OLTP Queries: Transfer Expensive Workloads to Materialize

In our last blog in this OLTP series, we discussed the problems with running complex queries on OLTP databases. In this blog, we will take a look at the solution: OLTP offload.
There are many different methods for OLTP offload, and in the following blog, we will examine the most popular options.
For a full overview of OLTP offload, download our free white paper - OLTP Offload: Optimize Your Transaction-Based Databases.
Workaround #1: Perform Queries On Core Database
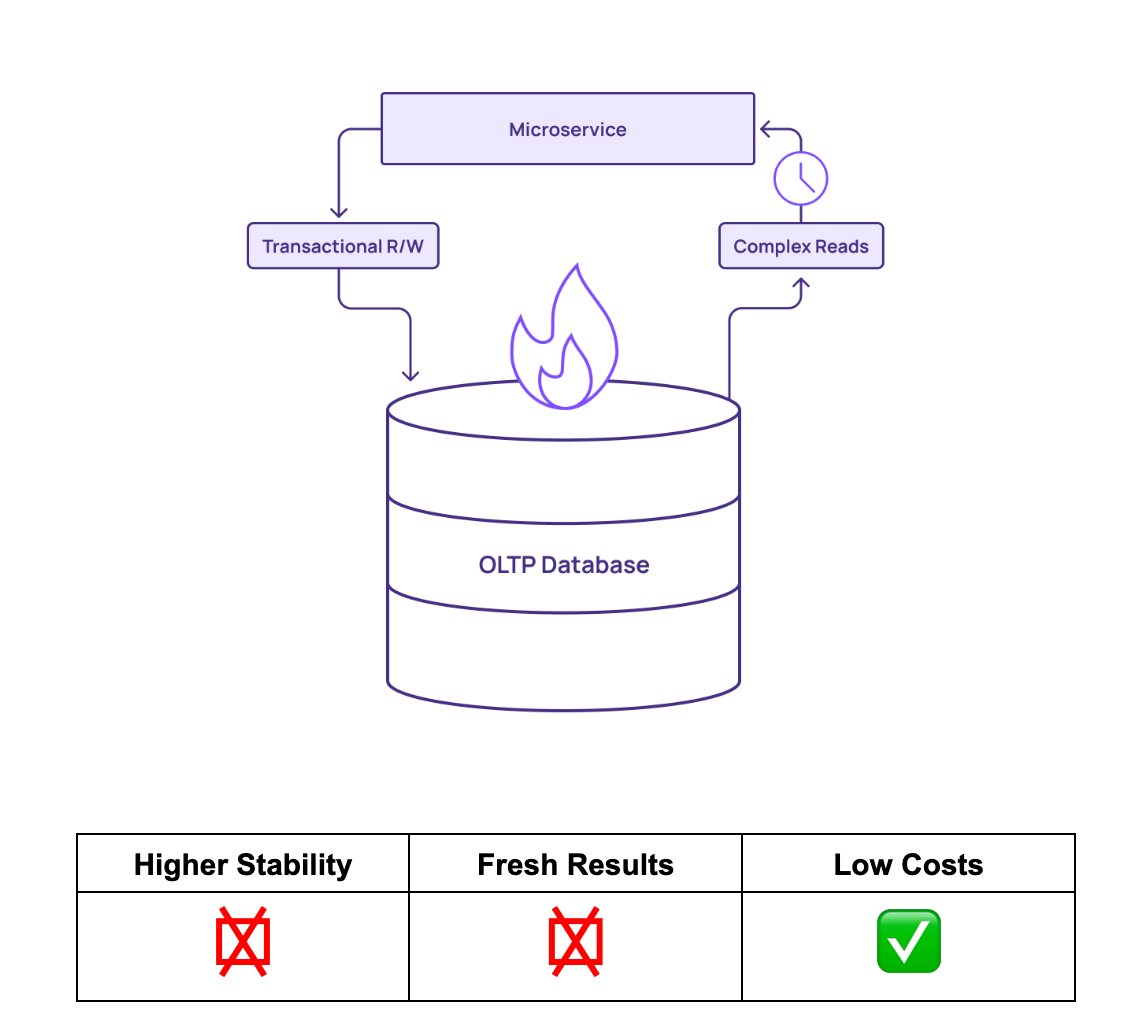
First, there’s the option of performing the queries on the core OLTP database itself. In this scenario, complex queries are run directly on the OLTP database.
