Creating a Real-Time Feature Store with Materialize
April 25, 2022

The last decade has seen companies heavily invest in machine learning. Teams of data scientists can build models to solve complex problems that were out of reach just years ago. But unfortunately, this is only one part of the problem. The real value in machine learning only comes when successfully deploying models to production.
According to industry reports, only 22 percent of companies using machine learning have successfully deployed a model. And out of that cohort, over half believe deploying another would take at least 90 days. Often, the challenge is not training the model but getting up-to-date, correct information for it to score.
The input to a machine learning model is called a feature vector. A feature vector is a list of data points, called dimensions, describing the real world. Recent years have seen the advent of the feature store, a centralized management system that allows for fast retrieval of feature vectors. If these features are not in sync with the real world, the model cannot provide accurate scores.
Materialize has all the capabilities necessary to deliver a feature store that continuously updates dimensions as new data becomes available without compromising on correctness or speed.
You can find a complete implementation of this feature store on Github.
Example Use Case: Fraud Detection
Suppose our company builds a model serving application to detect credit card fraud. In our system, there are accounts and account owners. Each account is associated with a single owner, but each owner might have multiple accounts. Each transaction is given a fraud score in real-time. If scored above some threshold, the transaction is blocked.
Our data science team has concluded that the more often we’ve seen fraud against an owner, the more likely it will happen again. We are in charge of building a feature store, which, when given an account id, will return the number of verified fraudulent transactions against an account owner over the last 30 days.
Architecture
At the center of our feature store is Materialize, which will pull data from several sources and serve results to a web server. It will incrementally and continuously update a fraud count feature, which it can quickly serve from memory.
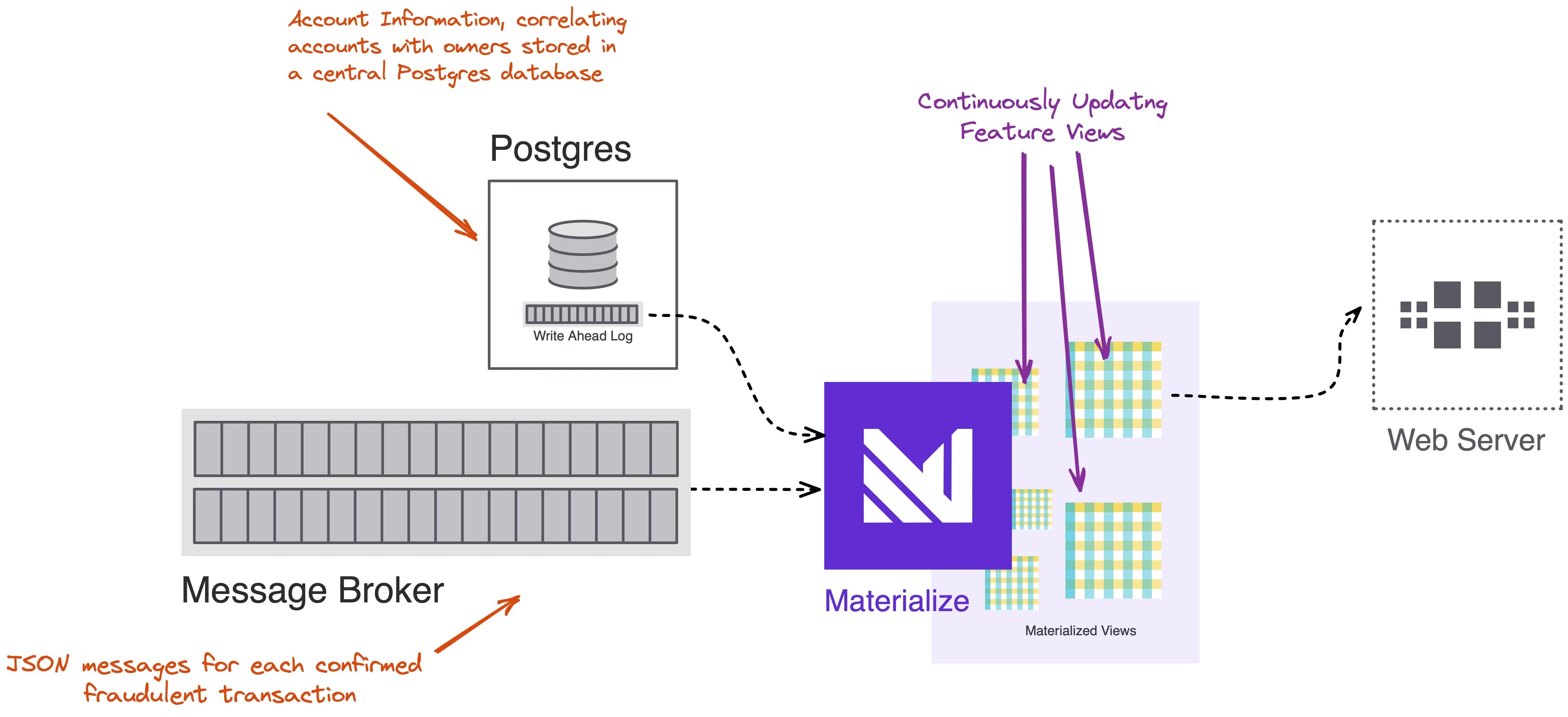
Continuously Ingest Data
Calculating the fraud count feature requires two data points: account information and confirmed fraud.
Account information is a table in a central Postgres database that correlates account owners to account ids.

Materialize can read directly from Postgres binlogs, allowing it to consume tables without additional infrastructure such as Debezium.
