AI Agents Need Digital Twins

AI agents aren’t read-only—they act, by definition. And even an agent’s tiniest action can trigger a butterfly effect inside your organization. A seemingly innocuous refund ripples outward to adjust inventory counts, loyalty balances, and cash-flow projections; a tweak to a delivery route reshapes costs and delivery promises. If an agent must wait minutes—or hours—for ETL processes to run in order to see these effects, it idles instead of doing useful work that moves your team forward. If it doesn’t wait for the results to be reflected, it will plow ahead, working with a stale or even contradictory worldview, resulting in compounding errors that turn small discrepancies into catastrophic failures.
Real-time digital twins for agents
What agents need instead is a real-time digital twin: an exact, always-current model of relevant business entities and their relationships, expressed in the language of the company—customers, orders, suppliers, routes—rather than low-level tables. These entities are packaged up as data products, which are essentially a way to transform less refined data into governed, discoverable, and consumer-focused views. This digital twin has two requirements:
- Stay in sync with reality: Correctly reflect the often non-obvious consequences of actions agents take as soon as they occur.
- Support agent-scale: Economically support the load that arises when moving from human-generated to machine-generated traffic.
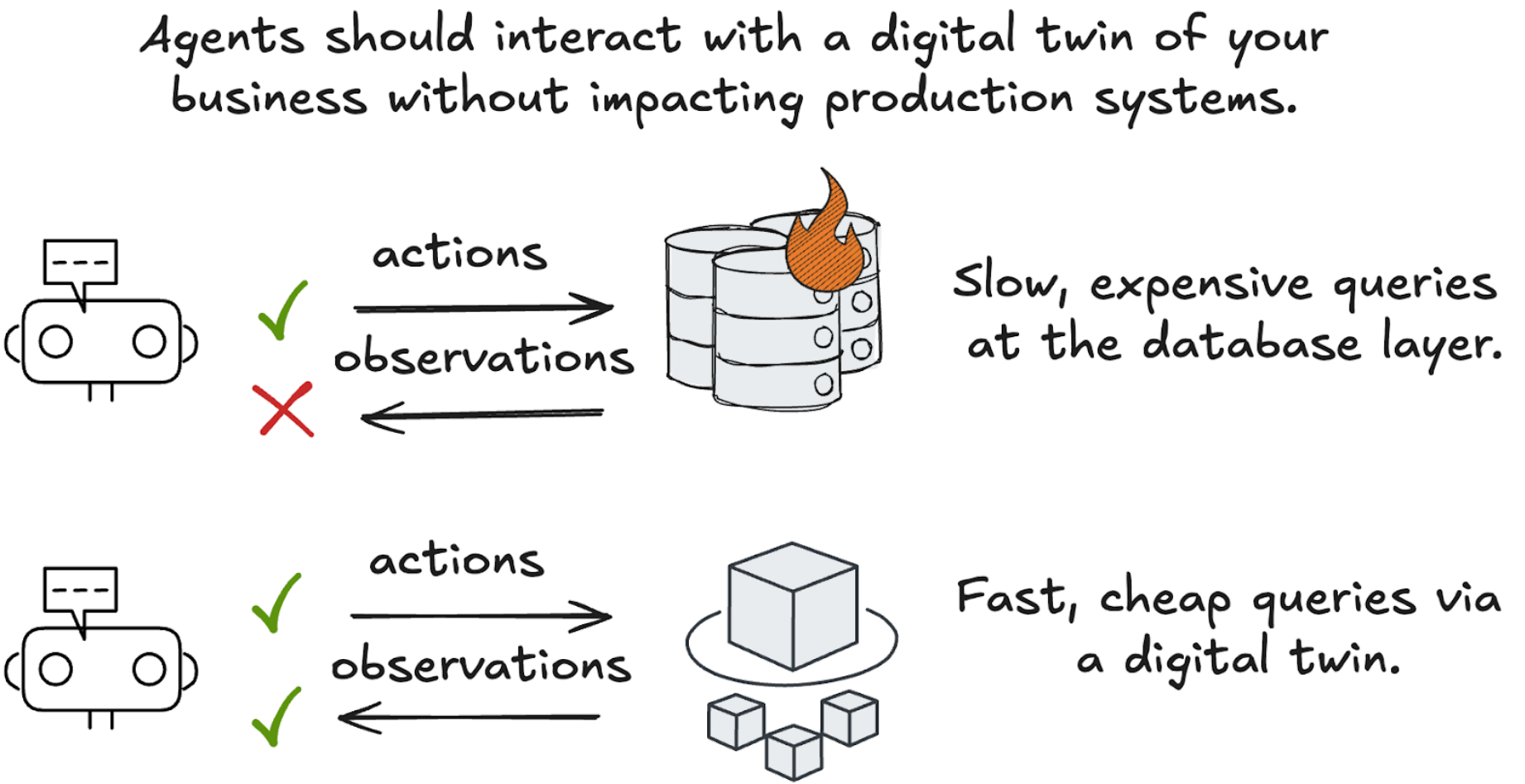
Figure 1: different approaches to providing context to agents
A digital twin gives your agents a tight feedback loop, enabling them to complete tasks faster and more reliably.
- Observe: An agent needs to understand the state of the world at any moment: Where is a shipment right this second, and where is it going next? With a digital twin, that view is already assembled and accessible in milliseconds. Without one, the agent is left fumbling through shipments_header, shipments_detail, and events_log tables ultimately crafting a query—a potentially expensive one—to get the environmental context they need.
- Think: Based on what the agent retrieved, the agent relies on an LLM to reason about what to do next. Is the package delayed? Does policy call for a refund or a reroute? Do I need more data?
- Act: Once a decision is made, the agent—or a human in the loop—acts. This results in writes to operational systems, and the digital twin updates within seconds. Every other agent immediately sees the new state and adjusts their workflow accordingly. Because data products are defined ahead of time, agents don’t waste inference cycles piecing tables together—they simply act and watch the digital twin refresh. They’re ready to start the loop again.