The core database that handles the operational read and write workloads also handles the more expensive analytical queries. No effort is made to offset the impact of high compute workloads on the database.
This can lead to major issues, including:
- Additional indexes to support faster complex reads mean longer write operations, since each index must be updated on write.
- Denormalization jobs, taking data from the core OLTP and writing back to reporting tables, takes up developer time and adds complexity.
- Materialized views can essentially do the up front denormalization work, but that comes at a cost when the view is refreshed. Fresher data means more load on the database.
When you perform queries in-place, data freshness suffers, UIs won’t match customer actions, and reports are out of date. Updating the materialized view also creates load on the database. As you recompute views more frequently to get fresher results, you’re basically just re-running queries constantly.
Workaround #2: Scale OLTP Database
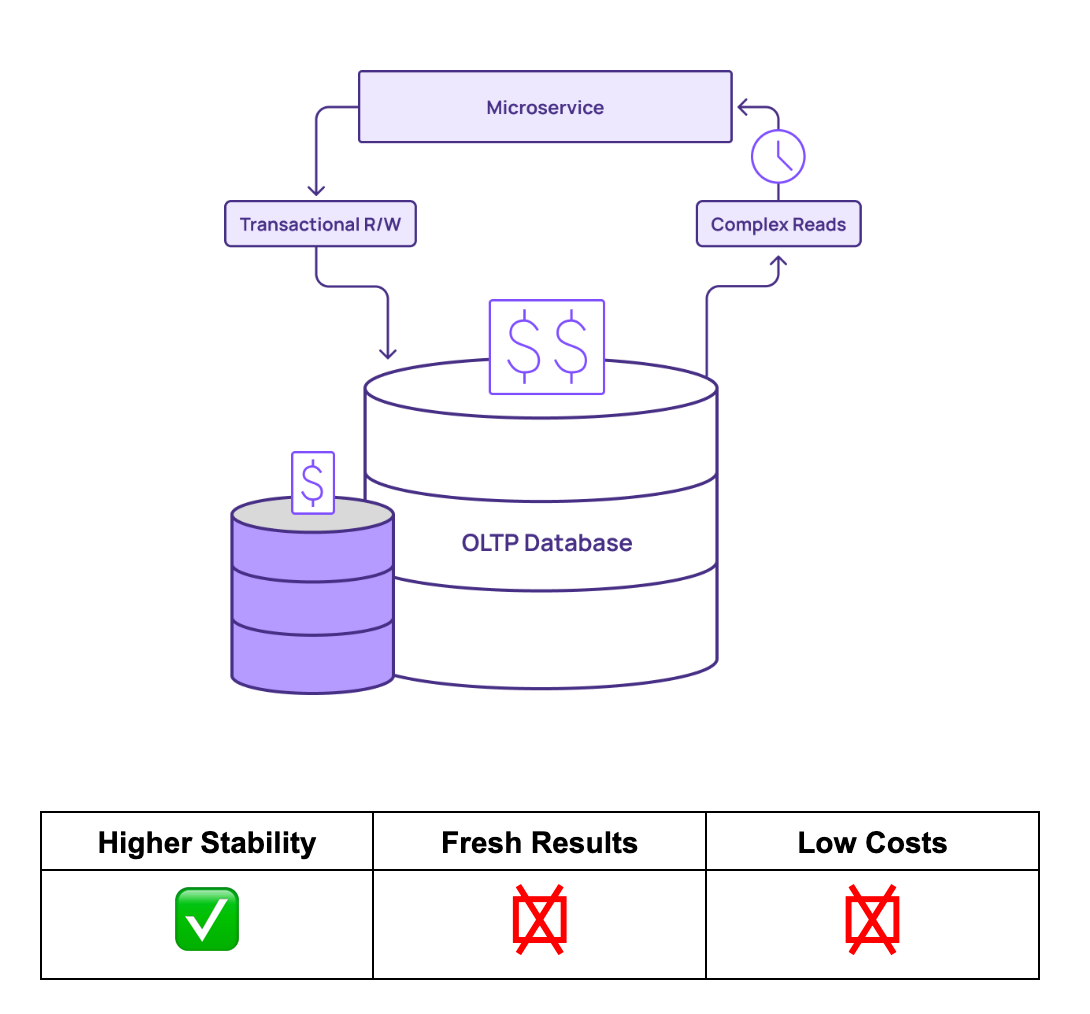
Once teams have exhausted the resources of their OLTP database, they might choose to scale up to a bigger machine. Bigger machines are better able to handle the query load. This could lead to more reliable service and less downtime. However, the queries are still being performed on the core database of record, and this can result in a number of issues:
- Databases are not cheap to scale up. The price/performance ratio in regards to the complex query might be unfavorable.
