Streaming TAIL to the Browser - A One Day Project

Last week concluded up my first week at Materialize, with Friday being my first Skunkworks Friday. Skunkworks Friday is a Materialize sponsored day of the week to spend on personal development and learning. Given that it was my first week, I challenged myself to build something using Materialize. Having spent most of my career working on asynchronous systems, I knew that streaming the results of a TAIL operation to a web browser would be interesting, useful and possibly attainable.
I figured one day would be enough for a proof of concept and that's about where I ended up. It's far from pretty but it shows the concept and that's what I wanted!
What Did I End Up With?
Below is an animation of my browser responding to real-time updates from two different views of Wikipedia edits, computed using the same input source. I even had time to put in a fancy and horribly incorrect (more on that later) visualization for the top10 table:
[caption id="attachment_1667" align="alignnone" width="750"]
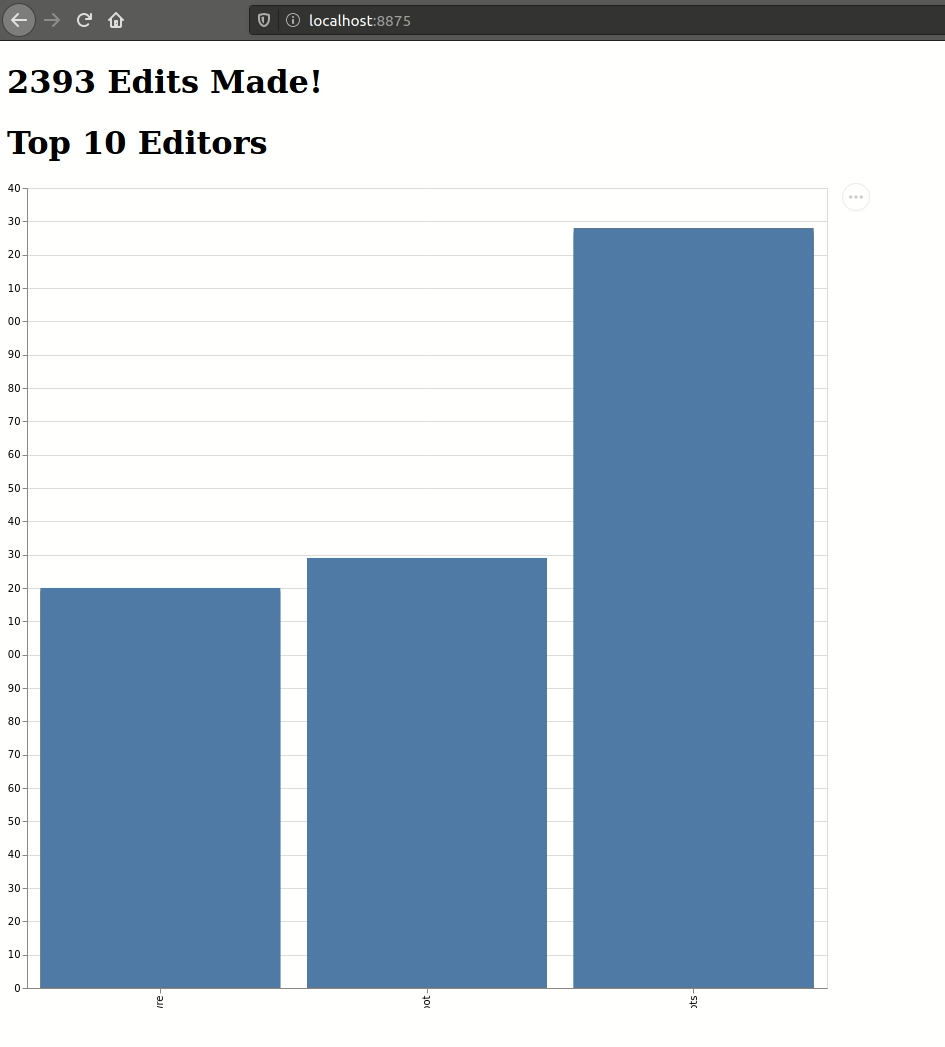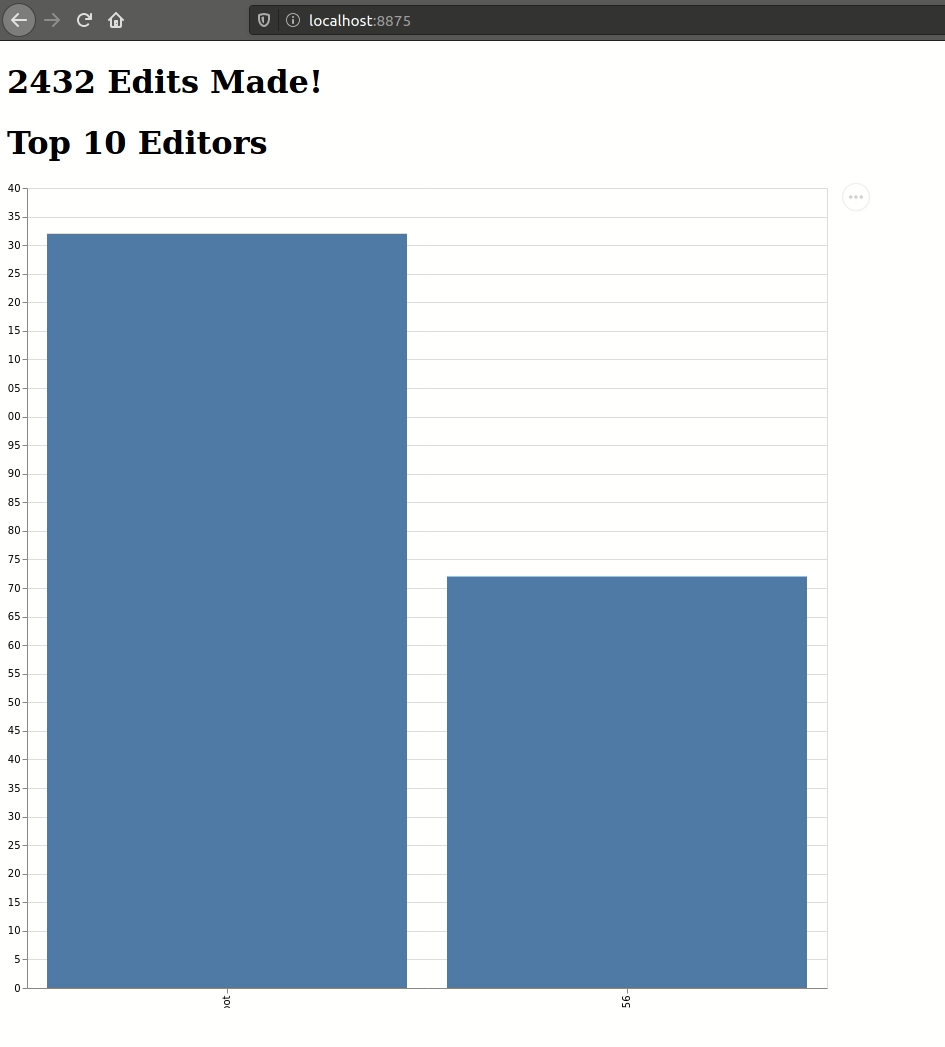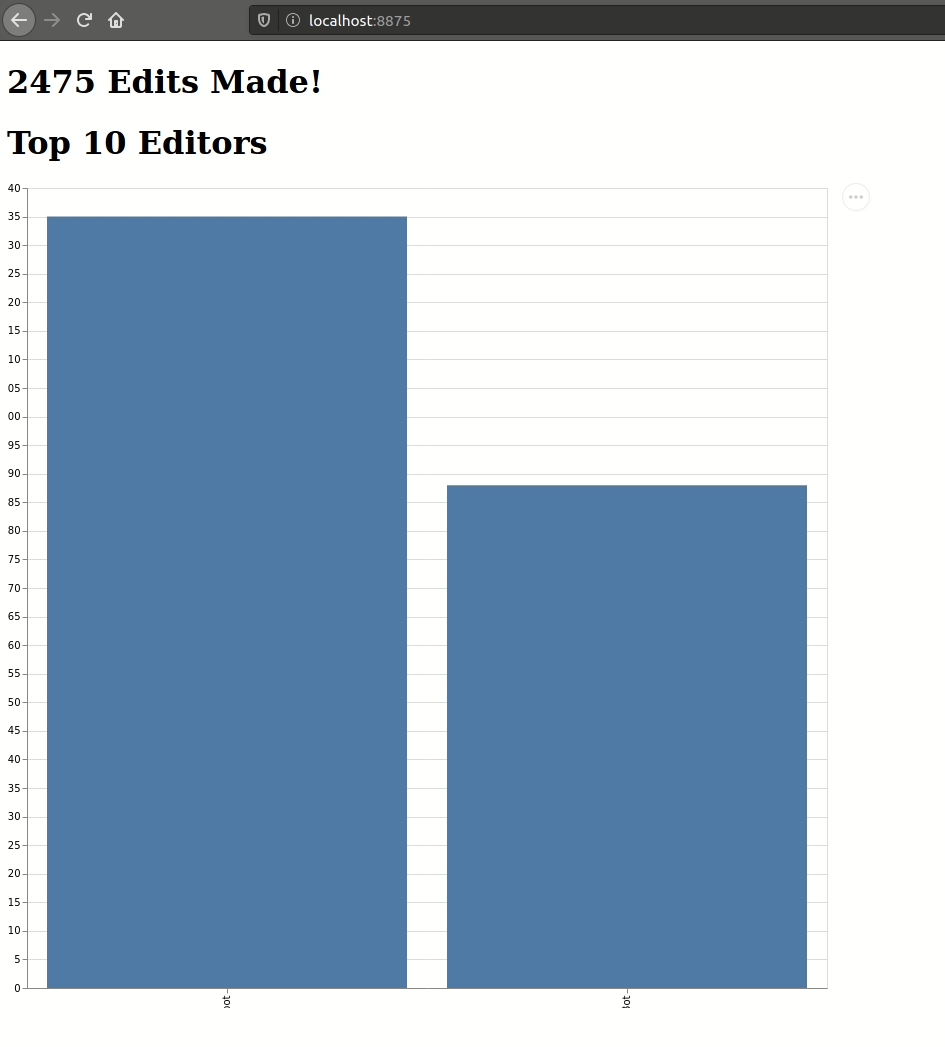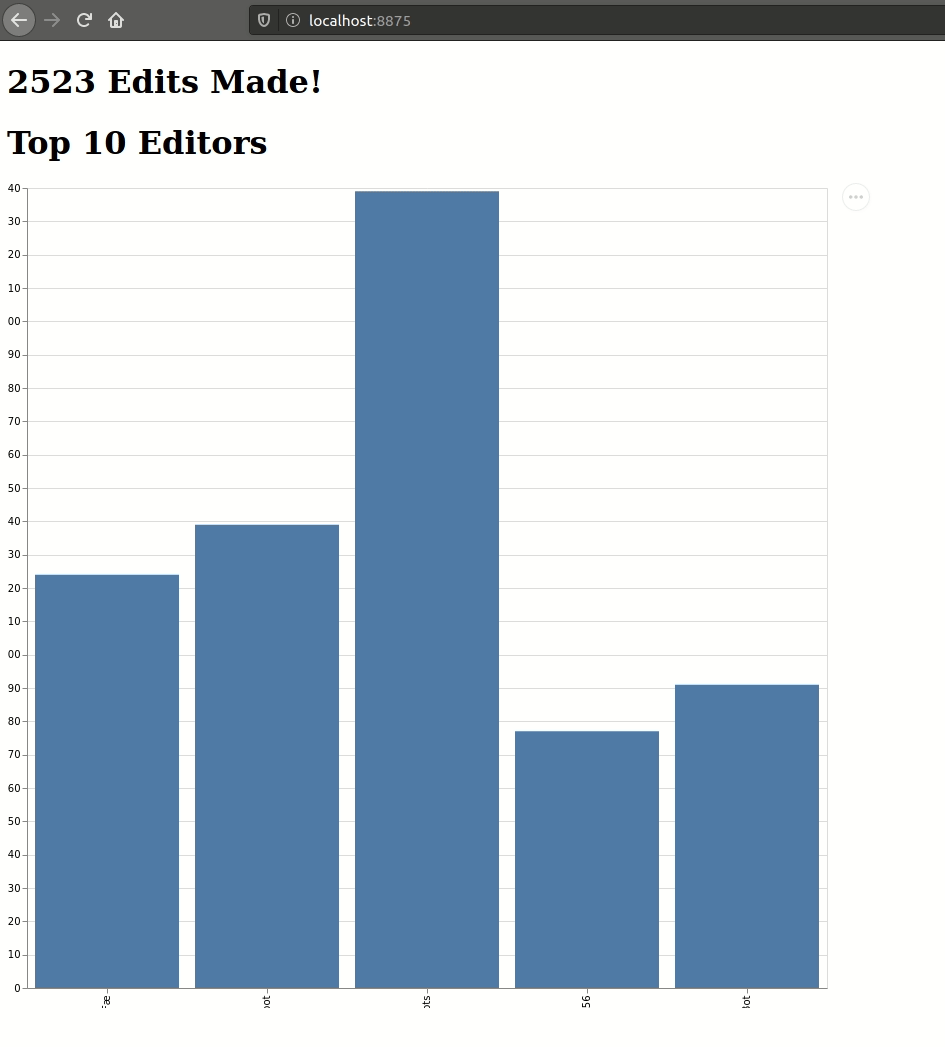
It's alive! If a bit monstrous...[/caption]
The Initial Plan
Now that you've seen the results, let's talk about my initial plan of action.
In past work experiences, I've built real-time, streaming systems using Postgres, psycopg2, Tornado WebServer, Momoko and VegaLite. I opted to reuse these same tools to limit risk and focus on accomplishing my goal.
Bolstered by the documentation for Tailing Through a Driver, I thought it would be pretty simple to do something like the following:
