Delta Joins and Late Materialization

important
This article has been updated from the original to reflect the latest version of Materialize. The original post is available here.
Materialize allows you to maintain declarative, relational SQL queries over continually changing data. One of the most powerful features of SQL queries are joins: the ability to correlate records from multiple collections of data. Joins also happen to be one of the harder things to do both correctly and efficiently as the underlying data change.
Let's walk through the ways that Materialize maintains queries containing joins. In particular, we'll see increasingly sophisticated join planning techniques, starting from what a conventional dataflow system might do, and moving through joins that can introduce nearly zero per-query overhead -- the coveted delta join, a.k.a. delta query. Each of the new join plans we work through represent an implementation strategy that Materialize can do that other dataflow systems will struggle to replicate.
As we move through techniques, the number of private intermediate records maintained by each query dataflows drops. We'll report all 22 TPC-H queries at the end, but here are two of the largely representative queries, and the number of additional records Materialize maintains to keep the query results up to date.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
Each technique comes on-line in response to indexes that you ask Materialize to prepare. For multiple queries, indexes are a fixed upfront cost with per-dataflow savings for each new query.
At the end, we'll have a forward-looking discussion of late materialization which can further reduce the memory requirements, in a way that currently requires user assistance.
Introducing Joins
Let's take a basic example of an "equi-join":
1 | |
2 | |
3 | |
4 | |
5 | |
Most dataflow systems will plan this join using a relatively simple dataflow graph:
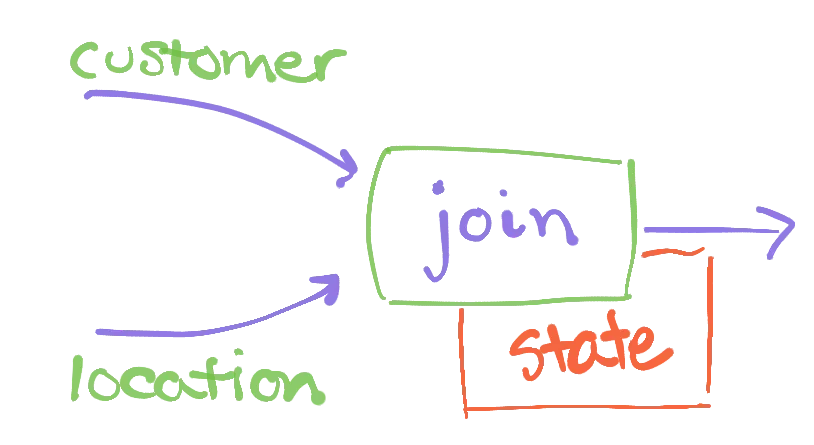
Information about the customer and location collections flows in along their respective edges. For example, when records are added, removed, or updated, that information flows as data along an edge. The join operator receives this information, and must correctly respond to it with any changes to its output collection. For example, if we add a record to customer, the output must be updated to include any matches between that record and location; this probably means a new output record with the customer name and the state corresponding to its ZIP code.
Most dataflow systems implement the join operator by having it maintain its two inputs each in an index. As changes arrive for either input, the operator can look at their zip fields and immediately leap to the matching records in the other collection. This allows the operator to quickly respond to record additions, deletions, or changes with the corresponding output addition, deletion, or change.
The operator maintains state proportional to the current records in each of its inputs.
You may have noticed the "most dataflow systems" refrain repeated above. Materialize will do things slightly differently, in a way that can be substantially better.
