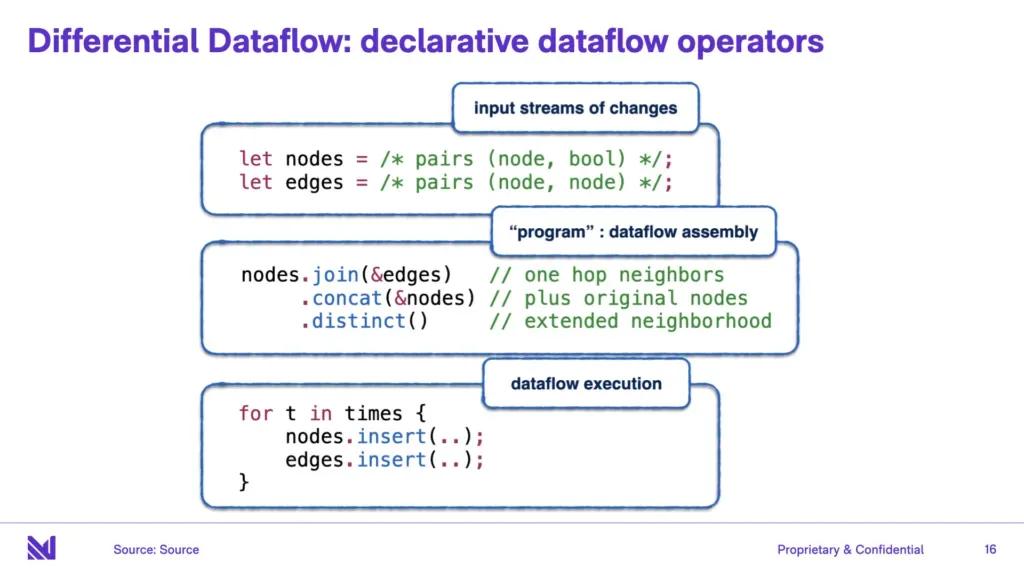
On top of that is differential dataflow. Now timely isn’t opinionated about operators, but differential is a very opinionated set of operators. Now just because timely lets you write arbitrary operators, doesn’t mean you should. Different operators should be familiar to the audience here: they mostly look like “join”, “aggregate”, “filter”, “map”, and things like that. Care is taken to build minimal, tasteful operators. And one additional operator that will not be familiar to the audience here is called “arrange”. You can think of this as like an “index building” operator that takes care of efficient state management for any other operator that wants it to. It’s kind of the workhorse operator in differential dataflow, because a lot of other operators, for instance join - it has to build large stateful indexes in order to deal with large historical windows of data that it has to evaluate join conditions over.
And finally, at the top, we have Materialize. Materialize is probably the thing that looks the most familiar to this audience - it does things like handling client connections, maintaining a catalog of streams and views, it does parsing, planning, and optimizing input queries and constructing these dataflow plans from these input queries, etc. It definitely has to do some things very differently than the more familiar traditional databases - constructing dataflow plans is a little bit different from constructing Volcano plans, but it’s close enough.
Andy: Does your stream require you to have punctuations, or the guaranteed delivery of timestamps at fixed intervals? E.g. messages that may not have data in it, but they guarantee the boundary of a window.
Arjun: So you mean you have an event at a time T1, and you have a punctuation that say’s “you have now seen everything up to T1”? Yes, you need your inputs to tell you when they are done issuing you inputs at a given timestamp. And if they don’t give you that, you can make assumptions, but you may have to go back on your word, and you won’t have correct answers. So the presence of punctuation is necessary for strong isolation guarantees. If you have change data capture from an OLTP system, and those messages have transaction IDs (e.g. MySQL GTIDs), then everything is going to be fine. But sometimes, as we’ve discovered, existing middleware throws those punctuations out.