- Start a
materializedinstance and create some interesting views. - Start a Tornado server to serve HTML and run queries against my local
materializedinstance. - Browse to main
indexpage hosted by Tornado, which loads some Javascript to open awebsocketback to Tornado. - The Tornado server responds with initial results of the query and then streams a changelog to the browser.
- The browser updates the DOM as changes are received.
- Time permitting, add a nice visualization using VegaLite.
I casually made my way through the Getting Started Guide before finishing my first cup of coffee. Step 2, however, required multiple cups of coffee.
A Blocking Issue
When writing asynchronous systems, blocking calls are the enemy. In Tornado, a single blocking call stalls the event loop, causing head of line contention and reducing our concurrent web server to serving one request at a time. As such, we must take care to avoid any blocking calls from the main thread.
Initially, I was unconcerned. The typical cure-all for dealing with blocking calls is to wrap the method in a ThreadPoolExecutor and await the results. Sadly, as I started to type up the solution, I realize that I failed to account for psycopg2.copy_expert being a blocking call that never returns. In hindsight, this is obvious: TAIL presents an interface to endlessly stream the inserts and deletes for a view.
My next thought was to start a dedicated thread to create a shared file-like object and block indefinitely inside psycopg2.copy_expert. I figured it would be simple to spin-up a coroutine that implements non-blocking reads of this shared object.
