How Materialize Unlocks Private Kafka Connectivity via PrivateLink and SSH
June 10, 2024

At Materialize, we’ve built a data warehouse that runs on real-time data. Our customers use this real-time data to power critical business use cases, from fraud detection, to dynamic pricing, to loan underwriting.
To provide our customers with streaming data, we have first-class support for loading and unloading data via Apache Kafka, the de facto standard for transit for real-time data. Because of the sensitivity of their data, our customers require strong encryption and authentication schemes at a minimum. Many of our customers go one step further and require that no data is loaded or unloaded over the public internet.
But unfortunately, Kafka and private networking do not play well together. Traditional private networking technologies like VPNs and VPC peering don't work with Materialize's multi-tenant architecture, and newer cloud-native technologies like AWS PrivateLink require delicate and complex reconfigurations.
As a result, the Materialize team built the first managed service that can securely connect to any Kafka cluster over AWS PrivateLink without requiring any broker configuration changes. We’ve already contributed the required changes back to the open source community. But in this blog post, we’ll take a deeper look at how we reconciled Kafka with private networking.
The post will examine why teams historically needed delicate network and broker configurations to connect to Kafka clusters. We’ll also detail how this method impacted the stability of network configurations. Then we’ll explain how we developed frictionless private networking for Kafka by using librdkafka.
Private Network Connectivity Options for Kafka Clusters
There is a whole spectrum of options to expose Kafka clusters over a private network. These can range from Transit Gateways and VPC peering, to PrivateLink and SSH bastions.
Transit Gateways, VPC peering, and VPN connections are on one end of the spectrum. They use generic networking configuration not specific to Kafka. This makes them easily understandable, but not always simple to set up. These options work well if you’re comfortable establishing connectivity between the networks of clients and brokers. But for the Materialize team, these methods come with too many practical limitations. Customers may not be willing or able to expose their entire subnet and all the applications that live in those subnets to us. Moreover, because of the high number of connected networks and overlapping CIDR ranges between networks, it may not be possible to connect the networks. Just consider how many customers would try to claim the standard IPv4 CIDR of 10.0.0.0/16.
Establishing connectivity through PrivateLink is on the other end of the spectrum. With PrivateLink, only a single endpoint is exposed to clients, rather than the entire network. PrivateLink also works in more challenging environments, such as networks with overlapping CIDR ranges.
Although PrivateLink offers more security and flexibility, it requires additional configuration of the cluster and client networks to work properly, unless you can use native PrivateLink support of a managed Kafka provider of your choice. Client networks need to install the appropriate DNS entries for the brokers. The brokers need to apply bespoke configurations that change how they respond to metadata requests. Even more annoying, these configurations need to be kept in sync with the cluster configuration, like when the cluster scales or brokers are added or removed. You can get around these steps by using native PrivateLink support with a managed Kafka provider, but this option isn’t always available.
For Materialize’s multi-tenant architecture, PrivateLink was the only viable option for private connectivity initially. But we wanted to avoid forcing complex downstream configuration changes on our customers. So we set out to find a more seamless way to support Kafka over PrivateLink.
Much of the complexity involves redirecting traffic to the interface endpoint in a transparent way. This is because clients cannot connect directly to brokers. However, if clients redirect the traffic directly instead of in the networking layer, the manual configuration changes are no longer required. In the end, we introduced a change to librdkafka that enables customer broker name DNS resolution directly in the client. This change removes the need for bespoke broker and networking configurations, while still keeping the cluster exposed. This same technique also simplifies connectivity through SSH bastions.
The Root of All Evil: Load Balancer in Front of Cluster
Before we examine our changes to librdkafka, let's first understand why custom configurations are required in the first place.
A prerequisite of PrivateLink is a Network Load Balancer that fronts the exposed cluster. That's just how PrivateLink works. And although they’re easily deployed for stateless fleets such as web servers, load balancers are the main reason Kafka deployments get complex.
A Kafka client knows what broker it needs to talk to. However, a load balancer knows nothing about the Kafka protocol and will balance requests randomly between clients and registered brokers. But this randomness breaks the Kafka protocol. A client cannot pick a random broker to connect to. Clients often need to connect to the leader of a particular partition to complete a request successfully.