Traditional Streaming Systems
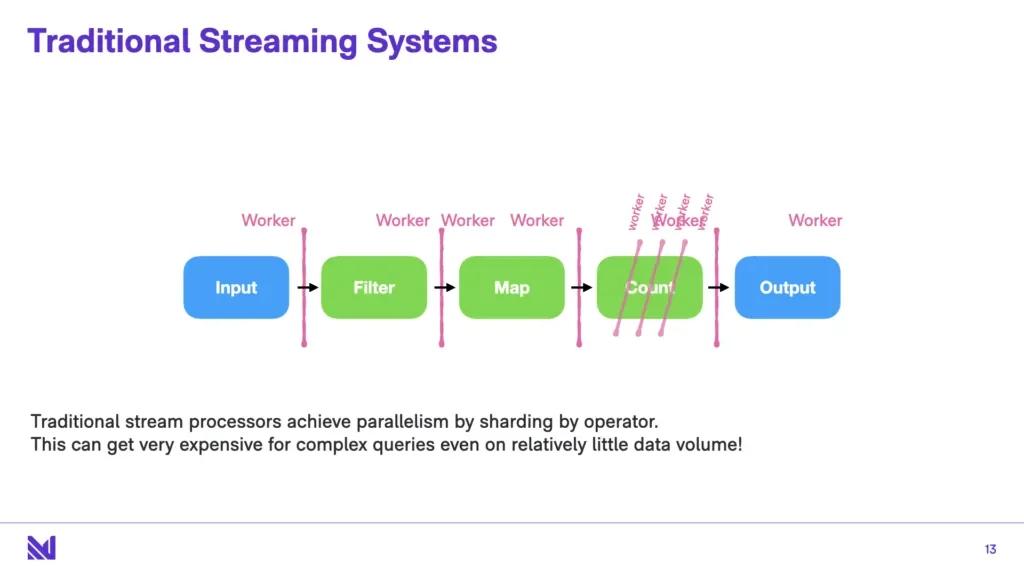
To understand Timely dataflow, let’s talk about traditional streaming systems. The way they mostly work is they take their dataflow operators and they partition one dataflow operator per worker (by worker I mean a compute core - a physical CPU). And this can get very expensive for complex queries, even on relatively low data volumes. This way of sending data around can often mean that relatively small amounts of data - just passing no-ops through the system till it comes out the other side - if you have a complex dataflow graph, that’s a lot of busywork for relatively little change.
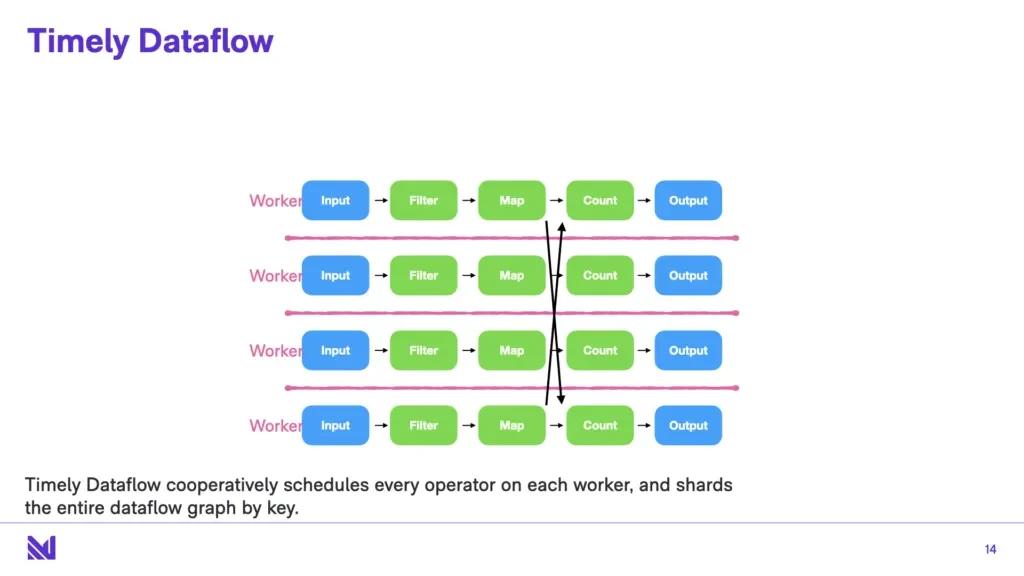
In contrast, timely dataflow cooperatively schedules every operator on every worker, and shards the entire dataflow graph by key. It scales down. The interesting part here isn’t that it scales up - it totally scales up at very large query volumes. But what it also does is it scales down - you can have a single core version of timely dataflow that - if some of you are familiar with Frank’s COST paper - outperforms other big data systems that are given arbitrarily large number of compute nodes.