Instead of trying to remember how to write one from scratch, I spent my second cup of coffee reading the Momoko source code in the hopes of inspiration. However, the methods exposed from psycopg2 via momoko are async friendly. When I finally read Thinking pyscopg3 and the linked COPY_EXPERT async issue, I quickly came to realize that this was a bigger battle than I could fight in one day.
In the interests of "just getting something working", I settled on a hack using two Python processes and a POST handler. The first process runs the blocking call to tail, printing the results to stdout. The second process reads from stdin, converting each message to JSON and then POSTing the result to Tornado. It's a hack but it works.
90% Done
Once I had my tail | post hack in place, it was fairly straightforward to broadcast updates from POST to all websocket listeners.
Unfortunately, while it was straightforward to have clients receive live updates, I was unable to fix the visualization buggy behavior. The obvious issue that the top10 visualization doesn't actually have 10 rows. This is because newly connected clients do not actually receive an initially complete view but instead only see updates from after their first connection. This means that the visualization only contains a compacted view of the patch updates rather than a correct view. I plan on fixing this as part of my next Skunkworks Friday project.
Before discussing future work / fixing the last 10%, let's first walk through how the implementation works.
How Does it Actually Work?
In the background, we need to run the following services:
- A
materializedinstance, creating the Wikipedia example views and streaming updates from Wikipedia directly into Materialize. - A local Tornado application.
- Two scripts, one to
POSTchanges fromcounterto Tornado and another toPOSTchanges fromtop10to Tornado.
When a local client connects to Tornado, the following will happen:
- The browser will fetch
index.html, which contains Javascript to open two WebSocket connections, one toapi/v1/stream/counterand another toapi/v1/stream/top10. - When a new message arrives on the
counterlistener, Javascript will search for thecounterelement and replace the inner contents with the new value. - When a new message arrives on the
top10listener, Javascript will update two local arrays,insert_valuesanddelete_valueswith the new updates. - Every 1000 milliseconds, Javascript will generate a Vega Changeset using the
insert_valuesanddelete_valuesarrays to redraw only the elements that have changed.
And other than the glaring, obvious, no-good bug, it works! The source code for this project is available here.
Future Work -- It's Not Perfect
Clearly, if this was anything other than a proof of concept, I would have some work left ahead of me:
- Bug: fix the initial synchronization of state for visualizations.
- Improvement: Try using psycopg3. There has been a lot of recent work on rewriting psycopg with
async/awaitin mind and, as of July 1st, it even has async copy support! This would eliminate the need for thetail | postprocesses by allowing Tornado to callTAILdirectly. - Improvement: add an
HTTP POSTsink tomaterialized. While usingpsycopg3eliminates thetail | postprocesses, these could also be eliminated by adding aPOSTsink that allowsmaterializedto send updates directly to any web server.
Learnings and Conclusion
- It's been a long road for asynchronous Python and we are agonizingly close to having asynchronous web servers that can utilize event driven features in modern databases. Thankfully, it appears that the recent work on psycopg3 promises to address both
LISTEN/NOTIFYuse cases for Postgres and theTAILuse case for Materialize. - Time bounding individual tasks may lead to sub-optimal solutions but it is essential for delivering something in a limited time window. Had I opted to write my own asynchronous handler for
psycopg2.copy_expert, I likely would have ended the day without actually seeing the results of my work. By time-boxing my exploration, I maintained the time necessary to write the Tornado web handlers and Javascript code. - Having dedicated, creative time at work is great for exploring new ideas and can really help people engage with the product. As a father of two under two, I no longer have time for coding outside of work hours. Skunkworks Friday gave me the opportunity to use our product in a fun and creative way.
It might be only me, but websites that update in real-time have a je ne sais quoi that provides a tangible user experience. Today, I described one of many methods for building a data processing pipeline and user experience that update in real-time, but using plain SQL for data transformations! If you like working on these types of experiences, join our community Slack instance because I'd love to hear from you!