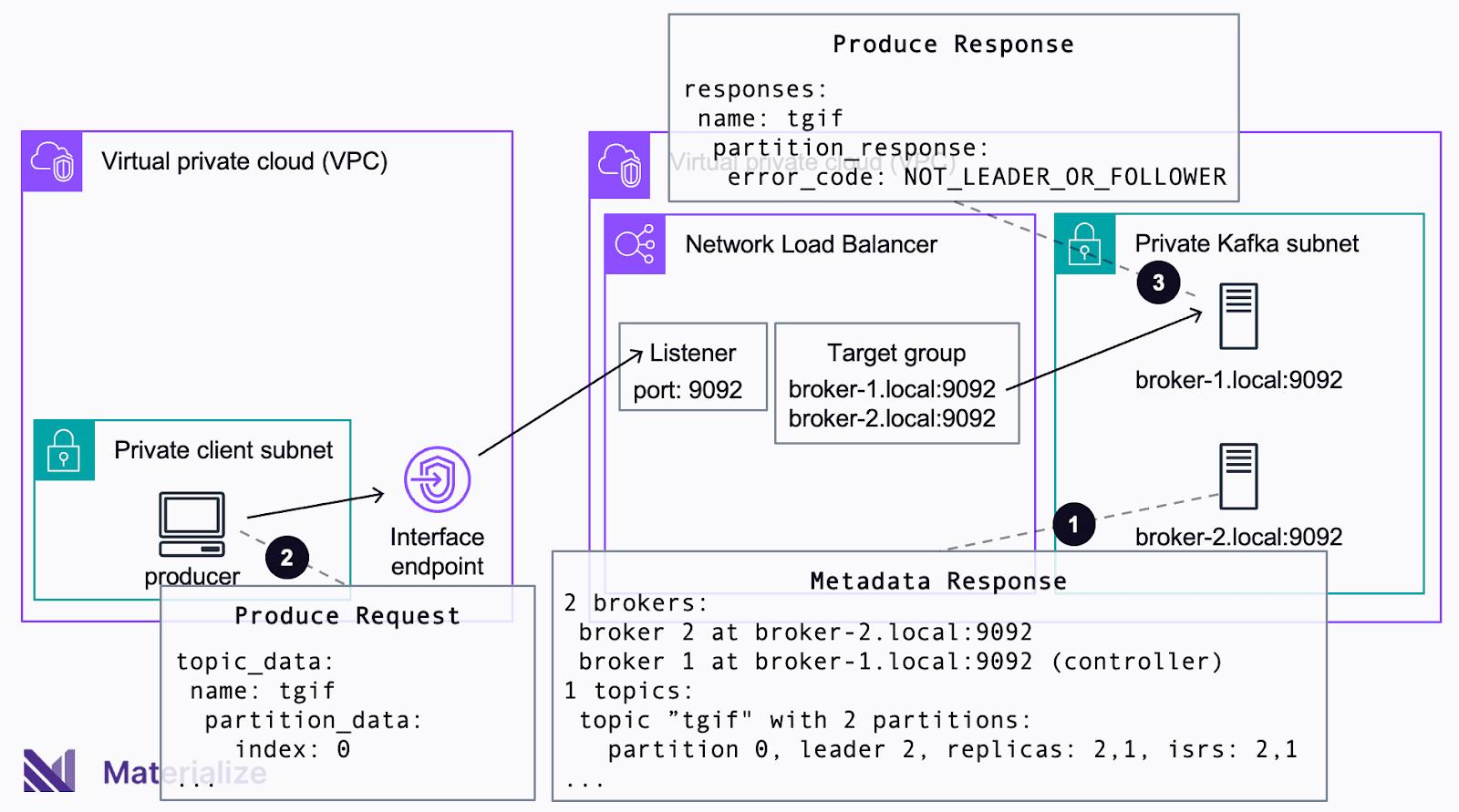
In the preceding example, the producer wants to persist data into Partition 0 of topic tgif. The producer first sends a metadata request to an arbitrary broker and receives the metadata of the cluster in response (❶). The producer then issues a produce request to the leader of Partition 0 (❷). The leader of Partition 0 is Broker 2, but the Network Load Balancer happens to forward the request to Broker 1. Because Broker 1 is not the leader, it will send back an error to the client, failing the request (❸).
To prevent requests ending up at the wrong broker, you must prevent the load balancer from routing requests to random brokers. To this end, we can create a unique listener and target group for each broker. Each target group contains a single broker and forwarding requests becomes deterministic. When a request hits a specific listener, there is only one broker available in the corresponding target group, so the load balancer must send the request to this broker. The load balancer essentially acts as a reverse proxy.
Using a unique listener for each broker requires a differentiating characteristic for each broker for the purposes of mapping. Naturally, brokers have different hostnames. But clients need to connect to the same PrivateLink endpoint, instead of directly to the brokers, so you can’t use the hostname. However, a TCP connection uses both a hostname and a port. Additionally, we can assign different ports to brokers using their advertised.listeners configuration. This configuration changes broker metadata without causing a change of their actual network configuration. Brokers continue to listen on the original hostname and port. But to clients, it appears the brokers are listening on the configuration associated with advertised.listeners.