- Complex, high compute queries still take longer to perform on the OLTP architecture, slowing down services.
- Teams eventually reach a hard limit on how much they scale their database.
By simply scaling up databases, teams can reconcile some stability problems, but high latency can still become an issue. As a result, data freshness suffers, and results are stale. Additionally, scaling up machines can become expensive quickly as the demands of complex queries continue to rise.
Workaround #3: Read Replica
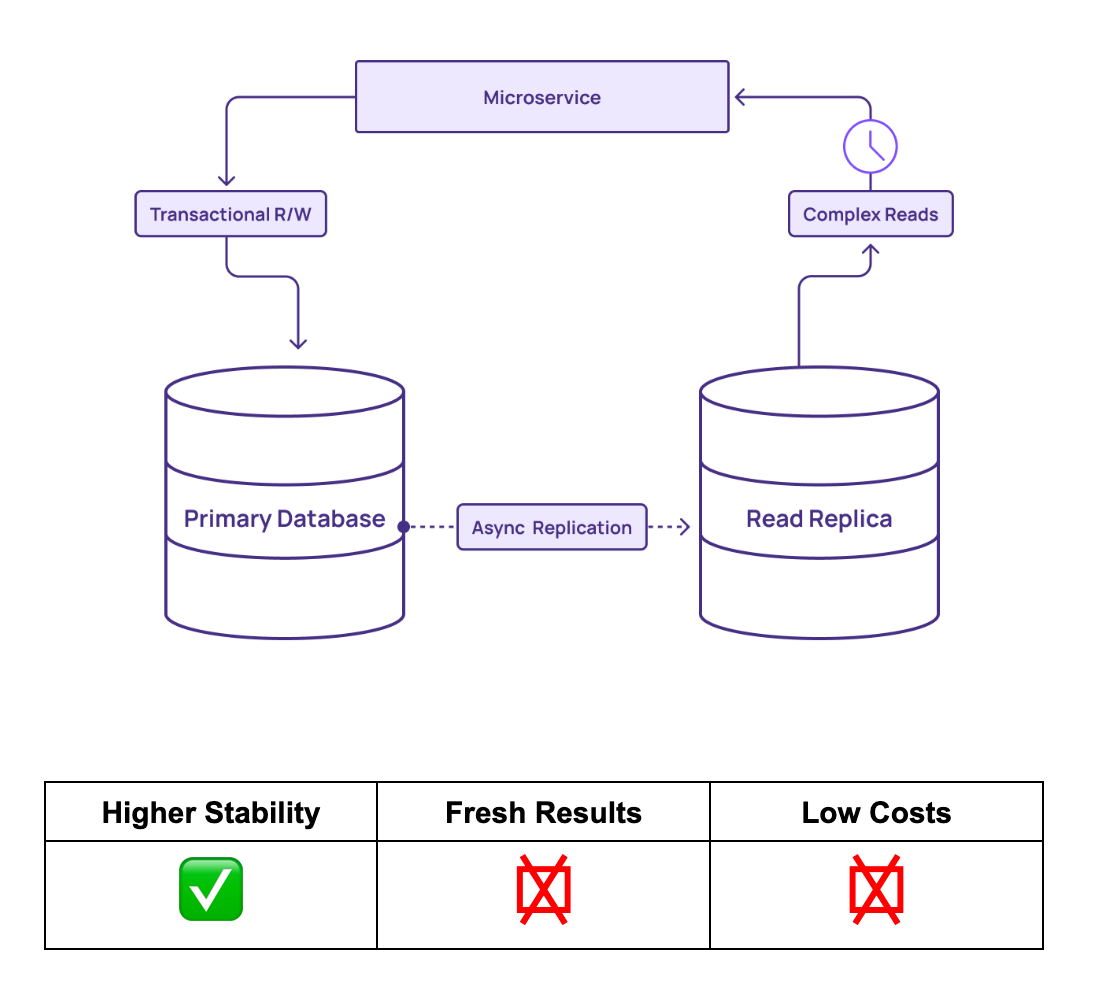
Read replicas are the common method for offloading read-heavy workloads from an OLTP system. By replicating the database to one or more read-only copies, businesses can distribute the read load and alleviate stress on the primary OLTP database. However, this approach comes with significant trade-offs:
- The replicated database is still using the same architecture as the primary. So if the primary could not return a complex aggregation in a fast enough time, the replica may not be able to either. You could scale up the read replica, but that introduces cost and still might provide services too slowly.
