Low-latency Context Engineering for Production AI

As the success of AI agents in the enterprise increasingly depends on how efficiently they can turn tokens into value, it's becoming clear that the limiting factor is the ability to transform operational data into fresh context.
The inputs to context are often fragmented across numerous databases, APIs, and microservices. With enough time and talent, you can solve the integration problem, but you still have to navigate the latency budget, those precious few moments where a customer waits while an agent gathers context, thinks, and responds. For instance, a payment processor may have just one second to approve a transaction, or a conversational agent may have a second or two before a customer loses patience. Exceeding these limits sacrifices conversion rates, revenue, and trust.
Why Traditional Architectures Break Down
As AI systems move into production, they demand richer context to ground them. However, providing this context in practice quickly runs up against latency budgets, as traditional architectures force a difficult choice. You can have agents query multiple databases at inference time, where data is fresh but complex agent queries are slow. Or you can point agents at a lakehouse to quickly query integrated data, which can be minutes or hours old. Either way, total end-to-end latency suffers.

FIGURE 1: Time for context to correctly reflect an update
There aren’t a lot of great options to get everything needed for the ideal context with a latency budget, so teams take shortcuts. They approximate data, accept stale inputs, or sacrifice correctness for latency. All of these ultimately lead to marginally worse agentic decision-making that compounds over time.
Introducing Materialize for Context Engineering
Materialize provides a fundamentally different approach. Engineers can integrate, join, and transform raw source data with SQL, creating views that represent canonical business objects like customers, orders, and portfolios. As updates occur in operational systems, Materialize continually and incrementally maintains these views, performing only the minimal computation required to keep these complex context representations current.
Materialize supports creating live data products using multi-way joins, complex aggregations, and even recursive queries that would normally take minutes in traditional operational databases. Agents can further query and transform views on the fly with SQL, so you don't need to define everything up front.
Technically, operational databases will always have fresher data (there's a replication hop to Materialize) and can join and transform data faster. However, Materialize still delivers superior end-to-end latency by precomputing and incrementally updating views, rather than starting from scratch for each request. This means you get the data freshness of an OLTP system with the last-mile context assembly of a data warehouse, giving agents millisecond level access to context that is sub-second fresh. This gives you the ability to do far more within your latency budget for context delivery without shortcuts that compromise the quality of agent decisions.

FIGURE 2: Time for context to correctly reflect an update with Materialize
Building a Live Data Layer for Context Engineering
With Materialize, views can be thought of as live data products: contextual building blocks that can be composed into more complex structures. For example, a manufacturing line can be rolled up into a plant, which can then be rolled up into a broader representation of the entire supply chain. Since Materialize does the heavy lifting continuously, you can build these complex hierarchies efficiently and maintain them incrementally.
Ultimately, this creates a semantic representation of your business, a digital twin that's up-to-date within seconds of real-world changes. For production AI deployments, these digital twins of your business must live in operational space. That means they need to be fresh enough to reflect current reality, yet fast enough to serve online requests for final context at agent scale. This would be utterly impossible to create using traditional infrastructure.
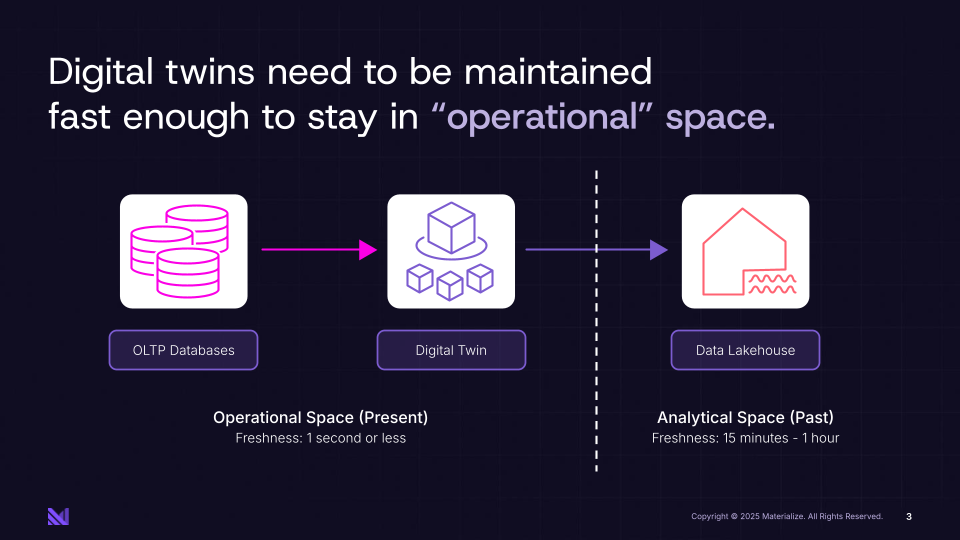
FIGURE 3: Digital twins need to be maintained fast enough to stay in "operational" space
Different teams can define their own contextual building blocks or consume from existing ones, composing them together to build even richer context. This is an operational take on the data mesh context, with a focus on online services not BI.
Production Results
We see many examples of our customers using Materialize to squeeze far more work into their latency budgets. Neo Financial enhanced their fraud detection pipeline to achieve millisecond access to fresh context, significantly reducing fraud losses and infrastructure costs. Vontive compressed the time to provide context around loan eligibility by 98% improvement, allowing them to include richer context in their eligibility process.
The Future of Operational Intelligence
As enterprises move beyond AI prototypes into production, the bottleneck isn't model quality, it's context. The organizations that win will be those who can feed their models the richest, freshest context that reflects their business at the current moment all without breaking their latency budget.
More broadly, Materialize isn't just solving a latency problem. It's providing the architectural foundation for context engineering that production AI demands. If you’d like to learn more about this, checkout the product overview or book a demo.