On the other hand, Materialize consumes confirmed_fraud from a message broker. The implementation can be anything Kafka API compatible such as Apache Kafka or Redpanda. Each message is a JSON payload containing an account id and timestamp for a transaction confirmed to be fraudulent.
1 | |
Materialize ingests data from external systems through Sources. We can define the appropriate data for our input using the DDL below.
1 | |
2 | |
3 | |
4 | |
5 | |
1 | |
2 | |
3 | |
1 | |
2 | |
3 | |
4 | |
Building Features in Real-Time
With the sources in place, we can define the Materialized View, which will calculate and serve this feature. The first step will be deserializing the json_confirmed_fraud into a well-typed view, making it easier to manipulate.
1 | |
2 | |
3 | |
4 | |
5 | |
From this view, we can calculate how many fraudulent transactions each account has seen for the last 30 days. This query performs three tasks: a join, a filter, and an aggregation.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
Materialize has much broader support for JOINs than most streaming platforms, i.e., it supports all types of SQL joins in all of the conditions you would expect. Data does not need to be arbitrarily windowed to derive correct results. It is easy to correlate the account owner to each transaction.
Next is the WHERE clause, which filters data based on transaction_ts and mz_logical_timestamp(). Think of this function as similar to now(), but it continually reevaluates as time moves forward, based on the data processed. As rows from the confirmed_fraud view become more than 30 days old, Materialize automatically filters them from the result.
The query finally reports a COUNT(*) of all the records grouped by account_owner and account_id. This aggregation is continuous and has very low latency. Importantly, it supports both insertions and retractions. The count will go up as new fraudulent transactions are confirmed and will automatically go down as they age out over time.
At this point, we have constructed a Materialized View with a rolling 30-day count for each account id. However, our desired feature should contain the total count for all accounts under the same owner. Because each row now contains the account_owner, we can again leverage Materialize’s sophisticated join semantics to join the VIEW with itself.
1 | |
2 | |
3 | |
4 | |
5 | |
The final VIEW, fraud_count_feature, reports the total count for the account owner by account id. Querying by account_id is now a simple and efficient point lookup. And because Materialize is Postgres wire compatible, the feature can be queried using your favorite Postgres driver. No custom integrations are required.
Materialize makes it simple to build a real-time feature store without sacrificing correctness. It's source available and free to run locally. Try the quickstart to get hands-on, and join us in the community Slack if you have questions!
