The New Agentic Data Architecture: A Live Operational Data Mesh

Companies are using yesterday’s data infrastructure to build today’s AI agents and applications. They are also wondering why their AI initiatives are failing
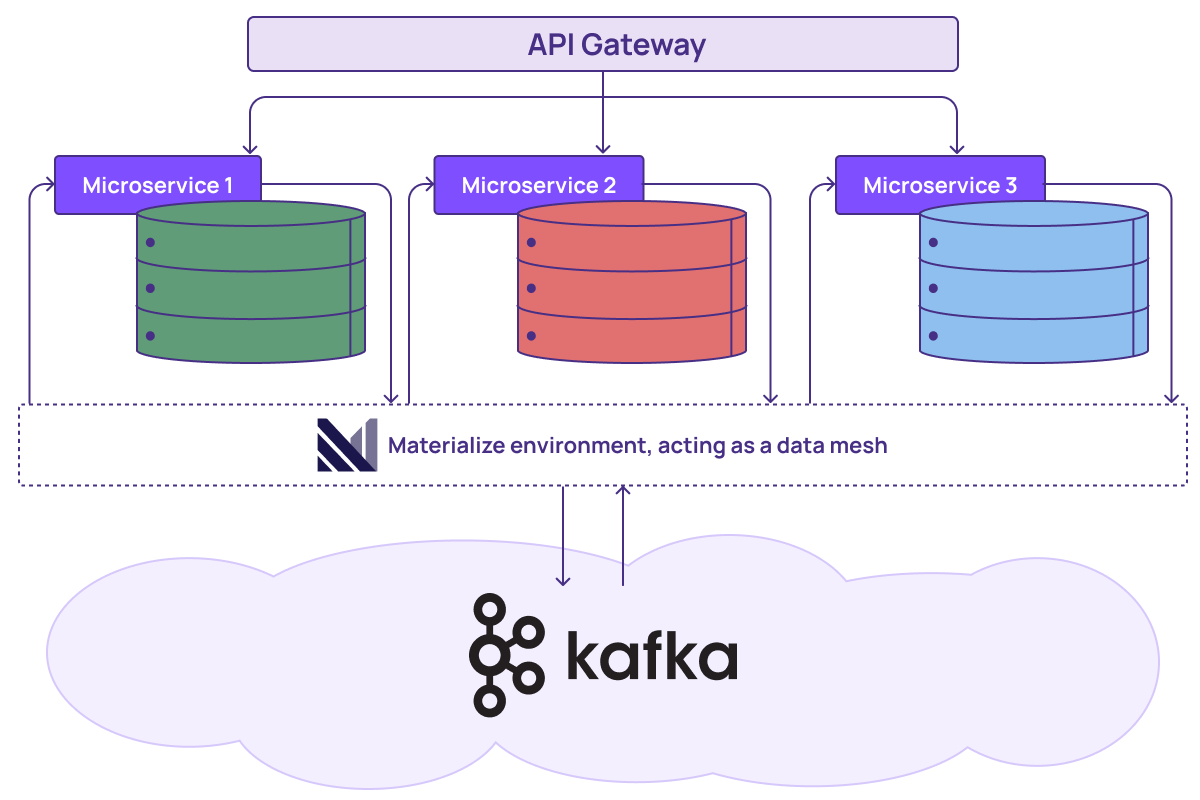
This is because AI systems, especially agents, can’t make good decisions using yesterday’s data. Or even today’s data from 5 minutes ago that simply no longer matches current reality. They need fresh, accurate context and they need it fast, which means they need a new breed of AI-native data infrastructure: live data products in an operational data mesh architecture. At the highest level, live data products give an agent trustworthy, pre-computed context without requiring expensive joins or lookups at inference time. They are combined, stacked, and shared as components in a composable data mesh architecture where downstream products automatically stay in sync as upstream data changes. Together they form a live data layer that sits between your raw operational data (databases, event streams, Kafka topics) and the agents, APIs, and vector databases that consume it. This live data layer to create an operational data mesh.
Let’s dig more into the components of this new agentic data architecture to see how it all works. Then we’ll demonstrate how Materialize fits into most traditional data infrastructures to align these systems with AI’s data needs without tearing anything down.
What is a data product?
A data product is a self-contained, reusable unit of data that's been shaped by business logic and is ready for consumption by other teams, applications, or services. The term “data product” is not new to AI and its meaning remains the same; what changes is how they are used in AI systems.
Traditional batch-based vs. live data products
Live data products are the building blocks of a composable data architecture: each one is a self-contained, reusable module with a clear contract that other products and applications can build on top of to create a composable data architecture.
Similar to an API, a data product has a clear schema and a defined purpose that specifies what exactly that data product will deliver to any downstream consumer like an AI agent, a microservice, or a dashboard. A customer segmentation data product, for example, might combine purchase history, engagement metrics, and support interactions into a single queryable asset.
Most data teams today, however, are still working with traditional batch-based data products. These batches run periodically (overnight, hourly, or other set interval) and the result is a static snapshot of a dynamic system. But downstream consumers, particularly AI agents and applications, make decisions based on what the data product tells them. If the data is stale, decisions are stale.
