Real-Time Data Architectures: Why Small Data Teams Can't Wait

In today’s rapid-fire market, companies must build data architectures that deliver real-time data to customers. Customers now demand a mobile-first, frictionless user experience across all channels. That expectation has carried over to internal customers as well. Data consumers anticipate instant access to the insights and analytics they need to solve their business problems.
But in reality, many customers are still not satisfied with the user experience. External customers are not served real-time data. And internal customers do not receive the insights they need in a timely fashion. This is because companies lack the data architecture needed to provide real-time experiences.
In the past, building real-time data architectures was a multi-year investment. Teams implemented real-time data with complicated microservices on top of expensive streaming infrastructure.
For large data teams, building streaming services was labor-intensive and costly, but accomplishable. Large data teams had the budget, time, and personnel to build custom streaming solutions from scratch.
Small data teams, on the other hand, lacked these resources. They did not have the funds, technology, time, or skillsets required to create real-time data architectures. Small data teams barely had time to triage critical data issues. Building streaming architectures from zero was not within reach.
But this is no longer the case. With the emergence of operational data warehouses, small data teams can now level the playing field; they can leverage operational data warehouses to develop real-time data architectures that are accessible, efficient, cost-effective, and easy to deploy.
This is the first entry in our blog series on small data teams. The blog series is adapted from our free white paper: Real-Time Data Architectures for Small Data Teams. Download the white paper now for the complete text.
Why Companies Need Real-Time Data Right Now
In 2023, consumers lost $10 billion to fraud. Companies that incorporated personalization into their platforms experienced a 40% increase in revenue. And by 2025, 1 in 3 adults in America will wear fitness trackers.
At first glance, these examples seem unrelated. But there is a common thread. All of these problems require real-time data to solve. Consider some of the underlying use cases for each statistic:
- Fraud detection - In order to detect fraud almost instantly, banks and fintechs must leverage real-time data to catch fraudsters in the act. If the data is hours or even minutes out of date, fraudsters can inflict substantial monetary damages without any repercussions.
- Personalization - Sectors such as e-commerce harness real-time behavioral data about customers to serve them relevant products and incentives as they’re shopping. Companies must present these offers in the moment, otherwise consumers are less likely to act on them.
- Real-time analytics - Devices such as fitness trackers rely on real-time analytics to update users with health metrics. Fitness trackers use IoT sensors to capture real-time data about bodily movements. This real-time data is converted into digestible analytics and visualizations for each user.
These are just a few statistics that reveal the importance of real-time data. But beyond these examples, consumers today expect real-time experiences, from customer support to the location of delivery drivers. Streaming data unlocks the real-time experiences that consumers now require.
And the move to real-time data seems inevitable, so why not address the opportunity now? Even small data teams can build streaming systems with new technologies such as operational data warehouses.
How the Problem Starts: Limitations of the Modern Data Stack
For small data teams, the modern data stack offers major benefits, including scalability, speed, and ease-of-use. With cloud-native data warehouses, these teams can easily set up and quickly scale data infrastructure. They don’t have to worry about hardware, provisioning, or maintenance. This allows them to build complex data infrastructure without increasing headcount.
However, the modern data stack is not designed to handle real-time use cases. Teams employ several tools in a modern data stack: an ELT tool, an analytical data warehouse, a transformation tool, and a BI tool. These tools are limited by the batch architecture of the analytical data warehouse.
An analytical data warehouse leverages batch processing to load data. Data is loaded into the warehouse on a set schedule, rather than in real-time. Frequently, batch updates only occur a few times per day. For use cases that require real-time results, such as personalization, hours-old data is too stale to be effective.
