Loan Underwriting: Real-Time Data Architectures

In our first post in this blog series, we examined the current landscape of loan underwriting, including lending methodologies, credit analytics, and the move toward big data and SQL.
Now that you have an understanding of today’s dynamics, let’s look at the actual technology underneath loan underwriting.
Lenders invest heavily in their data architectures, since they often determine the speed of loan decisions. It is about the bottom line: the more loans lenders can fund, the higher their profit margins.
Lenders want to build underwriting technologies based on real-time data, so underwriters can make decisions almost instantly. But reaching that point requires not just expenditures, but also talent and institutional buy-in.
As a result, lenders adopt a number of different data architectures, including traditional data warehouses, streaming databases, microservices, and operational data warehouses.
The following blog will outline all of these different technologies, and how lenders employ them in the loan underwriting process to power real-time data.
For a full overview of underwriting with streaming data, check out our white paper: Loan Underwriting with Real-Time Data.
Analytical Data Warehouse: Batch Processing Slows Loan Decisions
Traditional data warehouses — or ‘analytical’ data warehouses — enable lenders to ingest and transform data based on a batch processing model. In analytical data warehouses, data is stored in tables matching the structure of the writes (inserts, updates), while the computation work occurs on read queries (selects).
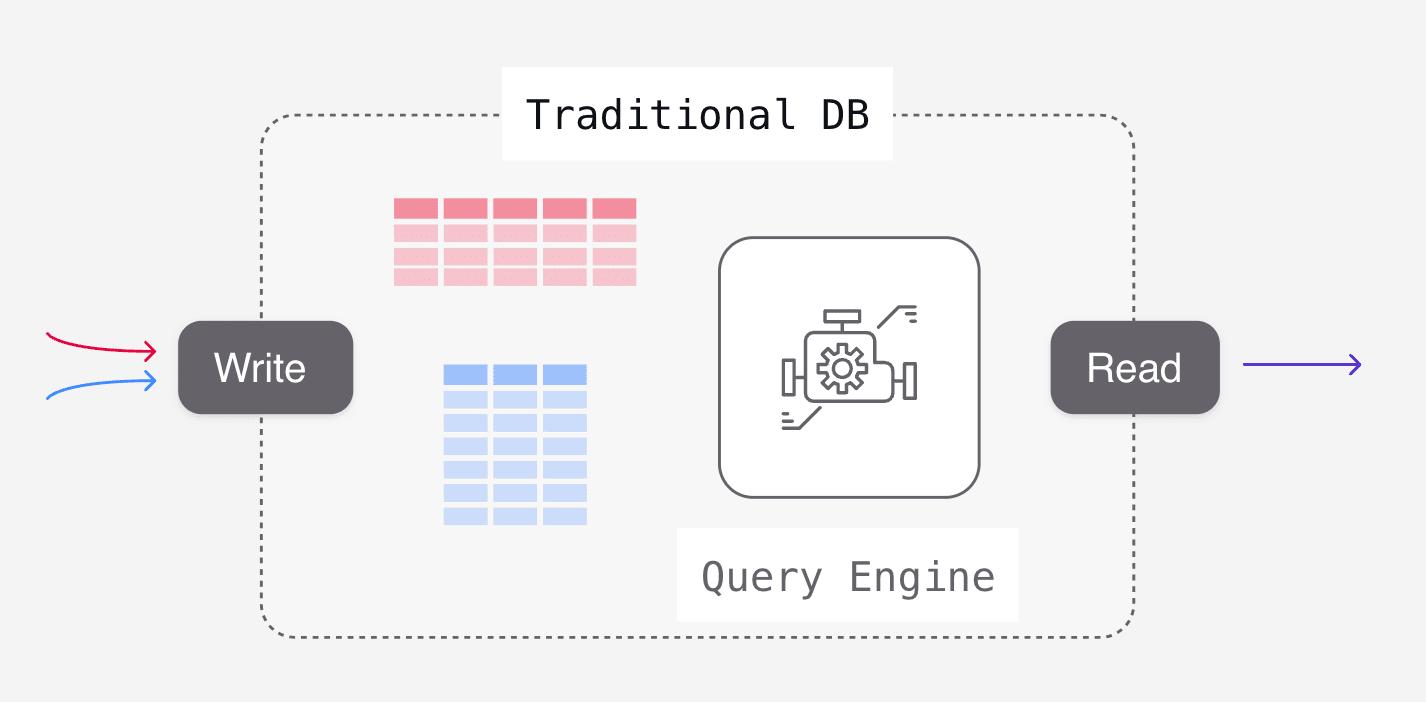
Analytical data warehouses often serve as a starting ground for the SQL logic that powers loan underwriting. They are sandboxes for loan underwriting engines, enabling historical analysis of borrower data, and ad hoc querying. In this environment, lenders can perfect their underwriting models.
