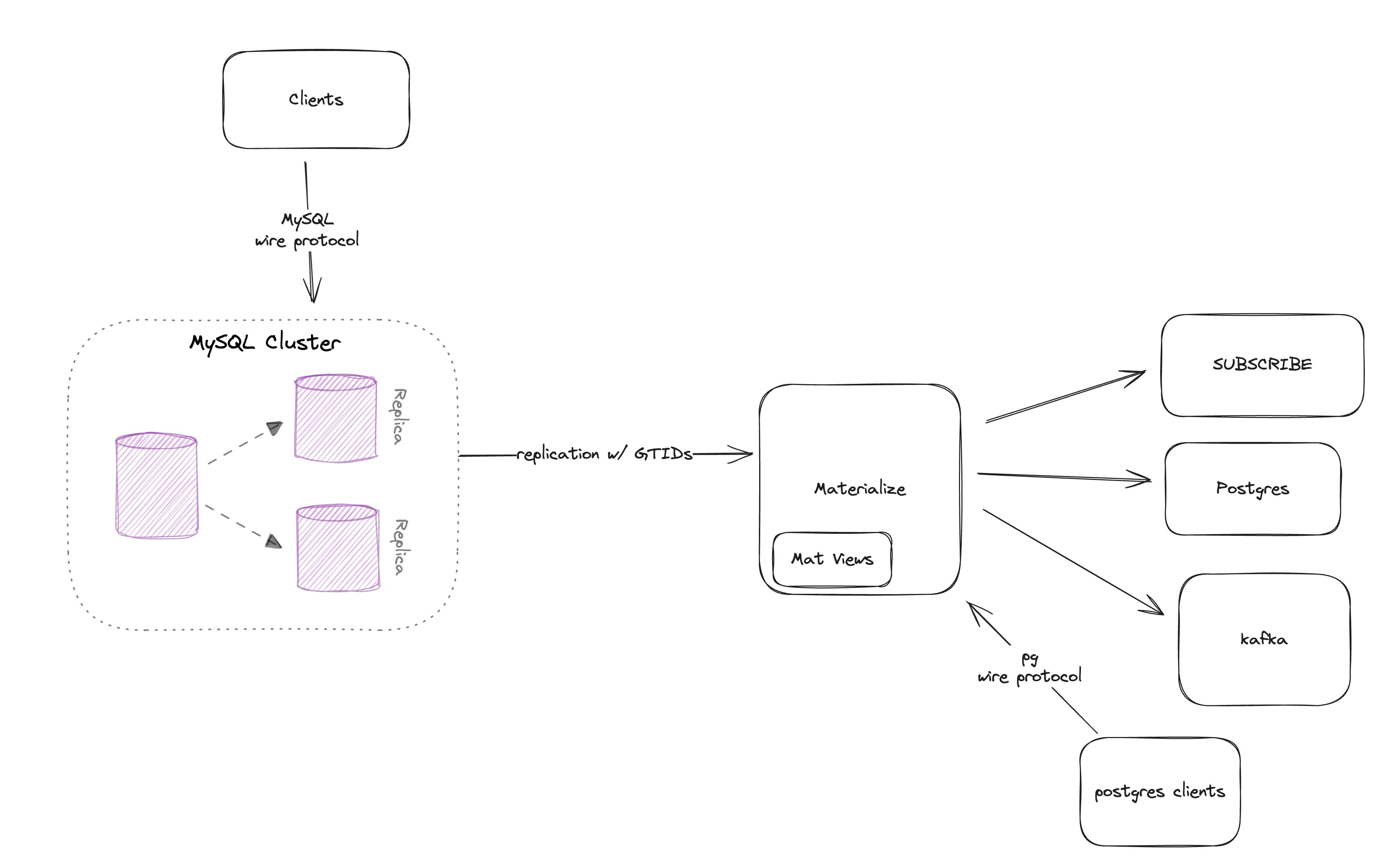
Building a MySQL source for Materialize

Our new native MySQL source enables real-time replication from MySQL into Materialize, enabling users to power their operational workloads with a fresh and consistent view of their MySQL data.
The MySQL source is the second native “change data capture” (CDC) source we’ve built (the first is our PostgreSQL source). While it was already possible to ingest MySQL data into Materialize using Debezium as a CDC service, a native source avoids the need for additional infrastructure, requires less storage and memory overhead, and respects transactional consistency throughout the system.
Our engineering team had a lot of fun building the MySQL source and this is a recap of how we did it.
Starting the project
MySQL is one of the most popular databases in the world — in fact it was ranked as #1 most popular in Stack Overflow’s rankings until 2023, when it was overtaken by PostgreSQL.
Despite that popularity, our engineering team didn’t have a lot of recent experience with MySQL. We are a PostgreSQL-compatible database and our experience skews more towards the PostgreSQL ecosystem.