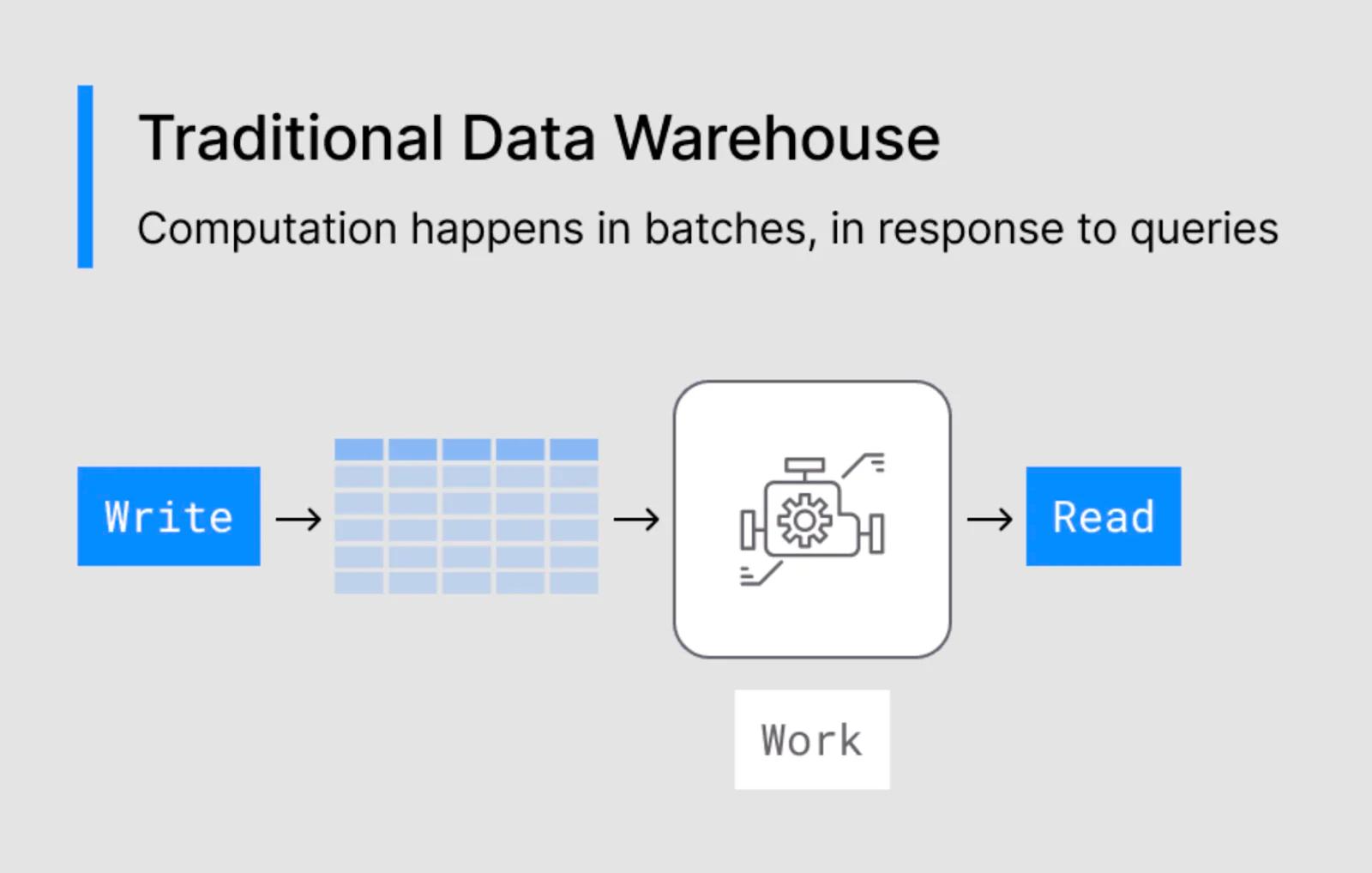
To counteract this staleness, teams sometimes push their analytical data warehouse to the limit. Instead of loading data every few hours, teams update data as fast as possible. But there is also a hard limit on how fast analytical data warehouses can load data. As a result, there is lag between when data is captured and when it is utilized in a real-time use case.
This delay can create issues with real-time use cases. For instance, with fraud detection, automated bots can take over accounts and steal thousands of dollars in seconds. In this scenario, an analytical data warehouse can drive significant losses with just a few seconds of lag.
The cost of running real-time use cases on analytical data warehouses is also very high. With fraud detection, this use case requires teams to continuously execute SQL queries to determine if fraudulent activity is occurring. But because analytical data warehouses offer pay-per-query pricing, running transformations so frequently drives up compute costs.
Many teams initially run their real-time use cases on analytical data warehouses. However, as the cost of query execution grows, and technical limitations are reached, teams begin to look for other options.
Streaming Solutions: What Are the Standard Options?
Once teams reach the limits of their analytical data warehouse, they can either operate at these thresholds or adopt dedicated streaming tools. With a streaming tool, teams can implement real-time data, scale their use cases, and offload workloads from their analytical data warehouse.
Due to the limitations of traditional data warehouses, some data teams turn to microservices to build their streaming solutions. Microservices are a type of software architecture composed of small independent services that communicate over well-defined APIs.
Teams leverage Flink, Kafka Streams, and other low-level streaming tools as part of their microservices. A key benefit of microservices is the ability to employ standard programming languages, such as Java and Python.
