Self-Correcting Materialized Views

Materialized views (MVs) are one of the core features of Materialize (hence the name!). The concept is well-known from traditional SQL databases like PostgreSQL, as a way to precompute query results to reduce the cost of subsequent queries. In contrast to traditional databases, Materialize is able to incrementally maintain materialized views over complex SQL expressions, updating their results as soon as inputs change. Incremental view maintenance ensures excellent freshness and smoother resource utilization, but also introduces a number of exciting new technical challenges.
One of these challenges is output drift: It is possible, though hopefully unlikely, for Materialize version upgrades to change the results of computed view queries. For example, we might discover a bug in the implementation of a rarely used SQL function, fixing which would change the results produced by that function. Without special handling, output drift can silently corrupt the persisted state of a materialized view, rendering its results incorrect.
What makes this problem even more interesting is that our users face a version of it too. A common pattern we see is different teams stacking materialized views on top of each other, building an incrementally updated data mesh. When teams evolve their SQL definitions, replacing a materialized view's query is, from the storage layer's perspective, indistinguishable from output drift caused by an upgrade. Materialize handles both cases through a single mechanism we call self-correction. This article walks through the internals of self-correction, then shows how it naturally extends to support in-place materialized view replacement.
Incremental view maintenance in Materialize
Materialize is all about incremental view maintenance. It transforms user-provided SQL queries into differential dataflows that produce output changes according to the requested SQL semantics. Differential dataflows operate on input changes (as opposed to full snapshots) and thus need only perform work proportional to the size of those changes, not the size of the whole dataset. Given that inputs change gradually over time for most workloads, the differential computations can keep up with input changes in real time even when applied to large datasets and complex SQL graphs.
A differential dataflow operates on and produces a stream of update tuples of the form (data, time, diff).
datais the element modified by the update, usually a SQL row.timeis a timestamp in Materialize’s logical time.diffdescribes how the amount ofdatachanged attime. A diff of+1inserts one record, a diff of+10inserts ten records, a diff of-10removes ten records.
For example, inserting the value “foo” into a single-column table translates to an update (['foo'], <time1>, +1). Later updating that value with “bar” results in two updates at the same logical timestamp: a retraction (['foo'], <time2>, -1) and an insertion (['bar'], <time2>, +1).
Each dataflow also has a write frontier, the logical time after which the dataflow might still produce updates. For all times before the write frontier, the dataflow output has been fully computed and is guaranteed not to change anymore. The results of a dataflow for any time t less than the write frontier can be obtained by rolling up the stream of updates to that time, which is done by taking all updates with times ≤ t, grouping them by their data component, and summing up their diffs. For example, the updates (A, 10, +1), (A, 20, +1), (B, 20, -1) rolled up to time 20 become (A, 20, +2), (B, 20, +1) (two A records, one B record).
An important correctness property of dataflow outputs is that the rolled-up representation for any time less than the write frontier must not have negative diffs. Intuitively that means a dataflow result cannot have negative records. We will see below how output drift can introduce negative records in materialized views, thus causing a form of data corruption.
A dataflow also defines what happens to the updates it produces. That differs depending on the type of SQL object the dataflow maintains:
- For indexes, the updates flow into in-memory data structures called arrangements that can be efficiently queried or consumed by other dataflows in the same cluster.
- For materialized views, the updates are written to Materialize’s durable storage layer, allowing sharing of results between clusters or with external systems.
- For subscriptions, the updates are sent back to the client over the pgwire protocol.
In this article we focus on the part of materialized view dataflows that write the stream of updates into storage. We call this part the materialized view sink — not to be confused with the higher-level concept of a sink, which exports data to external systems like Kafka.
Updates written by an MV sink become durable state, opening up the can of worms that is version compatibility. We need to make sure the data we have written to storage remains readable and consistent across version upgrades to Materialize. Fortunately, Materialize’s storage layer guarantees backward compatibility of all data it manages, so we don’t have to worry about the persisted MV outputs becoming unreadable. We do have to worry about logical consistency though.
A naive MV sink implementation
To see how consistency could be violated during version upgrades, let’s consider a naive implementation of an MV sink that directly writes updates produced by the dataflow to the output storage collection. This works great during normal operation, but requires care on restart.