Live data products, on the other hand, stay continuously up to date as source data changes, producing a reliably real-time view of current reality.
Building composable data architectures with data products
In a composable data architecture approach, data products can be layered and combined to suit the needs of any data consumer, but a composable architecture is only as fresh as its least-fresh component.
Unlike the batch-refreshed approach, live, continuously updated data products can be layered and combined without data staleness cascading through the stack, making data architectures composed from live data products the ideal foundation for an operational data mesh.
What is an operational data mesh?
An operational data mesh is a pattern where teams create live data products that others can discover, reuse, and build upon. Data products can depend on other data products, forming chains where downstream products automatically stay in sync as upstream data changes. This composability is what makes it a "mesh" rather than just a collection of independent views. An operational data mesh is focused on the read side. It’s not trying to be a transactional database or an application platform, but rather the layer that makes operational data composable and consumable.
Attempting the operational data mesh pattern in a traditional batch-based system, though, multiplies computational cost because you’re constantly re-running batch pipelines to keep your data products fresh. Now multiply that cost times multiple data product components, possibly across different teams, each with its own data needs and requirements. An operational data mesh based on live data products, though, sits between your operational systems (databases, event streams, Kafka topics) and the applications and AI agents that need to consume that data.
Note: “Operational" distinguishes this from analytical data meshes that serve BI and reporting. The use cases differ enormously: operational data meshes are for applications and agents that need fresh, correct data to make live decisions. Analytical data meshes typically serve users running queries against a warehouse where slightly stale data is acceptable.
Deploying the live operational data mesh
As the heart of this new agentic data architecture, Materialize lets you build and deploy an operational data mesh using views as live data products. You can:
- Connect data sources to Materialize (Kafka, databases, webhooks, etc.)
- Create views that join and transform data across sources. For example, a Customer view that combines CRM data, transaction history, and support tickets.
- Publish views as governed data products with access controls and documentation. Other teams can discover and use them, including AI agents over MCP.
- Build new data products on top of existing ones. Materialize guarantees strong consistency, meaning all views and data products are aligned to the same point in time, so you can safely compose them.
For example, instead of five different teams each writing their own queries against raw data (and potentially getting different answers), you define one customer_entitlements_live data product in Materialize, and your UIs, APIs, microservices, and AI agents all consume it as a single source of truth. Materialize moves the expensive transformation work from query time (or batch time) to a continuous, incremental process that ensures your data products always reflect current reality. This is truly operational for technical teams because they can define each data product in SQL and incrementally maintain the results. Imagine, for example, you’re building an AI agent to optimize delivery routes based on three sources of information: the inventory data product that tracks stock levels, the routing data product that monitors live traffic, and the delivery agent combining these data products both to decide the optimal delivery route. Without that unified view, you end up writing complex logic in your application code to poll these systems, reconcile differences, and ensure everything is up-to-date.
Operational data mesh benefits for the business
- Reduced engineering labor and faster delivery. Without an operational data mesh, every team that needs cross-domain data has to build and maintain their own integration logic. The payments team writes their version of "active subscriber," the support team writes theirs, the AI team writes a third. With Materialize, you define it once in SQL and everyone reads from it. New features that need that data just compose on top of what exists rather than rebuilding from scratch. Teams ship faster because they're not re-solving solved problems.
This pattern plays out clearly for famtech startup Nanit, which used Materialize to create a centralized, always-current view of customer subscriptions for their new AI video feature without refactoring their microservices architecture.
- Lower infrastructure costs. Materialize's incremental computation model means you're not re-running expensive transformations every time something changes. You're updating only the affected rows. We've seen customers like Neo Financial report 80% reductions in infrastructure costs compared to their previous architectures.
- Operational simplicity. The hidden cost of most live architectures is complexity, including cache invalidation strategies, coordination between services, and debugging why numbers don't tie out between systems. An operational data mesh collapses that complexity. There's one place where business logic lives, one place to change it, and strong consistency guarantees that teams are never scrambling to figure out why the dashboard says one thing and the API says another.
- Faster, better processes. The fintech company Vontive compressed loan eligibility calculations from 27 seconds to half a second, a capability that simply wasn't possible before. Using the data mesh pattern, your AI agents or applications have a fresh, pre-computed context instantly — now you can build experiences you couldn't otherwise afford (latency-wise or cost-wise) to deliver.
- Greater team autonomy. In most organizations, cross-team data dependencies require meetings, tickets, and negotiation. "Can you add this field? Can you change that logic? When will your pipeline run?" With an operational data mesh teams can publish data products, other teams can consume them, and the contract handles the interface. And when those consumers happen to be AI agents and applications they are guaranteed live, accurate data.
Why "live" matters now more than ever
The rise of AI agents demands a new data architecture: Agents need fresh, accurate context to make good decisions, and they need it faster than traditional data systems can give it to them. A live operational data mesh with Materialize gives an agent trustworthy, pre-computed context without requiring expensive joins or lookups at inference time. Materialize’s live data layer sits between your raw operational data and the consumers (including vector databases) that need it… Without reinventing your entire data system.