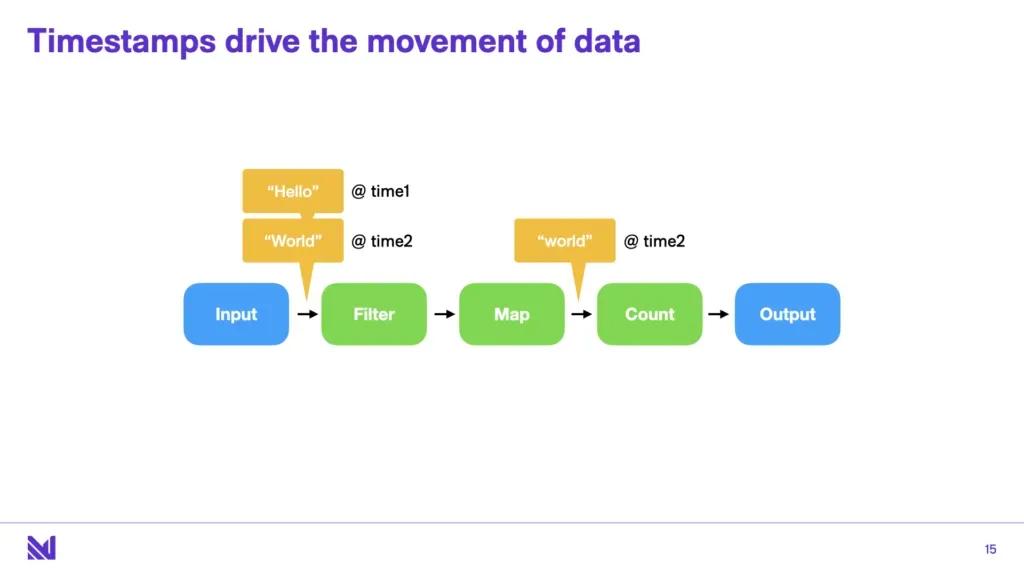
Now the other principle in timely dataflow is the timestamps drive the movement of data. All data items are sent through an operator with attached timestamps, and the operators can emit data at that timestamp, or can also say “I’m done with this timestamp” and relinquish the right to ever emit outputs.
Andy: And there’s no corrections a minute later - you can’t come back a minute later and say “here’s the correct value for it”?
[Editor’s note: this is a place where my answer in the talk was incomplete and confused; this is an expanded post-hoc answer that is not in the talk video]
Essentially, the answer is that you need these “done” messages to drive the computations. However, there are a few advances in timely dataflow that mean that users can, in practice, send “corrections”. Users are not limited by needing to guarantee data arrival within a specific time window, because timely dataflow is capable of reasoning multitemporally. What this means is that we can have two different notions of time simultaneously, e.g. decoupling system time from event time. Queries can then be asked that incorporate both notions of time, which can move independently. You can think of this as wholly subsuming streaming notions like “late arriving data” into the declarative SQL paradigm - users can say “at time (1,2) the value of K was V1”. Later on, they can say “at time (2,2) the value of K was V2”. To our knowledge, multitemporal reasoning so far has only been really available in financial systems like kdb+. Right now, driving multitemporality is fully present in timely dataflow, but is not present in Materialize as we’re still figuring out the SQL syntax that is most elegant here for both SELECT queries and views. Please join the conversation in this issue!