- You can store many indexes on the read replica. This will help speed up the queries, but the queries will still take longer to return as the data size grows. Writes become slower as a result. This slows down the primary database if the replication is synchronous. You can configure the replication to be asynchronous, but then you must contend with eventual consistency.
- Read replicas increase infrastructure costs, and the ROI may not be there. Each replica consumes storage and computational resources, which can become expensive as the number of replicas grows. If you can’t get high utilization of these replicas, you may be wasting resources.
Read replicas can help relieve the load from OLTP systems, increasing database stability. But because read replicas share the same design as the original OLTP database, they still perform queries with high latency. Services can remain slow, even though teams spend more money on hosting the read replica.
Workaround #4: Analytical Data Warehouse
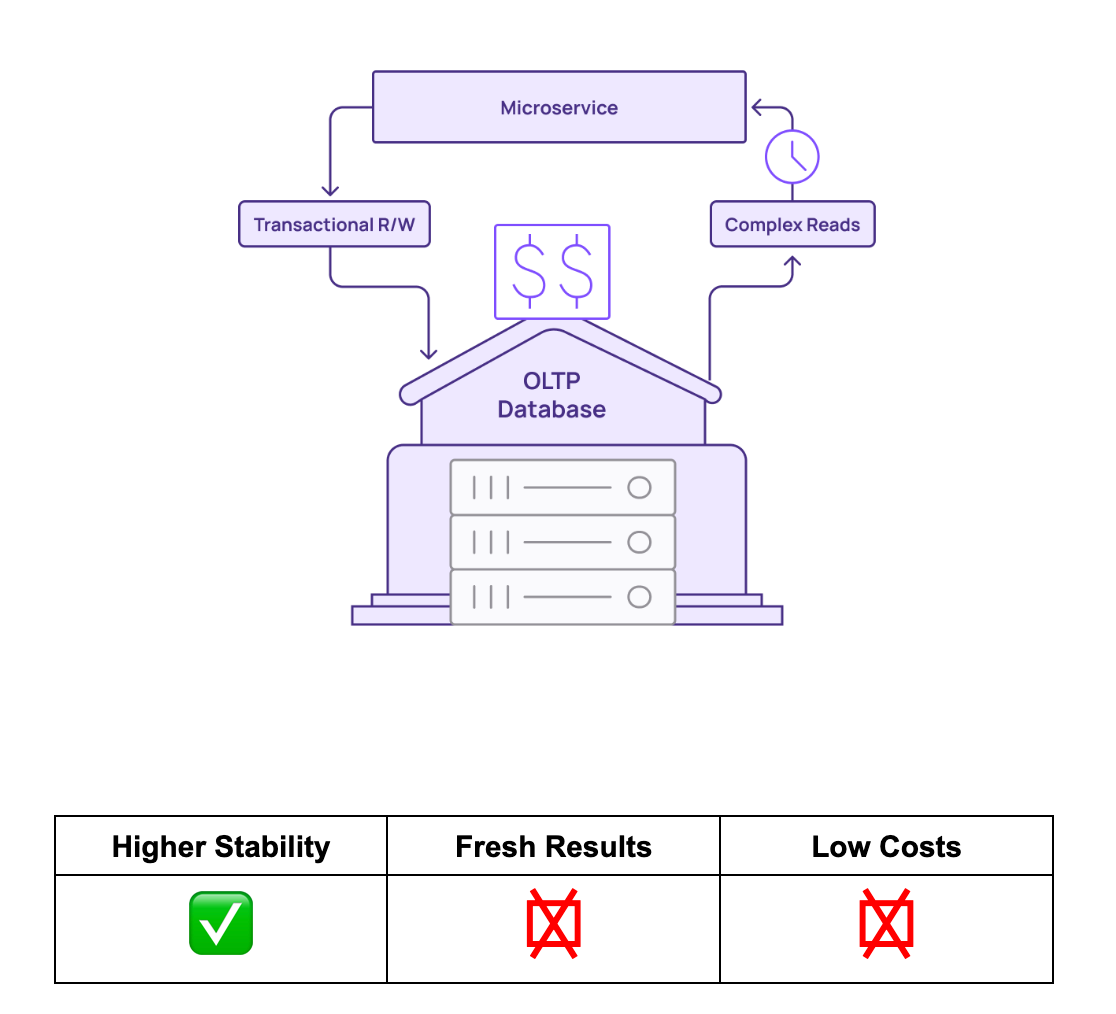
Complex queries are not ideal for OLTP systems.l, but analytical data warehouses are built for these kinds of queries. Teams can perfect SQL logic in their analytical data warehouses using historical data. It’s also not uncommon for teams to use analytical data warehouses to perform OLTP offload.