However, while analytical data warehouses are agreeable for prototyping SQL, they are not ideal for operationalizing this code. Analytical data warehouses run on batch. Data is updated every few hours, and queries run on intervals. So although SQL queries can make accurate loan determinations, the data is several hours old.
This is much too slow for loan underwriting. In this rapid-fire market, customers will not wait hours for a loan decision. As an alternative, some lenders turn to a brute force option: continually updating and querying data.
This pushes the technical capabilities of traditional data warehouses. At a certain point, limits on data freshness can slow down loan decisioning, driving borrowers to another lender. This brute force option also raises costs significantly.
In loan underwriting, data warehouses must constantly execute SQL queries to make loan determinations. Since traditional data warehouses operate in a pay-per-query pricing scheme, this method quickly becomes expensive.
Analytical data warehouses are either too expensive or too slow for competitive loan underwriting decisions. This is why lenders turn to streaming databases.
Streaming Databases: Difficult to Use for Non-Experts
Streaming databases allow lenders to collect, process, and analyze data streams in real-time, as soon as the data is created. The term can be applied across different classes of databases, including in-memory databases, NoSQL databases, and time-series databases.
Streaming databases first emerged in the capital markets vertical, where the value of fast computation is high. The first versions, such as StreamBase and KX System, were more “event processing frameworks” than databases. They optimized for the unique requirements within hedge funds and trading desks over universality and accessibility.
These streaming databases implemented SQL-like control languages. In StreamBase, resources were created with DDL statements like CREATE INPUT STREAM. But the SQL was just surface-level, because users still needed to be streaming systems experts to harness the database.
The current generation of streaming database tools like ksqlDB and Flink took the SQL control layer implementation further. They allowed users to define transformations in SQL. But users coming from databases still had a lot of challenging streaming concepts to master, like eventual consistency.
With eventual consistency, the results “eventually” match all of the data inputs. In loan underwriting, a SQL rule could fail or pass temporarily, because it has not captured all of the data inputs. In other words, transformations occur without all the necessary borrower data. If the rule is connected to an automated underwriting system, the wrong loan applications could get funded. This is how eventual consistency can lead to costly borrower defaults.
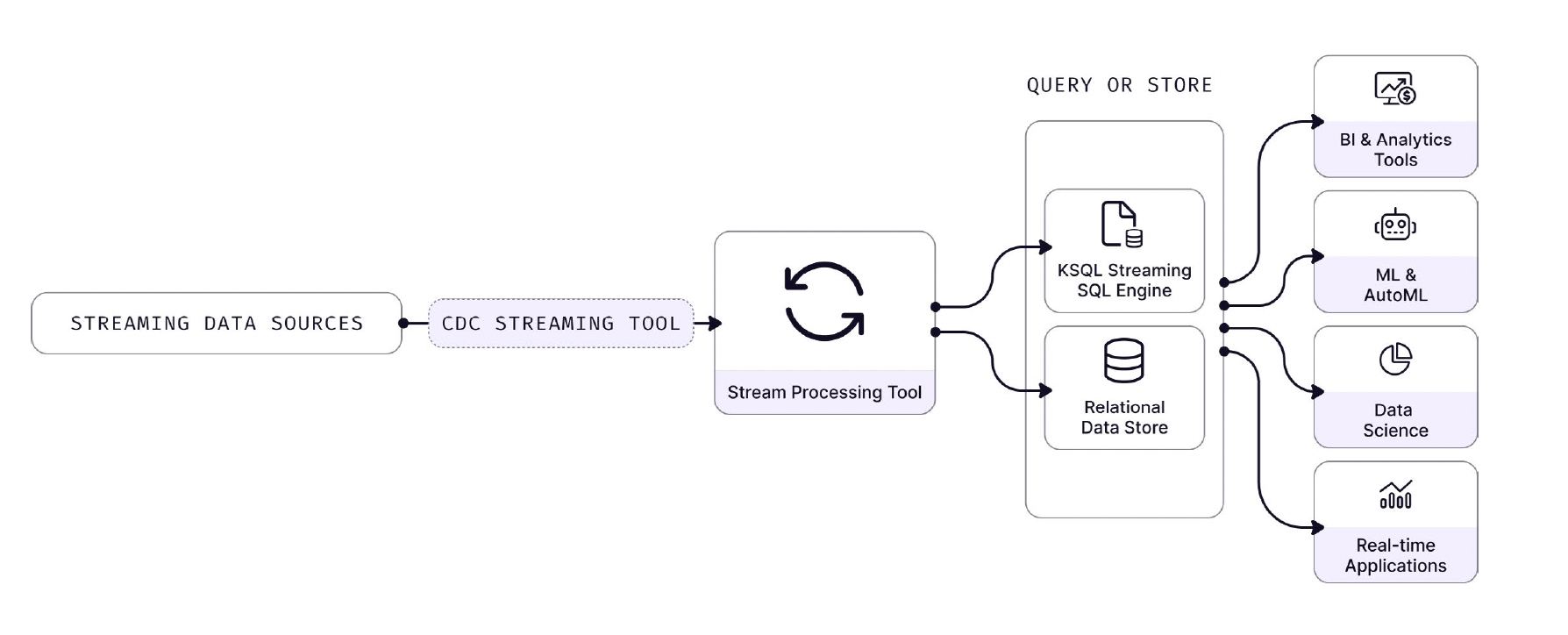
Streaming databases enable lenders to leverage borrower data in real-time. This can allow for faster loan determinations. However, data team members can have trouble harnessing streaming DBs, due to foreign database concepts and obscure programming languages such as Scala..