However we did have the benefit of building a MySQL source after our PostgreSQL source had been live for over a year. This gave us a general idea of the scaffolding required for a new CDC source, a large corpus of test cases and QA infrastructure to re-use, and insight into the common user-experience issues and bugs we faced when building the PostgreSQL source.
Our biggest unknowns were specific to MySQL — we needed to dig into replication semantics, data formats, and consistency behavior to ensure we could build something that maintained correctness in all situations and provide the ergonomics our users expect in our product.
MySQL replication
MySQL replication is built around the the MySQL binary log, which is somewhat akin to PostgreSQL’s Write-Ahead Log (WAL). The binary log contains events that describe database changes such as table schema operations (DDL) and changes to table data. It’s used for both replication and data recovery.
One of the most interesting parts of MySQL replication is synchronization via Global Transaction Identifiers (GTIDs). GTID-based replication improves upon the earlier replication method based on synchronizing log file names and positions within them. GTID-based replication is transaction-based, which simplifies replication and failover since GTIDs received more than once can be ignored and as long as all GTIDs committed on a source are also committed in the same order on a replica, the source and replica are guaranteed to be consistent.
GTIDs in MySQL are of the format source_id:transaction_id. The source_id is a UUID identifying the individual server that committed the transaction. The transaction_id is an integer that monotonically increases without gaps on each server.
A “GTID Set” exposes any combination of GTIDs, for example: 24DA167-0C0C-11E8-8442-00059A3C7B0:1-55, 3E11FA47-71CA-11E1-9E33-C80AA9429562:1-23 identifies two ranges of transactions committed across two originating servers. Server 24DA167... originally committed transactions 1 through 55, and server 3E11F4A47 committed transactions 1 through 23.
We can use the GTID Set executed on a given MySQL server to understand the state of the data it contains, and as a way to represent progress in a consistent way when reading the replication stream.
The events in the replication stream are also important to understand, and we spent time investigating how their format would impact the work we had to do on our side to present correct results.
We learned that when using row-based and full row-image binary log settings (the defaults from MySQL 8.0+) the events in the binary log contain the full row contents of both the before and after version of each row affected by an INSERT/UPDATE/DELETE statement.
This is a huge advantage for us, since we must propagate changes through Materialize (which is based on Timely and Differential Dataflow) by sending the full row contents to downstream dataflows. If we didn’t have the full row presented by MySQL, we’d have to implement a key-value store of all keys in each MySQL table close to our MySQL replication-stream reader. This is necessary in our Kafka source when ingesting log-compacted topics and using Debezium due to at-least-once delivery guarantees. Maintaining this key–value store can be surprisingly expensive— see this blog post for details.
There were also some features we discovered did not exist in MySQL replication that we were used to in PostgreSQL logical replication:
- PostgreSQL publications. Events affecting all tables are included in the MySQL replication stream and any filtering must be done on the receiving side. If a MySQL server has many actively-written tables but we only care about replicating a few to Materialize, we still need to receive the updates for all of them. The upshot is that MySQL sources may need to be sized a bit larger than the equivalent PostgreSQL source, since Materialize will need more CPU and network bandwidth keep up with all changes to the upstream database, rather than just the changes it’s interested in.
- PostgreSQL replication slots. There is no way of ensuring the events we want to read in the MySQL server’s binary log are not removed from the MySQL server if our source is interrupted. This means we must stay at least as up-to-date as the the oldest binary log file available. The upshot is that production deployments of the MySQL source should monitor the source progress (a GTID Set) against MySQL’s binary log cleanup process and ensure there is always a healthy amount of space between the progress Materialize is making vs the GTIDs kept available in the binary logs on the MySQL server.
Source architecture
Once we understood the basics of MySQL replication, we spent time architecting the new MySQL source. Luckily we were able to re-use a few concepts:
- We used the same “subsource” model as our PostgreSQL source. Each MySQL replicated table is represented as a “subsource” in Materialize with its own schema.
- The source uses the same Timely Dataflow “operator model” as our PostgreSQL source, breaking down the work into “Snapshot” and “Replication” operators.
- To correctly represent GTID Sets as the MySQL source timestamp format, we built upon a Partitioned Timestamp implementation used to track offsets across Kafka partitions in our Kafka Source.