Binary Joins in Materialize
Materialize plans joins using a slightly different dataflow plan:
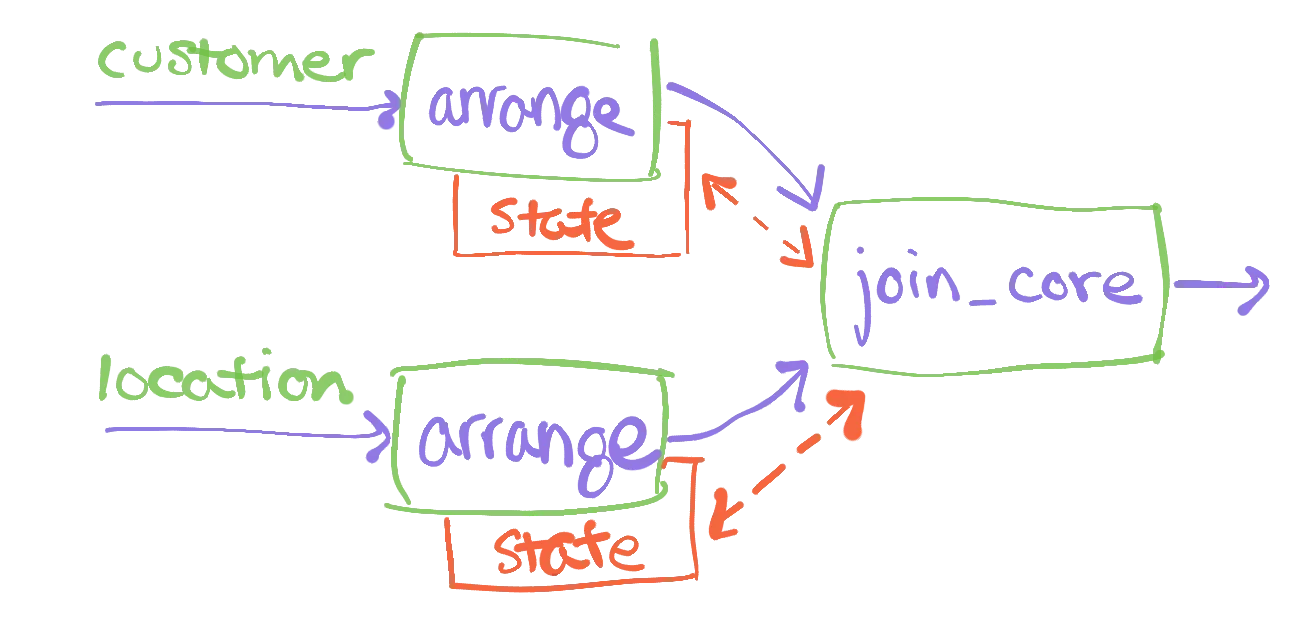
We have broken the traditional join operator into three parts. Each of the inputs first visits an arrange operator, whose results then go to a join_core operator. The arrange operators are in charge of building and maintaining the indexed representations of their inputs. The join_core operator takes two pre-indexed, maintained collections and applies the join logic to the changes that move through them.
Why break apart the join operator into arrange and join_core?
As you may know from relational databases, a small number of indexes can service a large volume of queries. The same is true in Materialize: we can re-use the indexed representations of collections across many independent joins. By separating the operator into 1. data organization and 2. computation, we can more easily slot in shared, re-used arrangements of data. This can result in a substantial reduction in the amount of memory required, as compared to traditional dataflow systems.
Let's take the example above, using customer and location. The standard dataflow system will build private indexes of customer and location, each indexed by their zip field. The zip field in location may be a primary key, meaning each record has a different value of the field. Joins using primary keys are effectively "look-ups" and are quite common. Each such look-up would be a join using location.zip and would require the same index. We can build the index once, and re-use it across all of the query dataflows that need it.