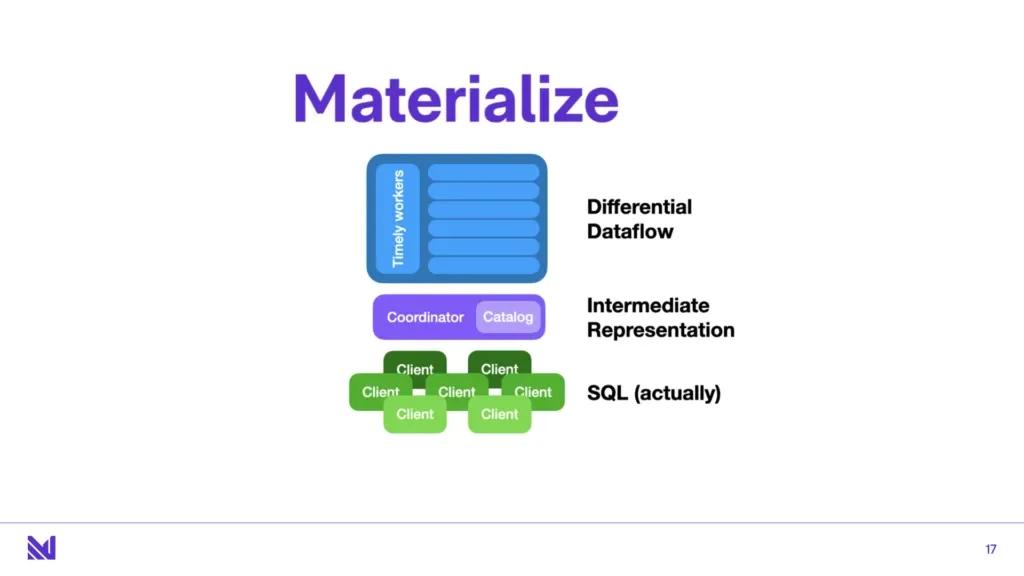
On top of Differential Dataflow, Materialize builds the parsing, planning, the execution that we all know and love. The catalog, a coordinator to coordinate dataflows being installed and uninstalled, etc.
Building Materialize: Experience
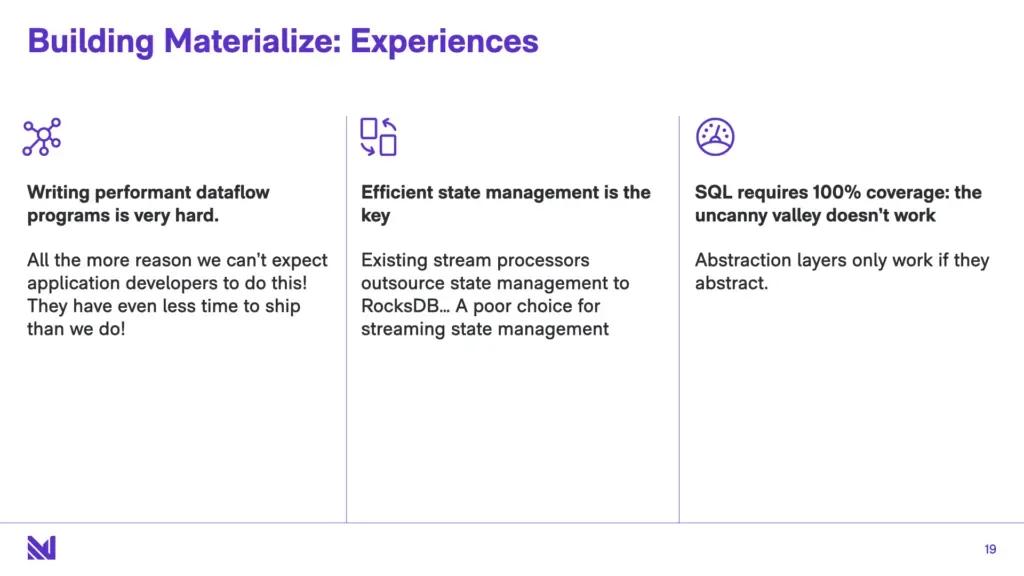
So let’s talk about how it’s been writing Materialize. First, writing performant dataflow programs is very hard. This experience has only taught us more that we can’t expect application developers to actually do this in their day-to-day. They have even less time to ship than we do!