When a dataflow restarts—whether due to a version upgrade, a cluster rescale, or failure recovery—it doesn’t have access to the updates it produced previously. Instead, it re-reads all current input data and recomputes the view query from scratch, producing a fresh snapshot of results. But the MV sink can’t just write this snapshot to storage. In Materialize, storage collections advance through time. Once a time has been committed, writers can’t go back and write new updates at that same time. The snapshot a dataflow produces after a restart is likely to contain updates from the past, and thus trying to write it to the output storage collection as a whole would fail.
To avoid this, the MV sink uses the storage collection’s write frontier: the timestamp up to which all updates have been durably committed. On restart, the sink discards any updates at times less than or equal to this frontier, i.e., any that have already been persisted, and only commits updates at times beyond it. This ensures each update is persisted exactly once.
Output drift
The naive implementation is simple and efficient, but it fails to account for one key issue: The output of a dataflow can change across version upgrades. In other words, the contents of a view can change after a version upgrade, even though there were no changes in the inputs. There are several causes of this:
- SQL semantics: SQL does not fully define the output of some queries. For example, the query
SELECT * FROM t LIMIT 1is free to return any record insidet, and might even return different records when issued multiple times in succession. Both Materialize’s SQL planner and the dataflow execution engine might make use of these freedoms to improve efficiency, which means that upgrades of these components can change the output of a maintained view.
- Note that Materialize generally does its best to make the results of a SQL query deterministic, even in cases where the SQL spec doesn’t require determinism. For the above
LIMIT 1example, we ensure determinism by imposing a canonical ordering on the input rows. For more complex queries, though, we cannot always guarantee determinism.
- Bug fixes: Though we do our best to avoid them, bugs are a fact of life for any software product. If a bug is discovered that influences the results of a maintained view, we would like to have the option to fix it. Doing so necessarily changes the output of the view.
- Environment changes: Dataflow results can depend on properties of the environment not directly controlled by Materialize engineers. Examples include Linux’s timezone database or the Unicode version included in the Rust stdlib.
To see why this poses problems for materialized views, let’s consider this simple example:
1 | |
2 | |
3 | |
As mentioned, SQL doesn’t fully define the output of this particular MV query. Materialize takes measures to keep it deterministic, but to keep the example simple, let’s pretend that it doesn’t and the output can change between version upgrades. Let’s also assume we are upgrading Materialize from version V1 to version V2 and the output of the query is ['foo'] at V1 and ['bar'] at V2. The figure below shows how the naive MV sink described above behaves when the upgrade is performed and the ['bar'] entry is subsequently deleted from the input table:
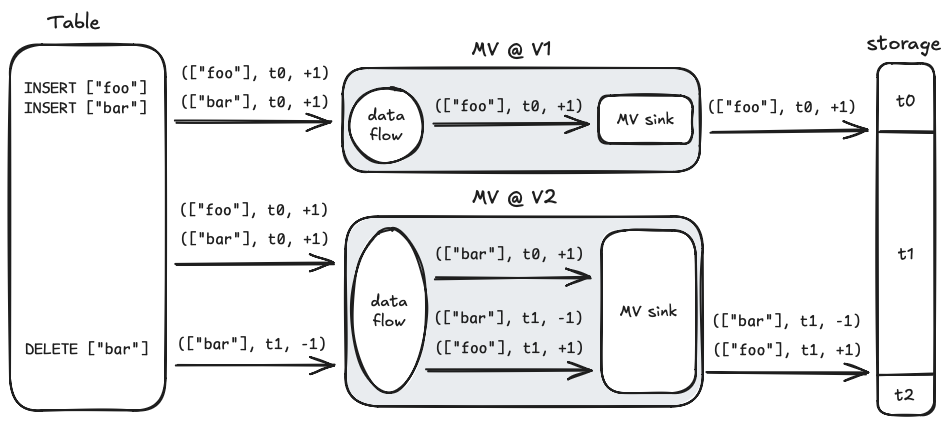
When the MV is created, at version V1 and time t0, its output is ['foo'], so that’s what gets inserted into storage. After the version upgrade, the MV query’s output changes so the MV dataflow produces the update (['bar'], t0, +1) instead. The MV sink observes that all updates for t0 have already been committed to storage, so it ignores this update. Later, at time t1, the ['bar'] record is deleted from the input table, so the MV dataflow’s output switches from ['bar'] to ['foo'], represented as a retraction of the former and an insertion of the latter. These two updates are inserted into storage because they occur at a time after the storage collection’s current write frontier.