Although analytical data warehouses offer more stability than OLTP systems, they also come with their own limitations:
- Analytical data warehouses eventually reach a hard limit on data freshness. They run on batch processing, and to approach the freshness needed for OLTP, they must constantly run data updates. Although this generates fresher data, the data updates can only occur so fast. This leads to inadequate data freshness.
- Operating in a pay-per-query pricing scheme, analytical data warehouses can generate high costs when performing OLTP offload. Constantly re-executing queries and updating data for fresh results can create a growing cost center.
Analytical data warehouses can handle the complex queries that overwhelm transactional systems. But issues with data freshness and costs make them a less appealing choice for OLTP offload.
Materialize: Operational Data Warehouse for OLTP Offload
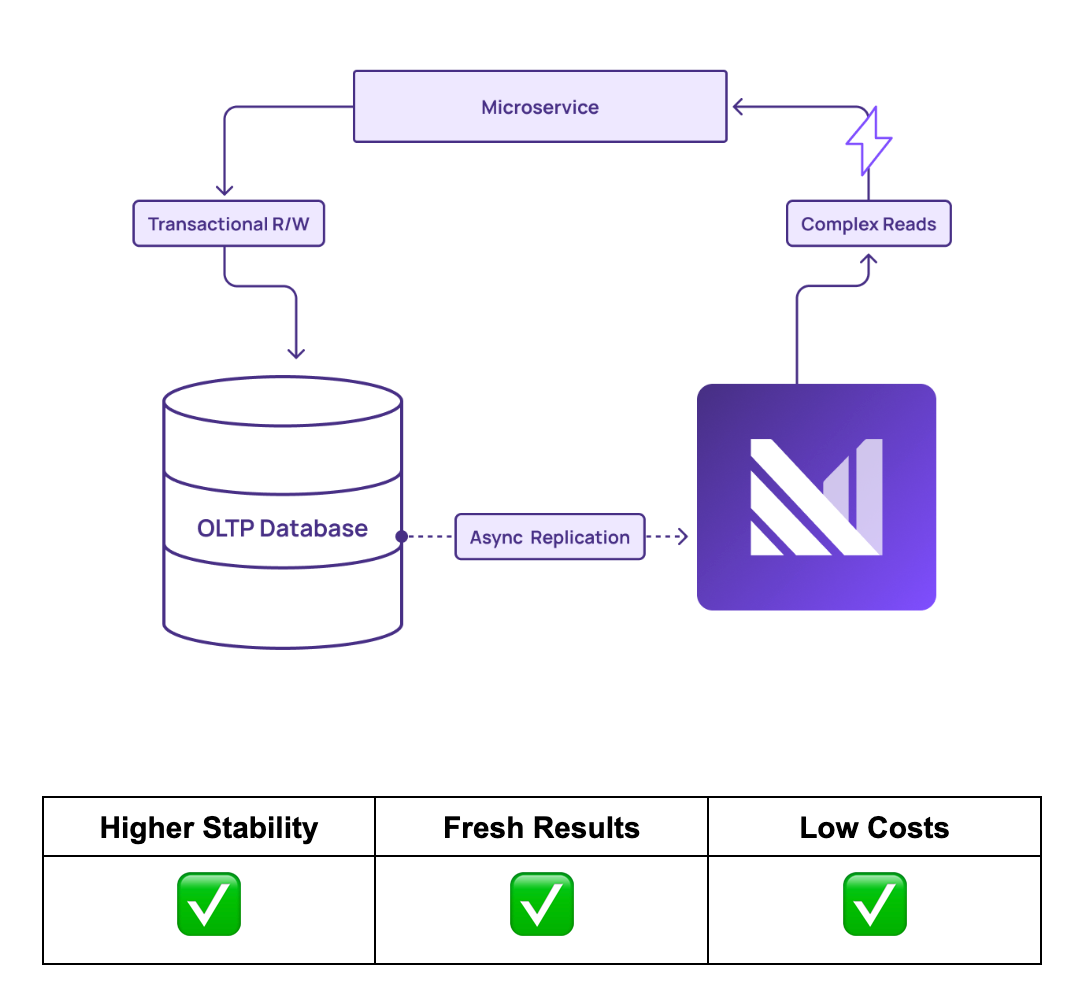
By offloading the queries from an OLTP system to Materialize, organizations can improve the resilience and performance of their core services while ensuring fast and fresh query results. Materialize enables a more efficient and reliable data handling process, keeping core operations smooth and responsive.