Second, the workhorse of differential dataflow is the arrange operator, which does efficient incremental index maintenance. Most other stateful dataflow systems (Flink, Kafka Streams) they outsource this state management to a sidecar instance of RocksDB per operator, which accompanies each operator.
Look, I love RocksDB. But RocksDB is a poor choice as operator state manager for streaming systems because it is optimized for objectives like durability, atomicity, high read concurrency which are totally orthogonal to the needs of a stream processor. Phrased in another way, like RocksDB has additional compaction threads to maintain its log-structured merge tree. But efficiently compacting state is primarily the computational task required of all dataflow systems. The choice of when to schedule compaction is the task - probably the most important [and data intensive] task that must be considered alongside all other operators, and has to be fused in with the other operators that you are scheduling in your cooperatively scheduled dataflow system.
Andy: So is RocksDB a bad choice because it’s an LSM, or it’s a full-fledged storage manager that’s meant for other purposes?
Arjun: The latter. So the arrange operator also maintains an LSM under the hood. The problem is that most other streaming systems have punted on when to do compaction by outsourcing it to a full-fledged storage manager that was built from the ground up to be the storage manager for an OLTP system. When really, this is the hardest part of building a stream processor, and you have to be very intentional about what you compact and when.
In other words, consider compaction to be another operator that must be fused for maximal efficiency --- if anything, it is the most data intensive operator in the dataflow graph, and the one that benefits from operator fusion the most.
And finally, one of the things we’ve really come to believe in is that SQL really requires 100% coverage. SQL, “inspired by SQL”, “almost SQL”, “SQL except the joins”, like that really doesn’t work for the users, because good abstraction layers only work if you can forget - to some extent - what’s under the hood. If you have to mentally think “what is the underlying implementation going to do”, and at that point the abstraction layer just gets in your way. When I write a C program, I don’t really think about how many x86 instructions will happen under the hood - unless I’m all the way off the deep end writing really really high performance code. Most programmers are able to live at the higher abstraction layer.
And we’ve put a lot of effort into getting very, very close to SQL fidelity. And of course, there’s a few instances where it’s apples to oranges; the streaming setting is not the OLTP setting, where you do have to make some changes and you can’t have full functionality, but those have to be the very minor exceptions.
Andy: Can you give an example?
Arjun: Window functions. Because inserting a change can affect an entire window, and change the position of so many different rows, that you end up… it’s just better for the user to not think that way, and when they can replace window functions with some other form of writing their query, they are better off doing that, rather than us trying to optimize away the massive amount of internal changes that have to be shuttled through the system.
Andy: Let’s be honest here. The SQL standard is… six books. Nobody has 100% coverage. What’s the bare minimum you support?
Arjun: Joins, subqueries, …
Andy: CTEs?
Arjun: We don’t support CTEs yet, but we absolutely plan to, and we should. Like… these things are necessary to port most of the education and expertise that people have built up dealing with SQL.
Demo
[Editor’s note: And now we jump to a demo, which really comes through better in the video, so please hop in at time 37
30
if you can! You can download and play with Materialize with just a few short commands on your laptop!]
Let’s take a look at what Materialize looks like! So first off, Materialize today pretends to be Postgres. This is sort of an opinionated choice, because we love Postgres, and a lot of existing tooling runs on top of Postgres.
Now to give you a little bit of context before we jump in, I’m going to set up a demo that’s running a MySQL instance upstream, that is running the TPC-C benchmark. Now, as I hinted to this scenario earlier, the TPC-C benchmark simulates an online store where orders are happening all the time, on upstream “warehouses” [don’t confuse this with data warehouse; think physical warehouse where stuff is kept!]. Orders are being taken, orders are being shipped, and all of these things are happening transactionally. And all of these transactions that actually commit, are being flowed through Kafka [via Debezium], and into Materialize. Kafka is a stream processor, and is just sending us all of this, one stream per [database] table, as it’s being modified. So there’s a customer table, a district table, an item table, and so on. And we are going to materialize some views over these tables.