However, microservices are expensive and difficult to maintain. With so many different data products, and bespoke requirements, microservices require significant engineering resources and budget overhead to operate. Microservices can also become unwieldy and susceptible to dysfunction.
Teams employ streaming SQL tools such as ksqlDB on top of their stream processors to build streaming databases. But the SQL-like syntax is not standard SQL and it shows; users still need to reason through streaming semantics like time windowing, watermarks, grace periods, and partitioning.
Flow Diagram for Streaming Database
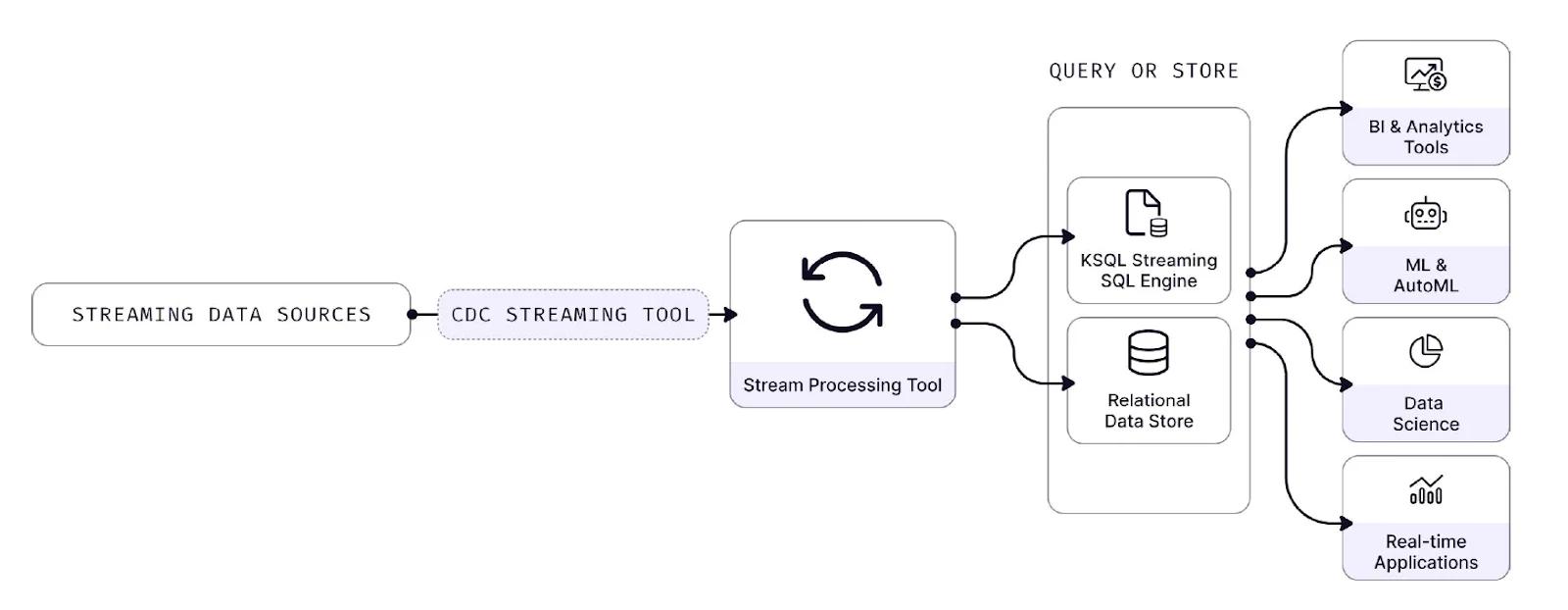
Moreover, these systems tend to lack interactive capabilities taken for granted in most databases. Transformation pipelines are completely fixed. If teams want a slightly different result or a finishing touch, they have to create a separate pipeline or load the data into an interactive database.
Another challenge for streaming SQL tools is eventual consistency. With eventual consistency, the results eventually match all of the data inputs. In other words, the results are published before the database processes all of the data inputs, often leading to incorrect or unreliable results.
With streaming SQL tools, teams must balance eventual consistency and other foreign concepts to build reliable apps and services. This lack of full SQL support is one of the key limitations of streaming databases.
Download the Free White Paper Now
Download our free white paper — Real-Time Data Architectures for Small Data Teams — to read the rest!
Now that you have an overview of why small data teams need real-time data architectures, keep your eye out for our next blog in the series.
We’ll cover some of the pitfalls small data teams encounter when they build real-time streaming services, and why an operational data warehouse offers an easeful SaaS solution for the problem.