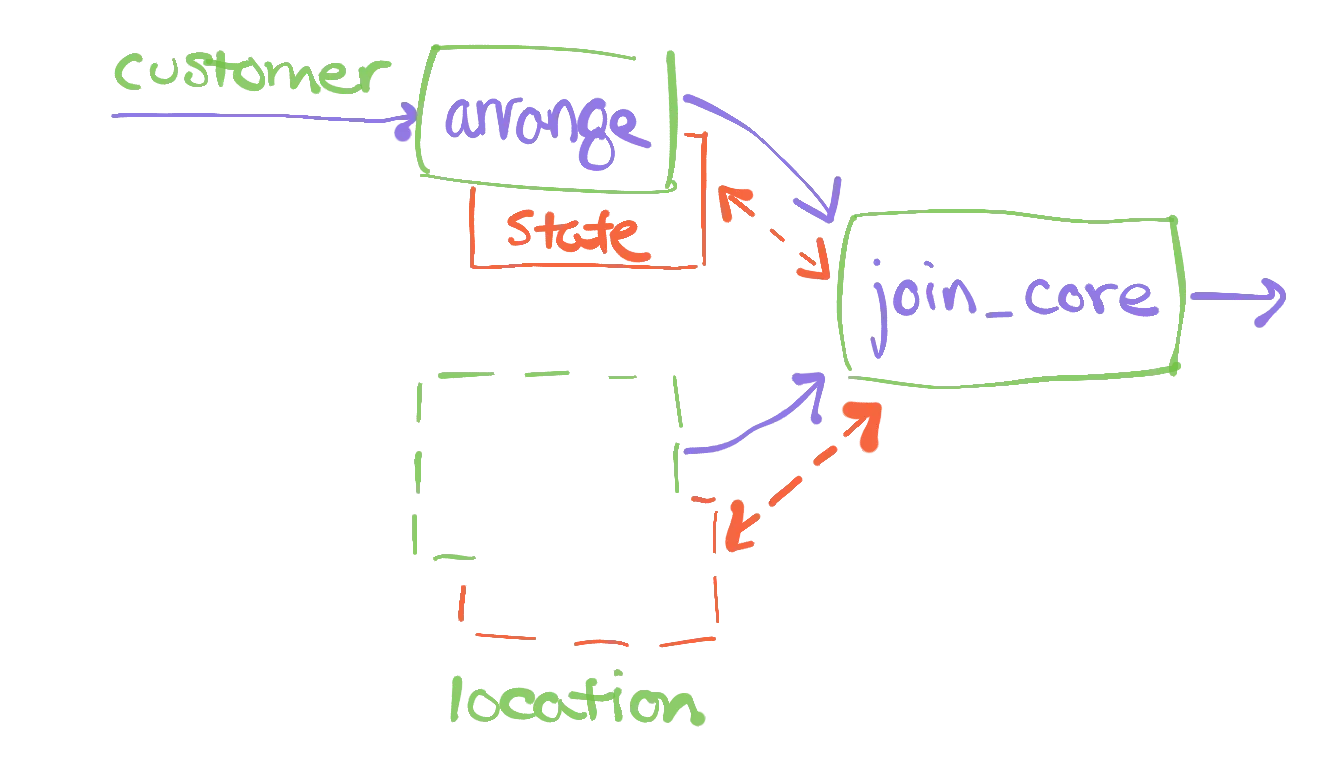
We would still need a private copy of customer indexed by zip, but as we will see next there are standard clever idioms from databases that can make this efficient as well.
Optimizing A Query from the TPC-H Benchmark
Let's optimize a query from the TPC-H data warehousing benchmark that joins multiple collections.
Query 03 is designed to match the following description:
The Shipping Priority Query retrieves the shipping priority and potential revenue, defined as the sum of l_extendedprice * (1-l_discount), of the orders having the largest revenue among those that had not been shipped as of a given date. Orders are listed in decreasing order of revenue. If more than 10 unshipped orders exist, only the 10 orders with the largest revenue are listed.The query itself is:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
The absence of LIMIT 10 from the query is just how TPC-H defines things. In the interest of clarity we are going to work on the core of the query, without the ORDER BY or elided LIMIT. The query is a three-way join between customer, orders, and lineitem, followed by a reduction. The reduction keys seem to be three random fields, but notice that l_orderkey = o_orderkey, where o_orderkey is a primary key for orders; we are producing an aggregate for each order.
Materialize provides a TPC-H load generator source, so you can follow along and recreate this example as we go. To follow along, you will need access to Materialize as well as a Postgres client like psql to submit queries. By default, all of this computation will happen in the default cluster on a 2xsmall sized replica called r1. We'll be using the scale-factor 1 that streams updates once per second.
1 | |
2 | |
3 | |
4 | |
The initial dataset is loaded, and then once per second, an update, insert, or delete is added to the stream.
A First Implementation
Let's store Query 03 as a view.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
In Materialize, a view is just an alias for a query definition. To trigger computation, we must create an index on the view.
1 | |
Let's count the results (press Ctrl+C to kill the subscription).
1 | |
1 | |
So we have the occasional insert, update, or delete, but there should be roughly 11-12 thousand records in the result. Your exact numbers will vary slightly from what you see here.