For folks who are familiar with OLAP benchmarking, we’re going to materialize TPC-H queries. Now we are not yet at 100% coverage, but we’ve installed a subset of them as materialized views, which are being incrementally maintained. Now when we say incrementally maintained, they are being actually materialized as the underlying data is changing, with every update. They views are fully queryable, and are live. If you just do a SELECT * FROM q01, you are getting exactly the query as TPC-H query 1, up to date as of this second.
[Editor’s note: of the 22 TPC-H queries, we currently support 17 with efficient plans. Of the remaining 5 queries, 4 are unsupported due to the presence of inequality joins in the join condition (which are not currently supported in any form), and one is the result of poor optimization for common subexpression elimination resulting in a cross-join where we should do better.]
Andy: Your SHOW VIEW / SHOW TABLE is throwing me for a loop, because that’s MySQL syntax [and you said you implemented Postgres syntax].
Arjun: We support both the MySQL syntax and the Postgres syntax for these things where it’s just quality of life, people type “SHOW” without thinking. No need to make them type "\d", just add support for both in the parser. So it’s more Postgres++, just quality of life improvements.
So you can create views downstream of the existing materialized views. So instead of computing the SUM every time, you can create a materialized view for that, chained to the materialized view of q01. As you can see, when we do that, the speed at which the result is returned is much much faster.
So for those of you who aren’t as familiar with the TPC-H queries, they’re a little bit adversarially designed - there’s six-way joins, there’s eight-way joins, there’s correlated subqueries that you really can’t efficiently execute unless you perform decorrelation, things like that.
Andy: Can you run EXPLAIN? Would it work and show you the plan?
Arjun: So, EXPLAIN works. explain would show you the dataflow that we run, and there’s multiple different flavors of explain (just like in postgres). It’s not apples to apples to postgres, [as dataflows are very different beasts than volcano style plans!], because it’s not doing the same thing under the hood.
One thing I want to call out is that when you select any result, you can also select the internal timestamp at which this query was executed. Like I mentioned before, we are flowing timestamps through the system alongside every piece of data. And when you select a query, you are getting that query executed at a single timestamp across that entire query. This is important, because you are getting snapshot isolation consistency guarantees, as the underlying views are being updated. Every row, is coming at exactly the same timestamp.
Now we added this other thing which isn’t standard SQL, but which we think is really cool, called TAIL. What TAIL does is you can run SELECT * and get the result for a view, and then press up, enter, up, enter, but you can also use TAIL to ask Materialize to flow you the diffs, as they happen.
important
Note: Since publication of this article, the query subscription primitive has been renamed from TAIL to SUBSCRIBE. See SUBSCRIBE to changes in a query docs for more info.
Do you support SUBSCRIBE/NOTIFY?
Arjun: That’s on the roadmap. We don’t support that right now, but that’s an obvious one to add in support for.
Andy: Do people ask for it? There’s enough people actually using that functionality in Postgres, today?
Arjun: Yes. People love that.
The final thing that I want to call out is that we have these internal logging views, that we keep running alongside your views. These allow you to introspect, e.g., how many records are in the view. And some views can be large - query 5 has a lot of intermediate state - but take a look at query 6: it only has 229 records. The memory footprint of maintaining incrementally updateable views can be quite small. Here, all of this is running on a single node, it’s totally feasible to run this. There is a blog you should check out, that talks about how this memory footprint can be surprisingly small. Incrementally updating can be proportional to the size of the output.
Andy: Is there a buffer pool, so you’re able to write things out to disk and swap pages in and out? Or does everything have to fit in memory?