Now consider the contents of the storage collection at the end. Rolled up to the most recent completed time, t1, they are:
1 | |
2 | |
We end up with two copies of ['foo'] and negative one copies of ['bar'] where instead we should only have a single copy of ['foo']. This is a correctness bug. Not great!
The core issue is that the V2 MV sink has no knowledge of the output produced by the V1 dataflow. It writes deltas based on the output it would have produced, not what actually has been persisted.
Self-correction
To function correctly in the face of output drift, materialized views in Materialize are self-correcting. They continually read back the contents of the output storage collection, diff them with the stream of incoming updates from the dataflow, and write back the resulting diff so that the persisted contents match the desired dataflow output. Here is what that looks like:
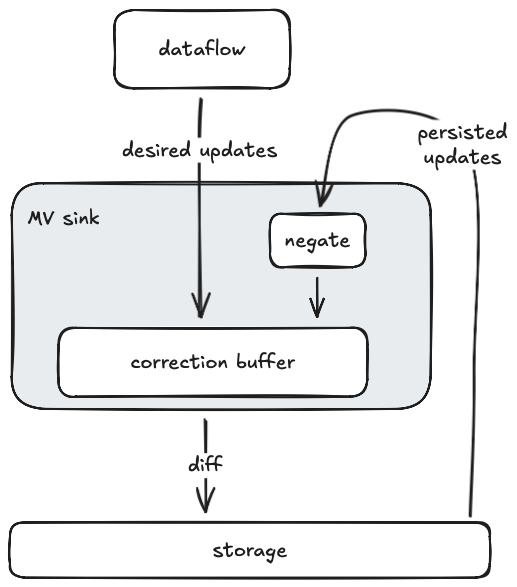
To produce the diff between desired and persisted updates, the MV sink maintains a correction buffer. This is a data structure, not unlike an arrangement, that efficiently stores updates and consolidates them periodically or on demand. Every time the MV sink decides to write a new batch of data to the output storage collection, it forces a consolidation of the correction buffer and writes out its resulting contents. Note that updates are never explicitly removed from the correction buffer. Instead they are canceled out against the persisted updates that flow back through the feedback edge.
To confirm that this design solves the output drift problem, let’s consider again the motivating example from above. The table below shows how it plays out in the MV sink. Timestamps are omitted for simplicity.
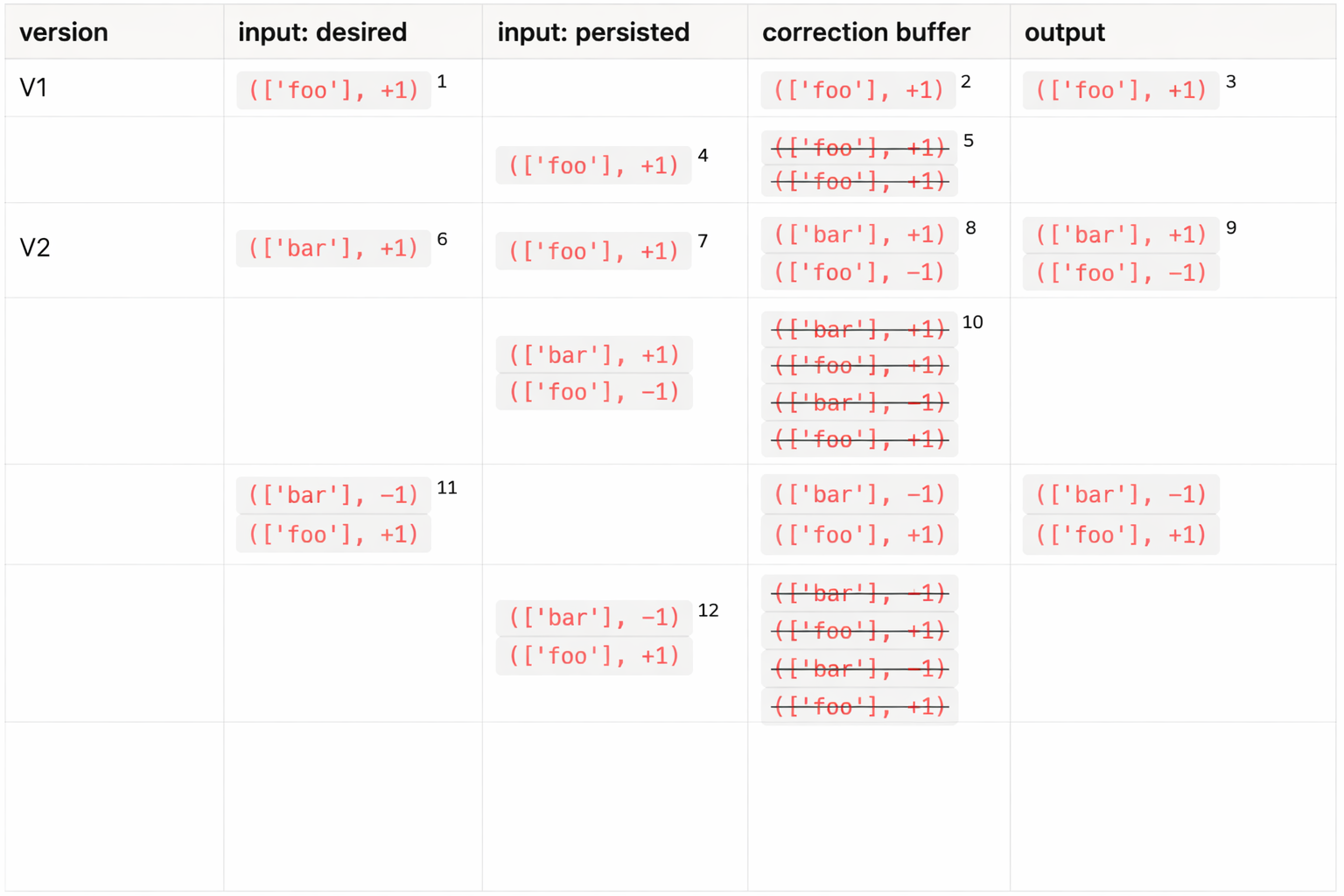
At version V1, the MV sink receives an insertion of ['foo'] from its “desired” input1. That update gets pushed into the correction buffer2, and is subsequently written to the output storage collection3. It then travels back through the feedback edge into the MV sink4, where the diff gets negated before the update is pushed into the correction buffer, canceling out the existing contents5.