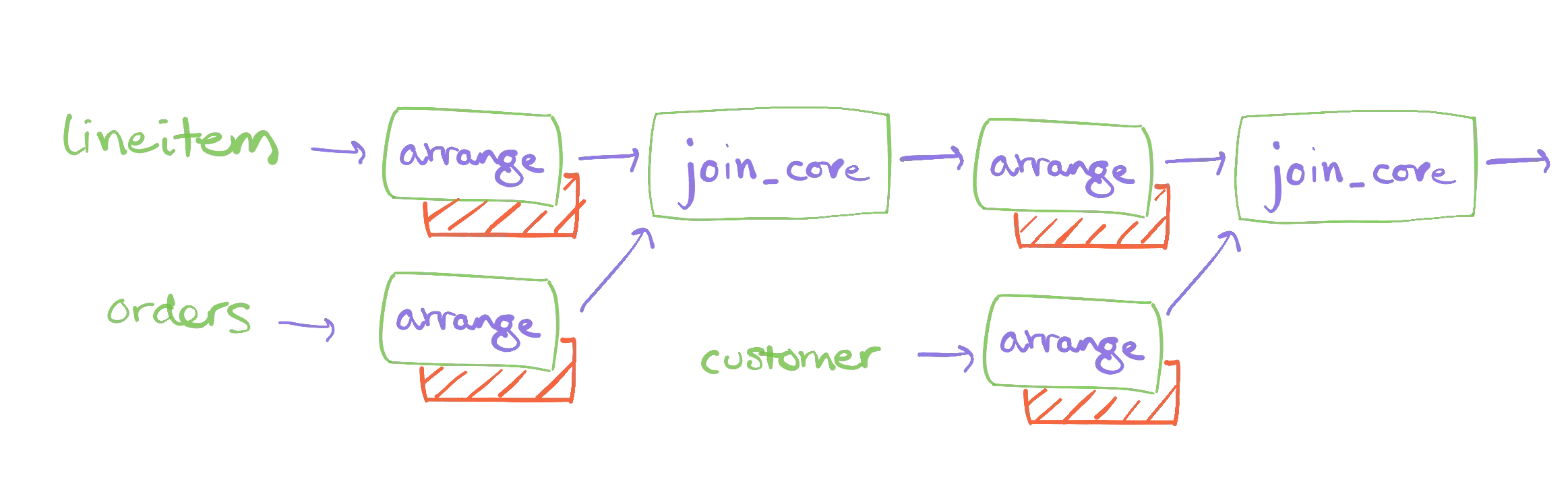
Maintaining this query comes with a cost. The dataflow that maintains query_03 maintains several indexes over input and intermediate data. Here is a sketch of what the dataflow graph looks like for query_03 deployed against the raw data.
We can read out these volumes from Materialize's logging views. To read out the total records maintained by each dataflow, we would type:
1 | |
2 | |
3 | |
4 | |
5 | |
When we do, we see:
1 | |
2 | |
3 | |
4 | |
This tells us that our dataflow maintains some 4,173,794 records for the query_03 dataflow. These are in support of maintaining the 11,620 results from that query, which may seem disproportionate. The explanation is that this dataflow needs to maintain each of its inputs, which are not otherwise stored within Materialize. For example, the lineitem relation has six million records, and we need to maintain all relevant records (not all of them, as the filter on date removes roughly half of them).
There is a substantial cost to maintaining this query. If we wanted to maintain more queries with similar structure, each would require just as many additional records. We would exhaust the memory of the system relatively quickly as we add these queries.
This approach roughly tracks the resources required by the conventional dataflow processor. So, let's do something smarter.
Primary Indexes
Each of the TPC-H relations have a primary key: a column or set of columns that uniquely identify each record. As discussed above, joins often use primary keys. If we pre-arrange data by its primary key, we might find that we can use those arrangements in the dataflow. This means we may not have to maintain as much per-dataflow state.
Let's build indexes on the primary keys for each collection query_03 uses. We do this with Materialize's CREATE INDEX command.
1 | |
2 | |
3 | |
important
Notice that lineitem doesn't have a single primary key column. Instead, we use a composite primary key consisting of l_orderkey and l_linenumber.
These indexes have names, though we do not need to use them explicitly. Rather, the columns identified at the end of each line indicate which columns are used as keys for the index. In this case, they are all primary keys.