The complete setup looks like this. By leveraging advertised.listeners, every broker pretends to listen on a unique port. For the load balancer, there is one listener that monitors the unique port for each broker and only forwards requests to this broker. A private hosted zone maps the DNS names of the broker and private link endpoint. This allows clients to connect to the endpoint rather than brokers (which are not reachable from their subnet).
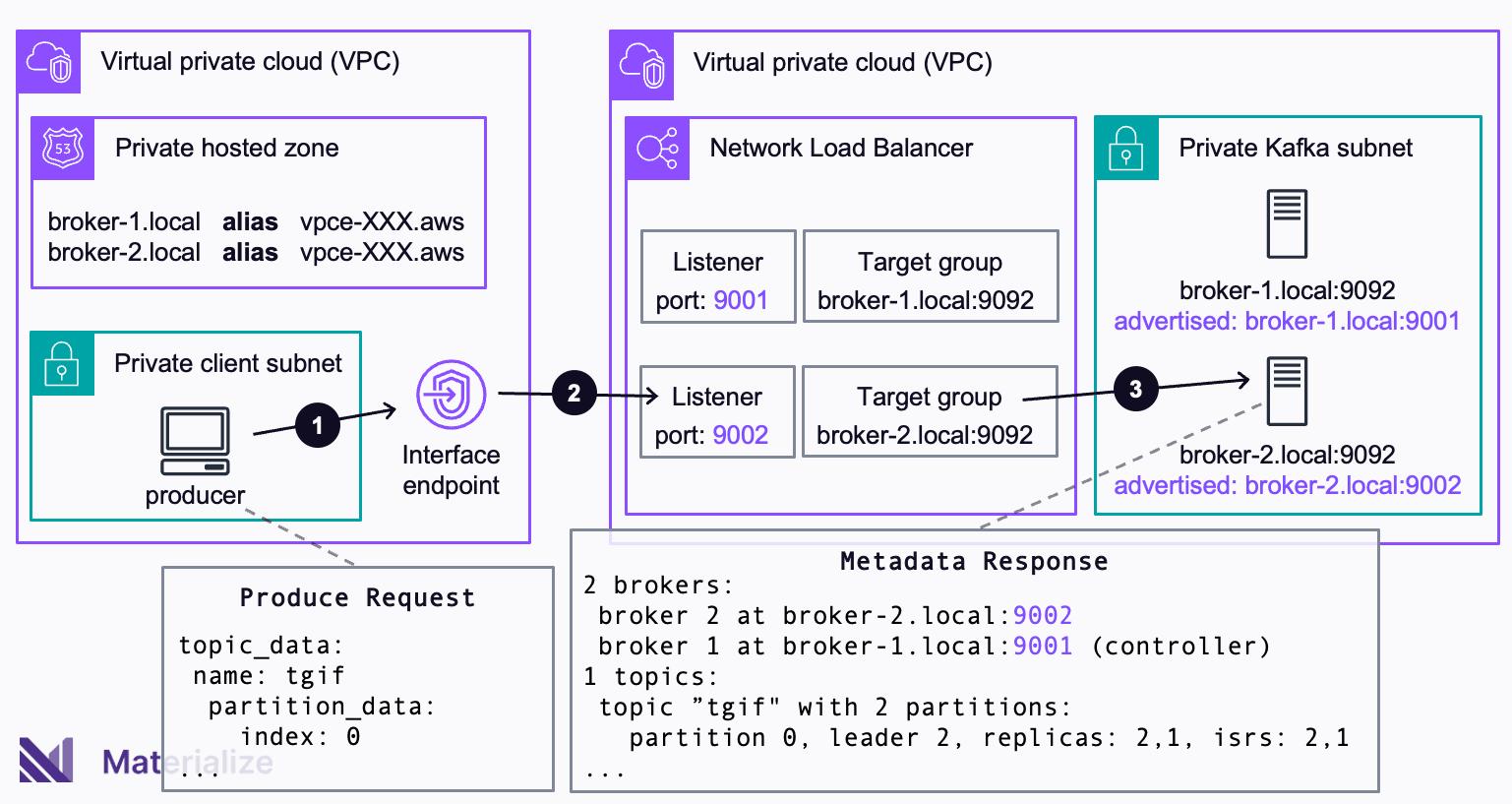
When a client tries to connect to the broker on the unique port specified in advertised.listeners, the connection process unfolds in the following sequence: Due to the adapted DNS configuration, the broker DNS name resolves to the IP address of the interface endpoint (❶). The connection is forwarded to the listener that targets the unique port of the broker (❷). Since only one broker is registered with this unique port, the load balancer must route to the correct broker (❸).
