Confluent & Materialize Expand Streaming | Materialize

We’re happy to announce that Materialize has joined the Connect with Confluent partner program so Confluent customers can integrate both services reliably and securely to deliver real-time value for their organization.
important
Context on Materialize: If you're new to Materialize, think of it like a mix between a data warehouse and a stream processor.
- Data Warehouse on the outside - Materialize presents as a Postgres wire-compatible data warehouse: everything is controlled in SQL, and we use a distributed, cloud-native architecture similar to batch-based data warehouses like Snowflake and BigQuery.
- Stream Processor on the inside - instead of the standard query engine, there’s a stream processing framework (Timely Dataflow) that continually and incrementally maintains SQL queries (as Materialized Views).
Materialize works well with many flavors of Kafka, but with this partnership, Confluent to Materialize is a best-in-class experience for SQL on Kafka.
The value of Materialize and Kafka
What’s so useful about the Kafka + Materialize architecture? It starts with a key difference at the heart of Materialize: While every other traditional database waits for reads (SELECT queries) to run any computation on your data, Materialize shifts the computation to the writes: Each input is immediately processed through dataflows, so that results are continuously up-to-date.
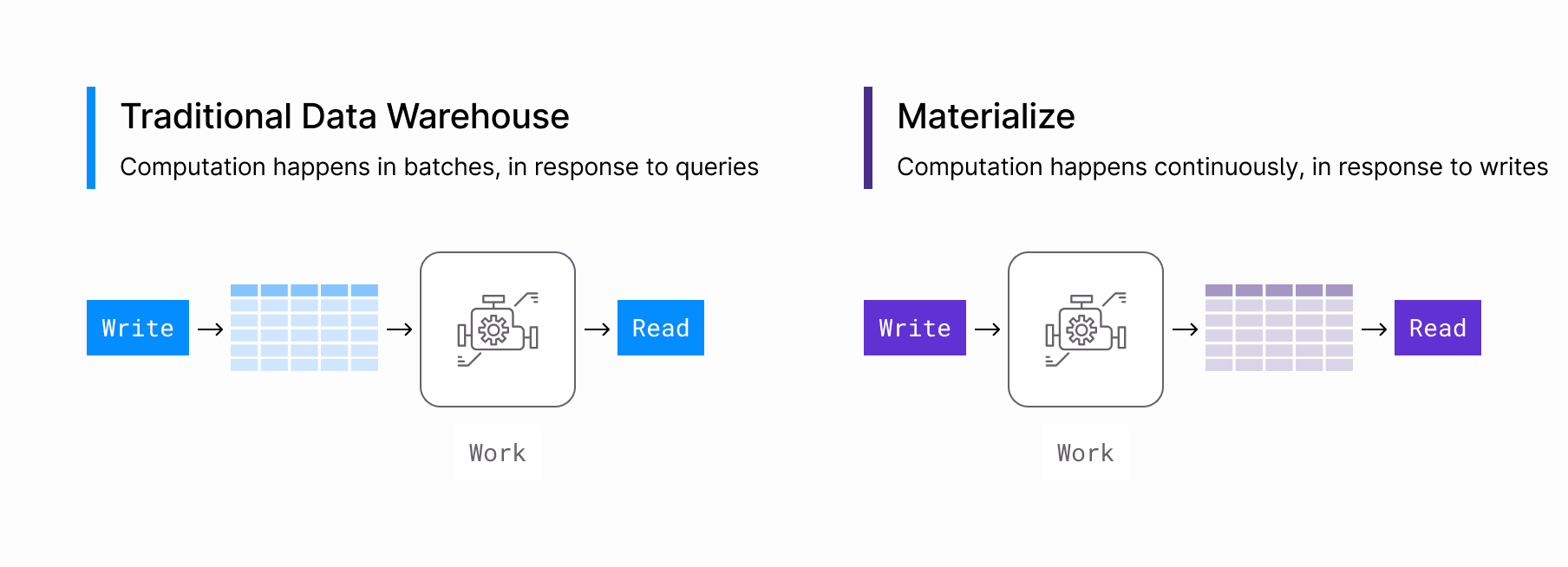
With that difference in mind, it’s helpful for Materialize to have fast access to an endless buffered log of writes, and that is exactly what Kafka provides!