With these indexes in place, we can rebuild our dataflow for query_03. Materialize can plan the dataflows based on the available indexes and may find better plans which maintain less private state. The new dataflow graph will look like so
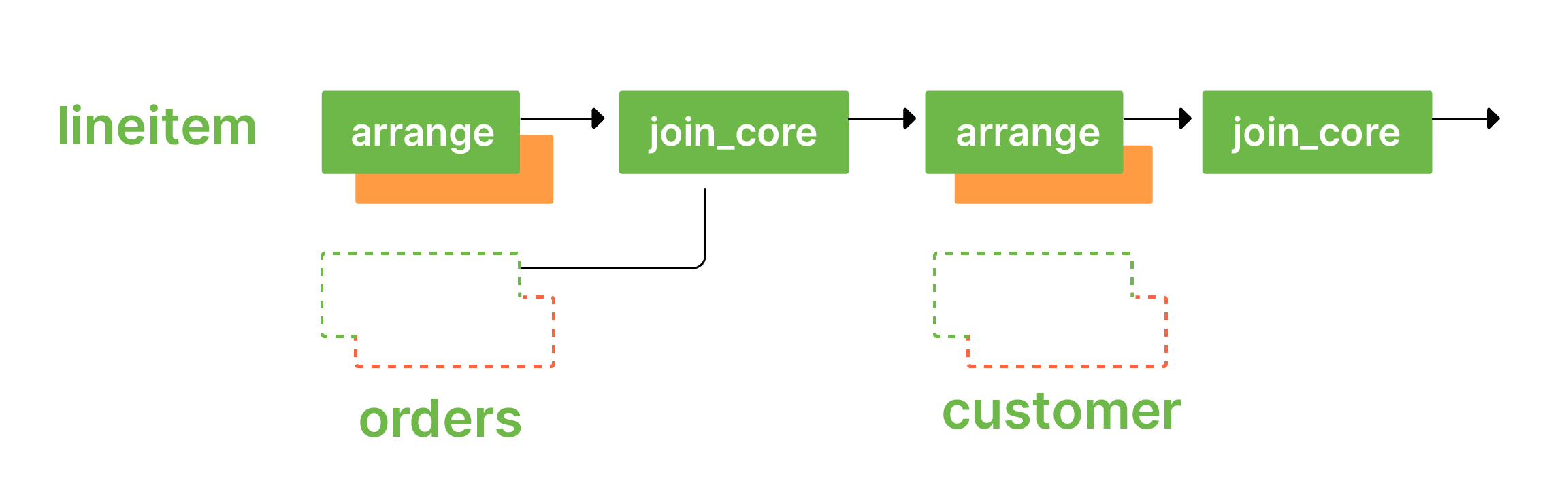
Notice that some places where we had "state" before are now dotted. This indicates that they are not new state; the state is simply re-used from pre-existing indexes.
In order for query_03 to take advantage of these new indexes, we have to recreate query_03_idx. Let's rebuild the computation for query_03 and re-run our diagnostic query.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
There are a few things to notice here. First, there are a lot more entries. Each of the indexes we constructed are backed by dataflows, and they each maintain as many records as their collection contains. Second, the number of records for the dataflow backing the query_03 materialized view has decreased. This state has not vanished, and we will explain what records it still maintains — but it is on its way to maintaining fewer records! Third, the numbers for the created indexes are non-trivial. This has not been a net reduction, if we only needed to maintain the query_03 dataflow. However, the main idea is that for multiple queries, the primary indexes are a fixed upfront cost with per-dataflow savings for each new query.
How do we explain the reduction for query_03? Why was the reduction as much as it was, and why was it not more substantial? If we examine the query, we can see that the equality constraints are on o_orderkey and c_custkey, which are primary keys for orders and customer respectively. However, we do not use (l_orderkey, l_linenumber) which is the primary key for lineitem. This means while we can re-use pre-arranged data for orders and customer, we cannot re-use the pre-arranged data for lineitem. That relation happens to be the large one, and so we still eat the cost of maintaining much of that relation (again, with a filter applied to it).
Secondary Indexes
Whenever we have a column that is a primary key of another collection, it is called a foreign key. When we create an index on a foreign key, it's called a secondary index.