Uff. The entire setup is rather complex, considering the goal is to enable a load balancer that does nothing more than forward requests to a predetermined broker. And the complexity does not stop there.
Whenever a broker is added to the cluster, or the IP of a broker changes, you must apply the changes across your entire setup. The advertised.listeners of the broker must be adapted, a new listener and target group must be created, and you must provide the new broker name to the private hosted zone.
Some of these changes can be anticipated. But even then, the changes are fairly disruptive. A minor typo in the advertised.listeners configuration can potentially cut off all clients from that cluster. And you might be locked out of changing a configuration altogether, so you can’t make any modifications.
Although you can run PrivateLink this way from a technical perspective, the setup is quite complex and fragile. This requires elevated permissions to adapt broker and network configuration. A similar setup utilizes one load balancer and interface endpoint per broker. This removes the need to change advertised.listeners. But this, in turn, increases complexity in other parts of the architecture, including costs.
When customers set up Materialize, connecting to their Kafka cluster is usually the first thing they need to do. It’s not ideal for customer onboarding to begin like this. Asking for a complicated PrivateLink setup is not the seamless experience we expect for our customers at all times. That’s why we set out to find a less disruptive way for our customers to connect their clusters to Materialize.
The Solution: Custom DNS Resolution in librdkafka
PrivateLink requires a load balancer to work. It’s nothing we can change. Trying to make the load balancer understand the Kafka protocol is infeasible. But most of the complexity disappears if brokers can map to service endpoints and unique ports on the client side.
When a client wants to connect to a broker, it first obtains the metadata information of the cluster. The metadata lists the brokers and other information needed to consume from and feed into a specific topic and partition. To connect to a specific broker, for instance at broker-2.local
9092
, the client must resolve the name to an IP address. To do this, librdkakfa simply calls getaddrinfo(broker-2.local, 9092) to receive the specified IP address and port to connect to.
This is the perfect place to map brokers to service endpoints and unique ports!
To accomplish this mapping successfully, we extended librdkafka and added a resolve_cb callback that we can use instead of the native DNS resolution. Using this method, we implemented the mapping as part of the resolve_cb callback, which is passed to the client as part of its configuration.
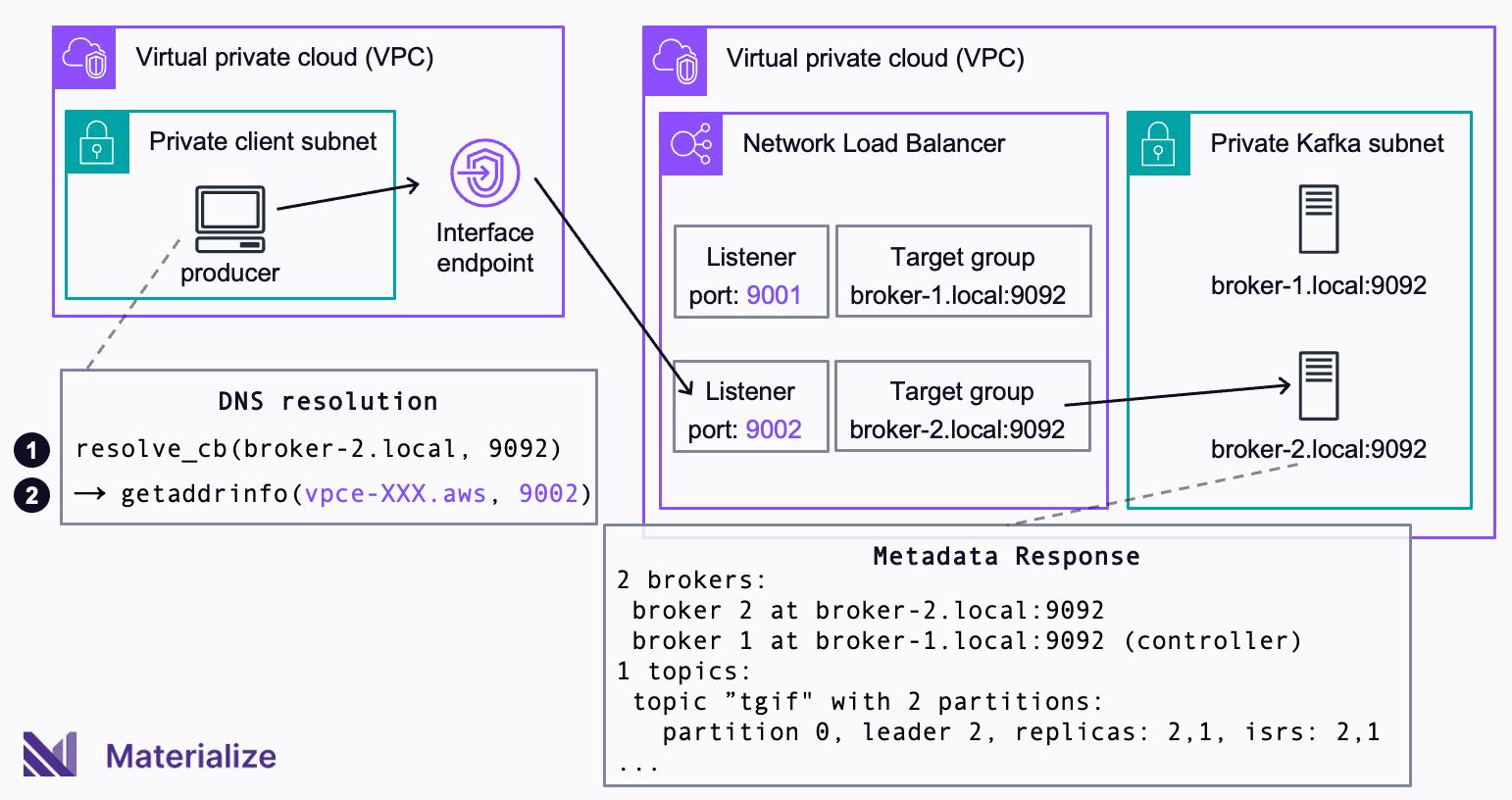