This makes it more difficult to create and modify loan underwriting models, and can lead to unintended errors. So although streaming databases make it easier to access real-time borrower data, non-experts have a difficult time manipulating and programming the database to engage in effective loan underwriting.
Microservices: Faster But More Expensive
Due to the limitations of traditional data warehouses and streaming services, lenders turn to microservices to achieve faster decision times.
Microservices are a type of software architecture composed of small independent services that communicate over well-defined APIs. Lenders turn to microservices to build out loan underwriting systems that combine databases, backend and front end systems, APIs, and other data infrastructure.
Each API serves a function in the underwriting process, such as identity verification. From the front end, underwriters enter borrower data and initiate loan determinations. The loan underwriting system calls these APIs when the underwriter has requested a loan check.
On the back end, this queries the APIs and any other relevant databases to provide underwriters with loan determinations.
For many lenders, microservices operate as a ‘batch-on-demand’ model. The data runs on batch, whenever underwriters request loan checks on the front-end. This on-demand functionality leads to faster loan determinations. The batch runs whenever necessary, so loan determinations can take minutes, rather than hours as with a traditional data warehouse.
A benefit of microservices is the ability to employ popular programming languages, such as standard SQL. This empowers data analysts and finance coders to easily build dbt models for underwriting. Analysts can add, modify, and delete SQL logic as underwriting rules change.
However, microservices are expensive and oftentimes difficult to maintain. With so many different data products, and bespoke requirements, microservices require significant engineering resources and budget overhead to operate. Microservices can also become unwieldy and susceptible to dysfunction.
Once a lender has built out a sub-minute microservices architecture, other factors start to impact decisioning time. If a lender introduces too many SQL rules, for instance, the load can have a material impact on latency. In this scenario, lenders must choose between highly competitive speeds, or highly refined underwriting models. The former will fund more loans, the latter will fund more accurate loans.
But what if you could have both? Loan decisions in seconds, and underwriting models with thousands of SQL rules. That would allow lenders to fund the best possible loans at the fastest possible speeds, boosting profit margins considerably.
It sounds like a theoretical best-of-both-worlds scenario. But with the emergence of operational data warehouses, this is quickly becoming a reality for lenders.
Operational Data Warehouse: Beat the Competition with Sub-Second Loan Decisions
Operational data warehouses such as Materialize combine streaming data with SQL support, allowing lenders to continuously transform data with sub-second latency. Lenders harness Materialize to deliver loan determinations to underwriters in seconds or even milliseconds, rather than minutes or hours.
Unlike traditional data warehouses, operational data warehouses such as Materialize move the work to the ‘write’ side. Instead of just storing data on writes, a streaming database asks for the queries upfront (in the form of Materialized Views) and incrementally updates results as input data arrives.