Companies look to Kafka as the industry-standard streaming pipe for change data capture events from their upstream transactional database, IoT events from real-world devices, machine-generated data from servers, and any other kind of structured data that’s useful when presented as an append-only log.
Not your average Kafka ↔ Database integration
Every other integration between Kafka and a database suffers from a sort of “stream/batch impedance mismatch.” Under the surface, the integration needs a connector service that queues up a pile of changes and batches it into raw tables in the database. How to handle this raw table with opaquely-batched updates is left as an exercise for the data team…
- Are there duplicates?
- Are the updates in order?
- Will sets of updates that should be made concurrently sometimes be divided across batches?
Materialize removes these issues by sticking to streaming internally, avoiding the paradigm switch to batch. There is no batching, no scheduler in Materialize. It’s dataflows all the way down!
The connector and the database, all in one
Instead of relying on a connector service to consume from Kafka and push data in, Materialize takes the role of connector, eagerly and continuously pulling data directly from Kafka topics as it appears. Getting data flowing is a matter of creating a Source object in Materialize: all error handling, graceful restarts, deduplication, deserialization, and upsert/merge logic is abstracted away by Materialize.

The same applies to writing data out of Materialize into Kafka. Sinks are the inverse of sources, used to stream updates in the results of a SQL query continuously back out to Kafka. Sinks are integral to building event-driven architectures with Confluent Cloud and Materialize.
What happens in Materialize?
Once data is flowing, end-users of Materialize (often data analysts, ops teams, data scientists) can independently model their data using joins, aggregations, and any other complex SQL transformations needed, using the exact same workflows and skillsets they use in data warehouses:
- Standard SQL - Everything in Materialize is managed in standard SQL, and works as advertised: no need to think about co-partitioning, rekeying, repartitioning, time window semantics, join limitations, eventual consistency, etc. Materialize’s mission is to abstract those complexities of streaming data behind a familiar and predictable SQL interface.
- Workload Isolation - Like in cloud data warehouses, separation of storage and compute in Materialize means multiple teams can operate on the same data in real-time with no risk of disruption to each other’s work.
- Standard integrations - Materialize is wire-compatible with PostgreSQL. This helps it nicely integrate with common tools in the data ecosystem, like dbt as well as a wide range of other tools - from SQL clients to infrastructure-as-code (IAC).
How Businesses build with Kafka + Materialize
Zero-Latency Data Activation
Superscript is a London-based firm that distinguishes itself in the competitive insurance market through its innovative use of technology and data analytics, enabling flexible, accurate insurance coverage for businesses.
Their data team wanted to go beyond analysis and insight by using the same data to power ML process automation that directly improved top line revenues by optimizing key customer experiences. They had a prototype working in a traditional data warehouse, but the end-to-end latency was too high to work in production.
Superscript’s data team used the Confluent + Materialize stack to bring down their latency from hours to seconds, making it possible to operationalize the same SQL transformations in production in a matter of days.
Real-Time UI
White-glove delivery company Onward uses Kafka and Materialize to power a real-time delivery status UI for customers and merchants in their marketplace.
The Kafka + Materialize stack gave Onward a competitive edge over less tech-savvy competition: they could provide an Uber-like real-time UI without the Uber-like engineering team. A single data engineer was able to set up the entire integration in one sprint.
Try it out!
If you’re ready to get hands-on with Confluent Kafka + Materialize, sign up for trial accounts, where you can prototype for free and with no gated features. Register for Materialize here and Confluent Cloud here. We’d love to learn about your use case, too! Connect with our Field Engineering team to see a live demo and discuss how Materialize can fit in your stack.