When using the resolve_cb callback method, a client that wants to connect to a broker, first invokes the callback resolve_cb(broker-2.local, 9092) (❶) instead of calling getaddrinfo(broker-2.local, 9092) directly. The callback then rewrites the broker DNS name broker-2.local to the DNS name of the interface endpoint vpce-XXX.aws. The port of the broker 9092 is rewritten to the port of the respective listener 9002. The callback then calls getaddrinfo(vpce-XXX.aws, 9002) to do the DNS resolution on the rewritten details (❷).
Effectively, the client thinks it connects to broker-2.local
9092
, but the callback redirects the connection to the interface endpoint on the correct port. By using the callback to rewrite the host and port name inside the client, you no longer need to modify advertised.listeners, or provide a private hosted zone. The configuration of the mapping in the client and the load balancer still need to be kept in sync with the cluster configuration. But the configuration of the Kafka cluster that serves production traffic for other applications remains unchanged.
Moreover, because the mapping is implemented in the client, security mechanisms like mTLS remain intact. The client talks to the cluster on the unaltered broker names and ports. That means the certificates of the cluster remain valid. You won’t need to add additional certificates for the DNS name of the interface endpoint.
The Icing on the Cake: Custom DNS Resolution for SSH Tunnels
Connecting to a Kafka cluster by means of an SSH bastion is a much simpler endeavor. A client first establishes an SSH tunnel to the bastion and connections from the client to the brokers are then made through that encrypted tunnel. There is no Network Load Balancer involved and no need to adapt the advertised.listeners configuration of brokers. However, for a client to connect to a specific broker, the connection must still be rewritten to the local endpoint of the SSH tunnel. To this end, we can apply this mapping in resolve_cb callback rather than a private hosted DNS zone to avoid changing any configuration of the client network.
We’re Excited to Simplify Private Kafka Connectivity
Our innovation in PrivateLink and SSH integration is paying dividends for our customers. We want an additional layer of protection when connecting to our customers' clusters. But changing their Kafka configuration just to bring their data into Materialize seemed too burdensome for our customers. And we found a solution: leveraging the resolve_cb callback in librdkafka allowed us to combine the additional layer of security protection without requiring a complicated, manual set up process.
We've used this method in production for over a year now, and it has unlocked a new level of both protection and convenience for our customers. We've also upstreamed the changes into librdkafka, so all clients that are based on librdkakfa can leverage the simplified PrivateLink setup we’ve developed.
If you are planning to use PrivateLink or SSH bastions and cannot use the native functionality that is offered by the Kafka provider of your choice, you have now an option available that helps to avoid the complexity that is usually entailed with these options. Let us know what you think! Feel free to reach out to us on our Slack community if you have any feedback.