If we had an index of lineitem by l_orderkey, the foreign key from orders, we should be able to use it to further reduce the memory requirements. Let's try that now.
1 | |
Rebuilding the query results in a dataflow that looks like so
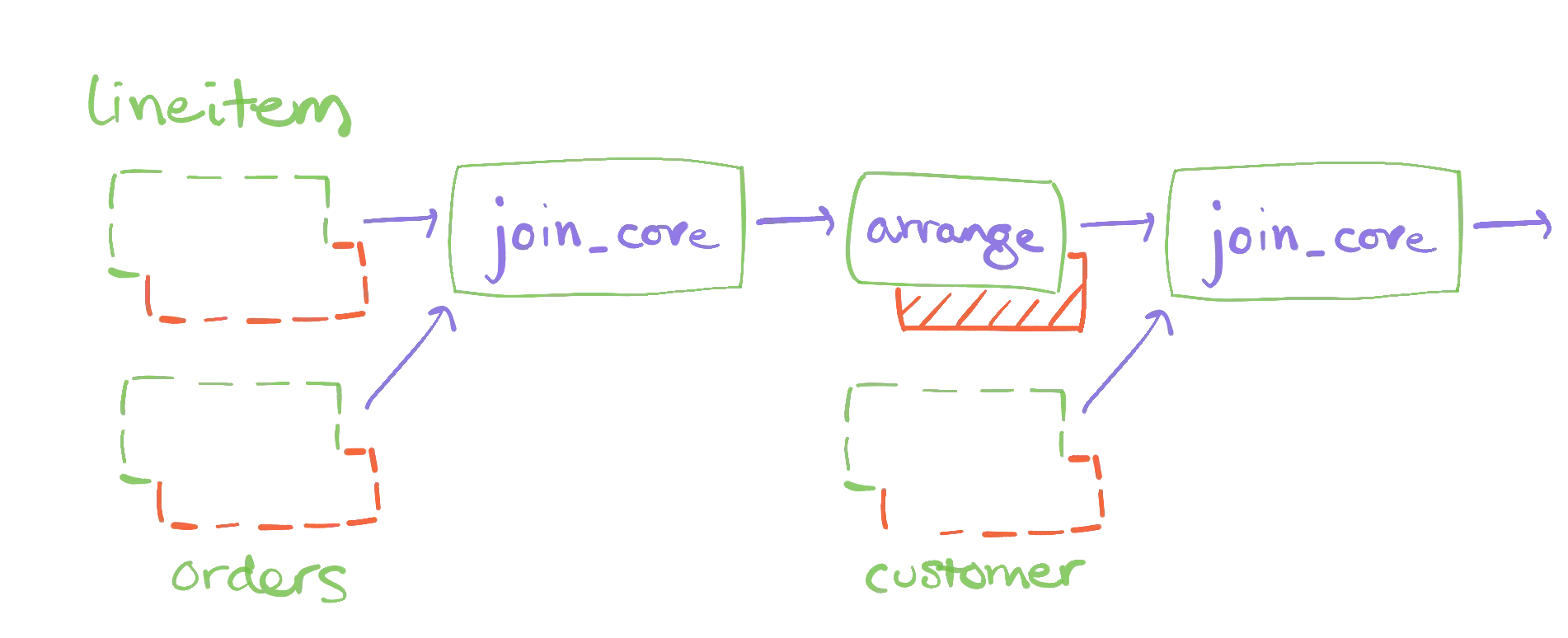
If we recreate the computation of the query and re-pull the statistics on records maintained, we see
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
The query_03 dataflow is now substantially smaller. We've been able to re-use the fk_lineitem_orderkey index, saving ourselves a substantial number of records. This comes at the cost of a new fixed-cost index. This is expensive because the index we have described arranges all of lineitem. Readers familiar with databases may wonder why we didn't just create an index from l_orderkey to lineitem's primary key instead of all of lineitem. We'll get to that in a few sections!
Recall from before that query_03 just has 11,620 records. Where are the remaining 162,951 records coming from? While we may be able to use pre-arranged inputs for orders, customer, and now lineitem, our dataflow still needs to maintain the intermediate results produced from the first binary join. As it turns out, this is the result of joining orders and customer, then filtering by the c_mktsegment = 'BUILDING' constraint. This could be big or small, and fortunately in this case it is not exceedingly large.