Snapshotting and replication
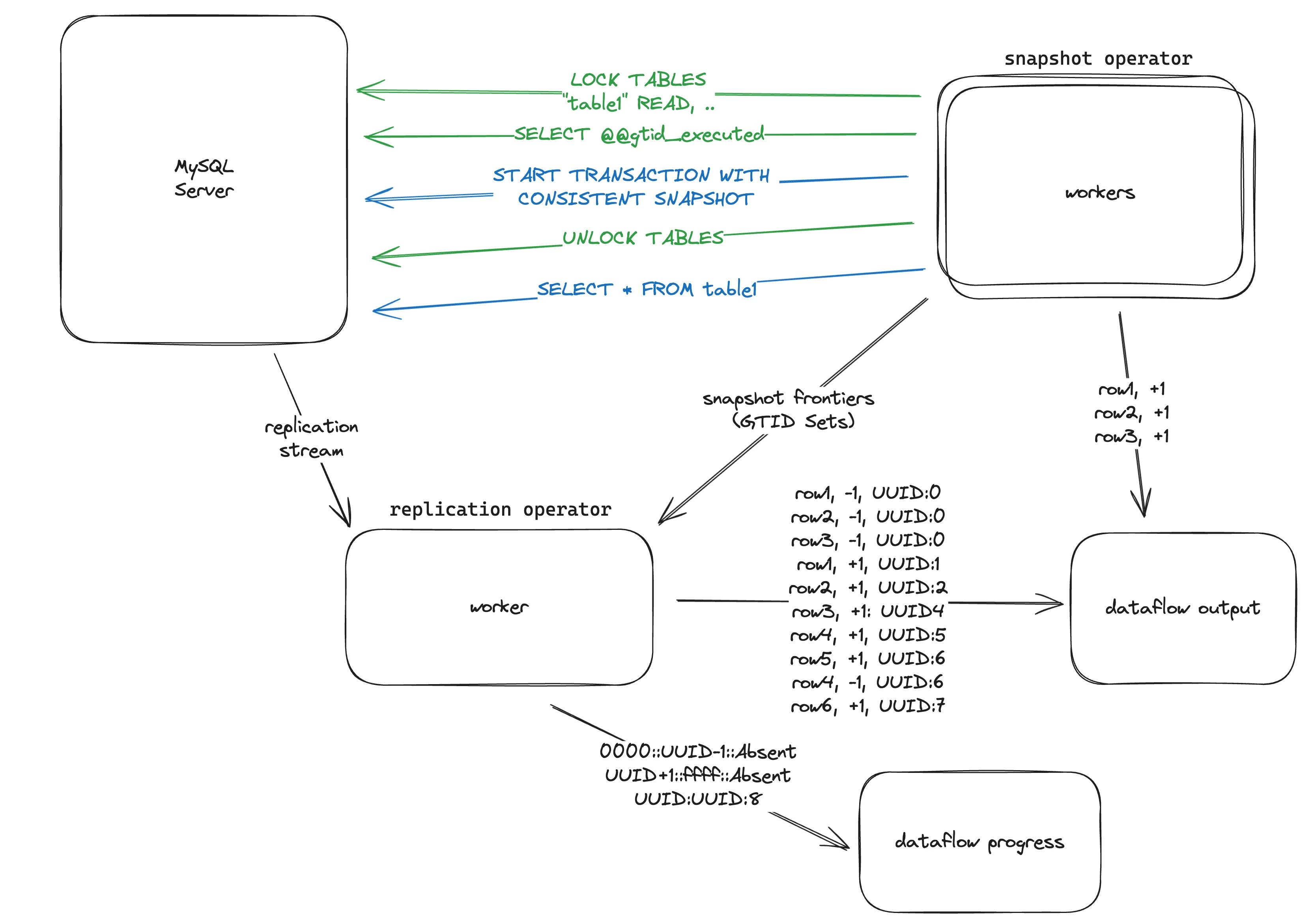
The MySQL source is split into two Timely Dataflow operators, which you can think of as async routines that can be run across multiple workers to perform actions and output data to downstream dataflows.
The snapshot operator is responsible for taking an initial consistent snapshot of the tables involved in the ingestion from the MySQL server. It is crucial for correctness that we always perform the snapshot of all tables at a consistent point in time. Unfortunately MySQL does not provide an API to perform a transaction at a specific point in time! To work around this, we use two tricks:
- Each snapshot worker obtains a read lock on the table(s) it intends to snapshot. Once it obtains the lock it reads the value of
gtid_executedwhich represents the GTID Set committed on the MySQL server at this point. It then starts a second connection and transaction withREPEATABLE READandCONSISTENT SNAPSHOTsemantics, and then releases the lock held by the first connection. Due to transaction linearizability, the snapshot performed in the second transaction has a known upper-bound GTID Set of the value read fromgtid_executedin the first connection (we call this value thesnapshot frontier). - Since the
snapshot frontierfor each table can be different and may be beyond the initial consistent point we picked for the source as a whole, we send thesnapshot frontiervalues to the replication operator and ask it to ‘negate’ all updates that occurred between the initial consistent point and thesnapshot upperfor each table. We call this ‘rewinding’.
The replication operator connects to the MySQL replication stream to receive events and handles multiple event types, two of which are most important:
- The GTID Event contains a single GTID and identifies the GTID of the subsequent events, which can be multiple for multi-table or large transactions.