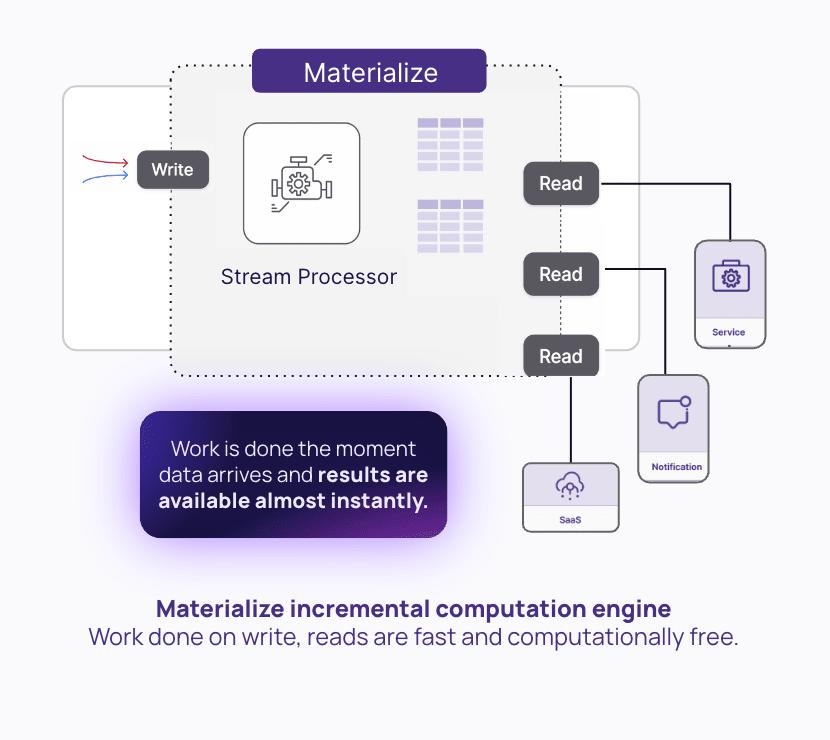
Materialize leverages streaming data to deliver real-time loan decisioning data to underwriters. By employing change data capture (CDC), Materialize refreshes data as soon as it changes in a source database, enabling access to the most up-to-date borrower data at all times.
Unlike streaming databases, Materialize offers full SQL support, empowering the data team to build SQL underwriting rules with ease. Materialize enables lenders to continuously execute their SQL underwriting rules against real-time data, providing underwriters with loan determinations near instantly.
With analytical data warehouses, executing SQL queries with high frequency will drive up compute costs considerably. Materialize is designed to avoid this kind of constant query recomputation. Instead, Materialize leverages incrementally maintained views to decouple the cost of compute and data freshness.
Materialize incrementally updates materialized views and indexes to keep them fresh. Instead of re-running the query, Materialize only updates the data that has changed. This ensures the query output is correct, while keeping costs down considerably, by requiring less compute resources.
Materialize provides lenders with the data freshness they need to make near instant loan determinations. Lenders need the time between data input to corresponding output to be less than 1 second. Materialize enables underwriters to request a loan determination and receive the data in less than a second. This allows lenders to fund more loans, and improve their profit margins.
Materialize also offers the consistency lenders need to make fast, accurate loan decisions. In streaming databases, the results do not always match the input data, something called eventual consistency. But if a loan determination is incorrect, lenders might fund bad deals, and lose money. Lenders need the total consistency offered by Materialize. With strong consistency, the results always match the input data, so lenders can deliver accurate sub-second loan determinations.
Materialize’s responsiveness allows it to return results nearly instantly. Lenders make loan determinations with standard backend apps that do dynamic lookups against a database. With Materialize, they can perform queries directly without needing to include a serving database.
Materialize also allows lenders to port over existing SQL logic with dbt. Unlike other streaming databases, Materialize’s full SQL support enables lenders to keep their SQL rules intact, so they don’t have to rewrite them in a cumbersome programming language. Materialize is PostgreSQL wire compatible, and can integrate with any PostgreSQL tool.
With Materialize, lenders can add thousands of SQL rules by sharing indexes. If a table or view is referenced multiple times, lenders can create an index for it and share it across all downstream views that reference it. This can save lenders a significant amount of CPU and memory resources. Underwriters can deploy thousands of the most precise underwriting rules and still receive loan determinations in under a second. This allows lenders to fund more accurate loans, much faster than the competition.
Download Our Free White Paper Now!
In today’s highly competitive lending space, shaving a few seconds off loan decisioning times can result in millions in profits. This need to achieve sub-second latency has driven lenders to a diverse set of solutions.
But only an operational data warehouse like Materialize can maximize speed and accuracy in underwriting. With Materialize, underwriters perform loan decisions in milliseconds or seconds, instead of minutes or hours.
Materialize enables lenders to make more accurate loan decisions and achieve the fastest speeds possible. This empowers lenders to expand profit margins in a space that rewards operational efficiencies.
To learn more, you can download our free white paper — Loan Underwriting with Real-Time Data — for a full overview.