Arjun: Materialize just uses swap to page out to disk. It comfortably buffers out to disk with a clean performance profile - we’ve tested to hundreds of gigabytes.
Andy: You’re using mmap?
Arjun: We’re literally just allocating memory and configuring swap to allow us to use the entire disk.
Andy: How many writer threads do you support? Is it a single writer thread?
Arjun: No! So one thing that’s super interesting with Materialize is that each worker thread [i.e. each core] of timely dataflow maintains its own sharded state. So if you’re running this on 16 threads [or 1024 threads in a cluster!], each one of those 16 threads is maintaining it’s own state, and they’re message passing state.
Andy: That’s why you can do mmap.
Arjun: Yes.
Selected Questions and Answers
Sai: I’m a PhD student at the University of Buffalo, my main is: does differential dataflow use the worst-case optimal join algorithm?
Arjun: We do not currently use the worst-case optimal join - if you’re referring to a specific worst-case optimal join algorithm, we do not - but we do use multi-way joins of a different flavor. There’s some content that explains precisely what we do and what we don’t do [ed: linked above].
Andy: Most systems don’t do multiway join stuff, so anything you have is probably better than what’s out there.
Constantinos Costa: I’m from the University of Pittsburgh. What is the idea of consistency in your system?
Arjun: Consistency wise, we compute correct answers based on the timestamps you give us. So all answers are exactly as of a single timestamp, if the inputs you’re giving us have timestamps attached to them [ed: as is the case with CDC data with in-stream transaction IDs, for example], then we can give you exactly correct answers, essentially snapshot isolation. I don’t believe we can claim anything strong [e.g. serializability] since we don’t do any concurrency and the inputs are being ordered for us. [Editor's note: for a longer discussion, please see this blog post on streaming consistency].
Andy: So you have the timely dataflow stuff. But above the core execution engine, so in terms of the catalog, the parser, the planner, the optimizer, what aspect of the implementation surprised you the most, in terms of being the most difficult, because of the materialized view environment. So this is your second rodeo doing this, because you did this at Cockroach, and now you’re doing this again.
Arjun: So we definitely benefited from that experience - so one of the reasons we were very confident we could do this, is because of our team, 5 of us were at Cockroach Labs at one point or another, so we had a very good sense of the scope of the problem [for mimicking Postgres]. What was really challenging, and I hinted at this earlier, is that query planning is a lot harder in this setting. Because you really, really have to do everything possible to get out a static dataflow graph. And at least at Cockroach, and in Postgres, oftentimes they use an escape hatch, where you get as far as you can, but eventually you bail and call back and recursively push a new transaction through with the remainder of your plan, e.g. with a subquery or something. And that escape hatch becomes really useful for these really gnarly queries. And we just don’t have that escape hatch, because everything has to be perfectly, completely unrolled to the final form before the execution can start.
Andy: Are you basically saying that if you have a subquery, you can decorrelate it, you can flatten it. You always have to do that? Like with Postgres, it can try, but if it can’t do it, it does the stupid thing and executes it for every tuple.
Arjun: Exactly. We can never do that. And that’s the hardest part. Turns out everything can be flattened, but you have to go down some fairly dark corners and beat up the query plan.
Andy: So the Materialize optimizer is written from scratch? Is it top down, or is it bottom up?
Arjun: Yes, from scratch. It’s both simultaneously. [Editor’s note: bottom-up vs. top-down usually refers to which direction drives the generation of alternative plans. Bottom-up being like, children tell their parent "here's what I have", and top-down being parents tell their children "here's what I need". In Materialize’s optimizer, information flows in both directions.]. It’s a little bit ad-hoc.
Andy: So it’s not cost-based, it’s heuristics.
Arjun: Yes.
Andy: There are some decisions you can make where costing would help. But it sounds like you’re doing what Oracle did for 20 years. You’re the new Oracle.
Arjun: Currently we optimize for the worst-case memory footprint. It’s definitely the case that memory footprint is the bigger concern, and where we can trade off doing more computation to keep our memory footprint sane, we do that.