- Row events include sets of rows affected by a transaction. Each row has a potential
beforeandaftervalue (inserts populateafter, deletes populatebefore, and updates populate both).
The replication operator starts replication from a known GTID Set by providing MySQL with the set of GTIDs it has committed, and keeps track of the complete GTID Set it has seen by adding newly received GTIDs into it.
Progress tracking
Each source in Materialize needs to timestamp the updates it produces and to represent progress of the underlying Timely dataflows. In our PostgreSQL source we use the LSN of each event and in our Kafka source we use the offsets for each Kafka partition of the topics we care about as a Partitioned Timestamp (a set of partitions with incomparable timestamps that as a whole can be partially ordered).
We might receive new GTIDs that correspond to an existing source_id (server UUID) of the known GTID Set or a new one, in various orders (as long the transaction_ids for a given source_id are consecutive and monotonic). These scenarios can happen if we’re connected to a MySQL replica which itself is configured for multi-source replication, or could happen during a failover from one MySQL server to another. We created a format that can represent a singular GTID as a timestamp or a GTID Set to track progress in the MySQL Source.
One of the difficulties we faced with progress tracking was how to represent the progress as a frontier, which in Timely Dataflow represents the set of times such that any future time of data presented by the operator must be greater or equal to some element of the set (yes, this makes makes our heads hurt too). Since we could theoretically receive a new GTID for any not-yet-seen source_id UUID in the future, we needed to represent the full range of possible UUIDs as part of this timestamp. There are a few more gory details, but we essentially end up with something like this:
When we’re caught up to a MySQL server with this GTID Set:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
Our progress frontier looks like:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
The first two rows represent partitions of the UUID ranges outside the known source_id 474ac6f9-e09e-11ee-9ebb-0242c0a8b703 and the 3rd row represents that all future transactions for that source_id will be greater or equal to 102.
This is quite a bit more complicated than tracking LSNs in the PostgreSQL source, but accounts for the more complex cluster topologies possible in MySQL.
Data types
Once MySQL rows are received, we needed to cast the values in each row to the correct types in Materialize to be able to be used downstream. Materialize’s built-in types roughly correlate to a subset of those in PostgreSQL. Some of the interesting ones we implemented:
enumvalues are sent as encoded-strings in a query response but as 1-indexed integers in the replication stream. We need to store the set of enum values to find the corresponding value when receiving events on the replication stream.numeric/decimalvalues are sent as encoded strings in a query response but represented in decimal binary format on the replication stream so we had to handle both.timevalues may range from-838:59:59to838:59:59in MySQL, but in PostgreSQL and Materialize may range from00:00:00to24:00:00, so we will currently put the source into an error state until the out-of-bounds values are deleted. We will eventually add support to cast these values to text as a workaround.
Validating our work
We were fortunate to have built up a corpus of integration tests, simulated workload tests, and many more validation scenarios for ensuring the health of our PostgreSQL source. Our QA team ported these tests to validate the MySQL source implementation. Two of these bugs were the kind of bugs you typically only find after deploying to production, but the extensive tests were able to smoke these problems out ahead of our production rollout:
- In our long-running nightly validation tests we discovered a mistaken assumption about the ‘table-ids’ that MySQL uses to map rows events to tables in the replication stream. We had assumed the mappings were static during the stream lifecycle so we implemented a simple in-memory cache for them. They did stay consistent during most of our test scenarios, but this long-running test was able to trigger an upstream change in these mappings, which caused data from one table to be incorrectly mapped to another. A case of premature optimization that we simply removed!
- Another test case performed many concurrent table operations on the upstream MySQL tables during the snapshot process. The test was failing since the snapshot did not result in the correct outputs downstream. We questioned our locking and snapshot strategy and even dug into the internals of MySQL transaction and MVCC behavior. We were stumped after ruling out several complex hypotheses, and then someone noticed that we were simply dropping the returned transaction handle from the Rust MySQL client before we started the snapshot, resulting in the snapshot happening outside of the REPEATABLE READ transaction. We were glad our tests detected the incorrect behavior, and the result was a simple fix along with an upstream change to make it extremely unlikely that a bug like this could bite someone else.
Going forward
Beyond the implementation details above, we implemented support for detecting schema changes and support for MySQL connections over TLS/SSL, SSH tunnels, and AWS PrivateLink.
In the future we plan to improve the ergonomics around handling schema changes and improve performance by separating out the decoding and casting steps into a separate operator.
And now that we’ve gone from 1→2 CDC sources in Materialize, we are confident that the time to build new source types will only decrease.
If you are interested in taking the new MySQL source for a spin, sign up for a 14-day free trial of Materialize, and ping our team on Slack to get early access to the feature!
