
Cost reduction is a key selling point of cloud data warehouses. With serverless architectures, near-infinite compute and storage, and pay-as-you-go pricing, cloud data warehouses can make teams more efficient and cost-effective.
But teams can also neglect or misuse the power of data warehouses. The ease and awesome scale of these platforms can magnify problems such as query recomputation, misaligned compute resources, and suboptimal data storage.
These issues, of course, drive up costs. This causes a data warehouse to become a cost center, rather than a cost saver.
However, reducing data warehouse costs is achievable for most teams if they employ the right strategies. By adopting best-practices, teams can lower the cost of their data warehouse without sacrificing performance.
In the following series of blogs, we’ll outline several strategies for reducing data warehouse costs.
You can read about all of the strategies in our new white paper: “Top 6 Strategies for Reducing Data Warehouse Costs”.
Incrementally Maintained Views: Decouple Cost from Query Freshness
Traditional data warehouses — or ‘analytical’ data warehouses — typically operate on a pay-per-query pricing model. You’re charged every time you run a query. Cost, then, is tied to query frequency, or how often you perform queries on your data.
Analytical data warehouses run on batch processing, meaning that data is not ingested in real-time, but in bulk at set intervals. Queries are also run at intervals, in tandem with batch jobs. When the queries run, you’re charged for the associated CPU resources.
But there’s a hidden cost to all of this.
Each time you re-run a query, much of the underlying data has already been computed previously. Instead of only computing the data that has changed, traditional data warehouses re-compute all of the data each time. That means you’re charged CPU resources to re-compute data you’ve already queried.
This inherent inefficiency isn’t as costly if you’re running a query once a day, for an analytics workload. But if you’re running a query several times a day, the cost inefficiency starts to eat into your budget.
Even more acutely, if you’re performing real-time use cases such as fraud detection or alerting on your data warehouse, you need to execute queries every few seconds rather than every few hours. Real-time workflows demand fresh query outputs in seconds to respond to immediate events.
Analytical data warehouses eventually hit cost and freshness limits when they run real-time use cases. In addition to performance issues, you’re also constantly recomputing the same data every few seconds. This is when the cost of query recomputation starts to become unmanageable.
So what’s the solution?
Operational data warehouses (ODWs) can significantly reduce the cost of query recomputation. ODWs combine streaming data, SQL support, and incrementally maintained materialized views to decouple cost from query freshness.
To power real-time use cases, operational data stores continuously transform streams of raw data into actionable outputs. ODWs allow you to execute SQL queries on fresh data continuously, so you can run real-time operational use cases.
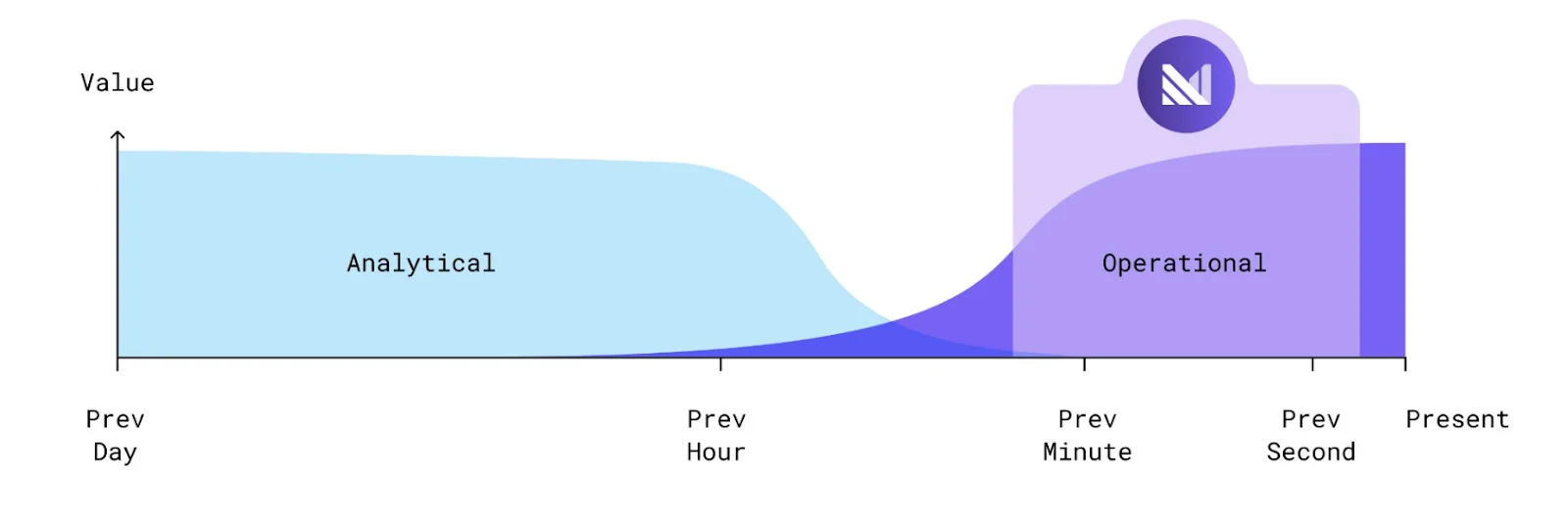
To do this, operational data stores such as Materialize leverage incrementally maintained materialized views. Materialized views incrementally refresh query outputs, so you don’t need to recompute the underlying data constantly.
Curious about how it works? Let’s do a quick whiteboarding session!
Imagine we have a table containing customer purchases called purchase.
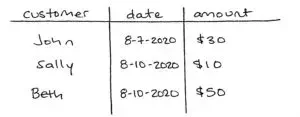
Let’s calculate the total revenue of this table using the following query:

Now let’s create a materialized view based on this query.