Figure 2: an agent control loop leveraging a digital twin
Choosing the right architectural foundation
Giving agents access to a digital twin using a data warehouse is like sharing a picture of a starry night: the stars haven't looked that way in a long, long time. Data warehouses are great for modeling the complex relationships that make up a digital twin, but the work to maintain it is expensive and so the results are recomputed periodically in batches. This means agents can’t see the impact of their own or others’ actions for minutes at best, typically hours; they’re wandering around in the dark.
Operational (OLTP) databases have much better data freshness, but aren’t designed to efficiently handle the transformations required to build up a semantic model. Attempts to work these limitations with low-level stream processors, caches, and other glue make your digital twin and its relationships difficult for agents to reason about and evolve.

Figure 3: using digital twins to add a trustworthy “speed layer” for agent context
While neither OLTP databases nor data warehouses are suitable as the sole data layer for agents, each plays a complementary role: databases handle transactions to capture the present, while warehouses process large volumes of data to understand what happened in the past.
A digital twin fills a critical gap between these two systems. It operates in “operational” space but focuses on the data—and the relationships—that must be instantaneously ready for agentic decision-making. Historical ad hoc analysis and raw data for tasks like model training still belong in batch-based systems.
Digital twins function like a speed layer for understanding the current state of any aspect of the organization. Without it, an LLM-based customer support agent, for example, wouldn’t be able to detect whether an automated remediation actually resolved an issue—leaving customers waiting and frustrated.
Incremental view maintenance: a new approach for keeping data fresh
To date, the enabling engine for digital twins, has been incremental view maintenance (IVM), which is a way to keep a representation of a view, or transformation, up to date without having to reprocess everything to see the results of an update. This innovation is what makes it economically feasible to show agents the impact of their actions. Many of the core ideas behind this approach were invented by Materialize co-founder, Frank McSherry (see: Differential dataflow, which provides an efficient way to incrementally transform data as inputs change).

Figure 4: Incremental view maintenance avoids the tradeoff between fresh data and fast queries.
Here’s the general approach:
- Identify with the raw sources. These are the systems updated by – or relevant to – agent actions. Examples are your databases, ERP, event streams, etc.
- Stream updates into an IVM engine. You can do this directly using approaches like CDC, Kafka, or webhooks.
- Define views on top of this raw data. Compose these views to create live data products that capture the core business concepts: Orders, Shipments, Inventory, etc. These definitions, their relationships, and permission structures can be quite complex, so at scale, governance may be handled by metadata management tools.
As data products come online agents will get incrementally improving and continually updating views into the most important parts of your business, a digital twin. With IVM, the digital twin stays current without expensive batch jobs and reads stay cheap, even at agent scale.
Connecting the dots with MCP
As live data products—and the metadata relationships that connect them—come online, you document them in natural language and then expose them through the Model Context Protocol (MCP)—the de facto standard way for sharing context with agents. Now, any data product can become a tool an agent can discover and use directly. You can onboard an agent using similar documentation that you’d share with a new colleague. Unlike a new hire, however, the agent will patiently read through everything, and will be productive in seconds.
Here’s a reference architecture that puts the major pieces together:

Figure 5: A reference architecture for giving agents the ability to take actions and respond to their effects\
Building towards a dynamic data platform for agents
Trying to model your entire business on day one will make it impossible to learn iteratively and will indefinitely delay real value to your business. You’ll want to:
- Start small and get quick wins. Begin by defining views on a single database and letting agents complete simple tasks while using MCP to request complex data products, all without destabilizing your production system.
- Next, stand up an operational data layer that joins a handful of sources in real-time and gives agents access to their first cross-silo data assets. This will unlock more valuable workflows.
- Finally, build an operational data mesh that lets multiple teams contribute to your digital twin by publishing, composing, and governing dozens of data products without centralized coordination. This will give you the most flexibility and leverage when rethinking the distribution of work between humans and agents.
Like your organization, the digital twin must also be able to evolve quickly. New processes will emerge, and both humans and agents need the ability to mint and deploy fresh data products in minutes, not months (provided the right permissions and guardrails are in place, of course). Favor platforms that minimize the time from idea to data product so you can quickly give agents up-to-date access to the exact parts of your business they need to support new or improved workflows.
Combine IVM-backed digital twins with MCP to make your business agent-ready. The sooner you add this layer, the sooner you will be able to keep up with rising customer expectations and agent load with your current team and budget.
Next Steps
Materialize is a platform for creating agent-ready digital twins, just using SQL. It is built around a breakthrough in incremental-view maintenance, and can scale to handle your most demanding context retrieval workloads. Deploy Materialize as a service or self-manage in your private cloud.
We’d love to help you make your operational data ready for AI. You can book a 30-minute introductory call with us here.