However, maintaining these intermediate results gets increasingly painful with multi-way joins that involve more relations. TPC-H query 08 contains an eight-way join, and would have seven intermediate results to maintain. There is no reason to believe that these intermediate results would be substantially smaller than the inputs. Moreover, the intermediate results are almost certainly specific to the query; we wouldn't expect they could be re-used across queries.
Fortunately, there is a neat optimization to get around the pesky intermediate results.
Delta Query
We created a secondary index, but what happens if we create all the secondary indexes we can for query_03. Repeating the fk_lineitem_orderkey from above, these would be:
1 | |
2 | |
Let's see what happens when we rebuild query_03, and re-pull its record counts.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
As you can see, each new index represents a significant increase in the fixed costs for working with this dataset. You can also see (look for the -->) that the record count for query_03 dropped significantly. It is now exactly twice 11,620 which is the number of output records. It turns out this is the bare minimum materialize can make it, based on how we maintain aggregations.
So, despite all that worry about intermediate results, with enough indexes we are somehow able to avoid the cost at all. What happened?
Materialize has access to a join execution strategy we call DeltaQuery that aggressively re-uses arrangements and maintains zero intermediate results. This plan uses a quadratic number of arrangements, with respect to the number of input collections. This would be terrible for a conventional dataflow system that cannot share arranged data. For Materialize, as long as there are few enough distinct arrangements, the cost can be much lower. Materialize considers this plan only if all the necessary arrangements already exist, in which case the additional cost of the join is zero.
The dataflow for this plan may be mysterious (the lookup operator goes unexplained for today) but you can see that all arrangements are now dotted:
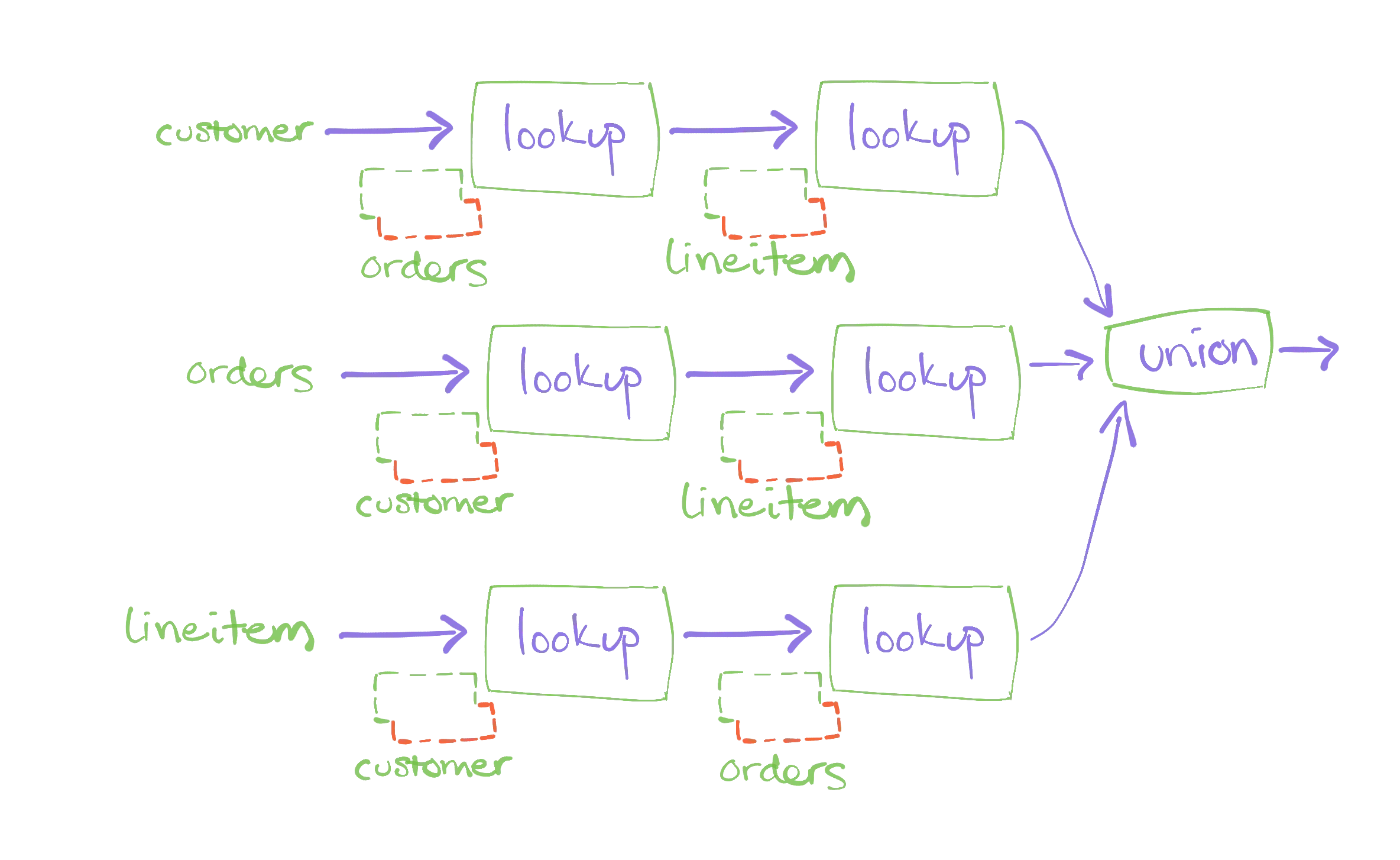
You might reasonably be hesitant about the outlay of pre-arranged data required to enable delta queries. We now have five copies of lineitem to maintain, and it is not the smallest collection of data. However, the per-query cost is now substantially reduced, and a quite-large number of analysts can each work with a quite large number of queries without exhausting materialize.
Late Materialization
Let's talk about how expensive the arrangements of lineitem are and how we can bring that cost down.
Each of these arrangements replicates the full contents of lineitem. That is clearly a lot of data, and a lot of redundancy. In a conventional dataflow system this overhead is expected; the join operator needs to keep whatever state it needs. But what happens in a more traditional relational database?