Unlike queries that calculate their results from tables and views, queries that read from materialized views do not recalculate their results each time.
When this statement is executed, your data warehouse will run your query once to calculate the result. Then, it will physically store that result in a newly created database object — in our case an object named total_revenue.
Now when you query total_revenue, your data warehouse will return the stored results without performing any additional computation.
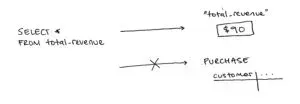
This means that unlike querying a view directly, you only pay for the cost of your query once when creating a materialized view.
But there’s a catch. If the underlying data to the query is updated, the materialized view is out-of-date. Let’s say we add another entry to our purchase table.

However, since the query was run before the newest purchase was added to the purchase table, the result calculated and stored in total_revenue does not take this new purchase into account.
Generally, there are two mechanisms for refreshing materialized views: complete refreshes or incremental refreshes.
Complete refreshes re-run the query underlying a materialized view to completely recalculate and replace the stored results. This requires a full recomputation of the query.
By contrast, incremental refreshes keep materialized views up to date by only performing work on data that has changed. Operational data warehouses allow you to perform incremental refreshes.
Rather than rescan each row of the purchase table to calculate the sum, an incrementally maintained materialized view would only do the following work:

Since query recomputation can account for significant compute spend, you can instead use incrementally maintained views in operational data stores to keep the spend down.
Of course, batch data warehouses can perform incremental refreshes with dbt incremental models. But with Materialize, the refresh is continuous. Each new input record updates the query output immediately.
With Materialize, you don’t have to recompute the same data every time you execute a query. This can save you a significant amount of money, especially if you’re performing real-time use cases.
Offload Real-Time Use Cases: Operationalize Workloads with Streaming Data
With historical data and flexible querying, analytical data warehouses allow you to develop SQL logic for real-time use cases. But operationalizing these real-time workloads on your analytical data warehouse is difficult.
With analytical data warehouses, these real-time workloads require constant query recomputation and spikes in compute usage. This is a very expensive and inefficient way to leverage CPU resources.
You can avoid these costs by offloading real-time use cases to an operational data store such as Materialize.
Materialize operates with static, always-on compute resources, making it far cheaper to run real-time use cases. Analytical data warehouses, on the other hand, charge per query and rely on inefficient spikes in compute for fast responses.
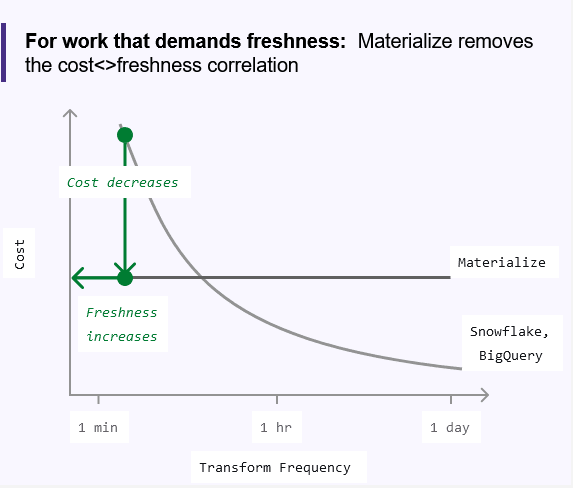
Once you’ve offloaded your real-time use cases to Materialize, you can start to consolidate and optimize your query workloads on your analytical data warehouse as well. Combine your workloads to maximize compute clusters and minimize costs.
Here’s an example.
Let’s say you’re optimizing compute on your analytical data warehouse. If you run 100 complex queries in a short timespan on an expensive compute cluster, you’ll save more money than running less queries on smaller compute clusters. You’re actually using less compute resources in the first example.
For your analytical warehouse, you could potentially cut your computation costs significantly with similar optimizations. Perhaps you just need to schedule workloads more strategically and run them in parallel.
By offloading your real-time use cases to Materialize, you can optimize your compute usage across your data stack, and reduce your data warehouse bill.
Try These Strategies for Reducing Data Warehouse Costs
You can leverage incrementally maintained views, and offload real-time use cases, in Materialize. This will enable you to save money on your data warehouse bill.
By decoupling cost from query freshness, you can continuously transform data and run real-time use cases cost-effectively.
To see all of our strategies for reducing data warehouse cost, download our latest white paper: “Top 6 Strategies for Reducing Data Warehouse Costs”.