Materialize combines the power of streaming data with SQL support. With Materialize, teams can access the familiar interface of a data warehouse, but powered by fresh data, as opposed to batch data warehouses that update data every few hours.
Materialize achieves the low latency necessary to achieve parity with the speed of OLTP systems. Results are returned by Materialize in milliseconds, the same range as OLTP databases. This ensures business operations and transactional systems remain unbroken. Conversely, batch data warehouses return results in seconds, minutes, or hours, too slow for a transaction-based system of record.
As a data warehouse, Materialize is also able to handle complex queries. One of the benefits of the data warehouse architecture is its ability to perform complicated joins and aggregations across millions of records. However, traditional data warehouses cannot perform these queries over fresh data, meaning the results are out-of-date. But Materialize executes arbitrarily complex queries over streaming data, meaning the results are fresh enough to be used in OLTP workflows.
When OLTP databases experience reliability issues, consistency can suffer, and incorrect results can be recorded in the system. Materialize adheres to strong consistency, meaning that results always match the corresponding data inputs. Materialize also offers real-time recency. This guarantees strong consistency, even with aysnc replication. Materialize’s consistency guarantees mean that the results of complex queries are always correct, matching the accuracy needed for OLTP systems.
Materialized views are sometimes used on OLTP systems to denormalize data and commit it to memory, where it can be accessed repeatedly. However, materialized views are not automatically updated, meaning the data is not fresh, and insufficiently up-to-date for OLTP transactions. Leveraging Incremental View Maintenance (IVM), Materialize incrementally updates materialized views as new data streams into the system. This limits the amount of work the data warehouse does, and allows materialized views to always stay up-to-date.
This is how Materialize decouples cost from query freshness. Teams can harness materialized views in Materialize to perform complex OLTP queries at a fraction of the cost. At the same time, the requisite data freshness is maintained for OLTP transactions.
With Materialize, teams can implement a Command Query Responsibility Segregation (CQRS) pattern that sends the writes to the core database, and the reads to Materialize. This allows teams to save money by scaling down their main database. This also leads to happy customers, due to extremely fresh views. No matter how popular these reports become, the core database can always keep up.
When teams do not want to introduce a new service to call, they can expose the view supporting their app as a table directly in the database using a postgres feature called a foreign data wrapper. Now they get all the benefits of Materialize, without requiring their app to directly call a new service.
With Materialize, teams can offload complex queries from their OLTP systems, and cost-effectively perform them with millisecond latency. This allows OLTPs to execute simple read/write operations, without straining the transaction systems. Materialize handles the complicated reads that would otherwise negatively impact the performance and reliability of the OLTP database.
Download Free White Paper
OLTP systems are built for simple queries that handle insertions, updates, and deletions. But as a rich store of operational data, OLTP databases inevitably inspire complex queries. However, complex queries are expensive, and negatively impact performance, reliability, and data freshness.
Materialize empowers you offload your expensive OLTP queries onto a real-time data warehouse. This allows you to perform complex queries on fresh data at a fraction of the cost, enabling you to successfully offload expensive workloads from OLTPs, without breaking operational workflows.
Download our free white paper — OLTP Offload: Optimize Your Transaction-Based Databases — for a full overview of OLTP offloading.