Indexes in a relational database don't often replicate the entire collection of data. Rather, they often maintain just a mapping from the indexed columns back to a primary key. These few columns can take substantially less space than the whole collection, and may also change less as various unrelated attributes are updated. This is called late materialization.
Can we do this in Materialize? Yes! First, let's destroy everything we've done so far except for the primary indexes (we still need those):
1 | |
2 | |
3 | |
If we are brave enough to rewrite our query just a little bit, we can write the same join in a way that does not require multiple arrangements of lineitem. As a reminder, here are the relevant join conditions for query_03:
1 | |
2 | |
3 | |
4 | |
So we have a foreign key l_orderkey in lineitem and another foreign key o_custkey in orders. The trick will be to define "narrow" views of lineitem and orders that contain only the primary key and foreign key, and build indexes for each.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
With these new "narrow" views and their indexes, we can rewrite query_03 to perform the core equijoin logic. We then join their primary keys back to the orders and lineitem collections, which are indexed only by their primary keys.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
23 | |
24 | |
25 | |
26 | |
27 | |
28 | |
29 | |
Trigger computation by creating an index on the query_03_optimized view.
1 | |
What happens now in join planning is that "delta query" planning still kicks in. We have all the necessary indexes to avoid maintaining intermediate state. The difference is that we only ever use one index for each "wide" relation. The relations Materialize must index multiple times are narrow relations whose rows can be substantially smaller. You can confirm you are using a delta join by running EXPLAIN VIEW query_03_optimized; and noting that the output contains type=delta and uses the primary and secondary indexes we created.
Clean up
At this point we can clean up resources:
1 | |
You can also drop the replica you are using to save resources if no one else is using it.
Conclusions
Scanning across the 22 TPC-H queries, the numbers of records each query needs to maintain drops dramatically as we introduce indexes:
*: Query 20 has a doubly nested correlated subquery, and we currently decorrelated this less well than we could. The query does complete after 11 minutes or so, but it runs much more efficiently once manually decorrelated. Query 18 would also be much better manually decorrelated, but it ran to completion so I recorded the numbers.
Our use of shared arrangements means gives us access to efficient join plans that conventional dataflow systems cannot support. These join plans can substantially reduce the per-query resource requirements for relational queries.