At version V2, the MV sink restarts. This time it receives an insertion of ['bar'] from its “desired” input6, as well as an insertion of ['foo'] read back from the contents of the storage collection7. As a result, the correction buffer receives an insertion of ['bar'] and a retraction of ['foo']8, both of which get written to storage9. After reading back, negating, and consolidating the persisted updates, the correction buffer again becomes empty10. The rolled-up contents of the storage collection are now [(['bar'], +1)], which matches the desired dataflow output.
Finally, the upstream DELETE of the ['bar'] row causes the MV sink to receive both an insertion and a retraction from its “desired” input11. Both flow through the correction buffer into storage and then back through the feedback edge12. At the end, the rolled-up contents of the storage collection are [(['foo'], +1)], leaving us with the desired output. Great!
The cost of correctness
The self-correction mechanism ensures consistency across version upgrades, but it has a cost. The correction buffer needs to stash updates coming in from both the dataflow and the storage collection for some time, which costs memory. Furthermore, diffing the two update streams against each other requires consolidation, in which the stashed updates are sorted and their diffs are summed up, at the cost of CPU time.
The increased memory and CPU usage are not an issue during steady-state, where the amount of updates received from both inputs is small. But it can be significant during dataflow hydration (the process of recreating the in-memory state of a dataflow on startup), where the entire dataflow output snapshot needs to be diffed with the entire contents of the storage collection. In the worst case, the resulting memory spike is the size of both input snapshots combined. Depending on the size of the materialized view, such a hydration memory spike can dominate a cluster’s peak memory usage.
There are currently two measures Materialize takes to mitigate the impact of the hydration memory spike: limiting hydration concurrency and spilling to disk.
Hydration concurrency is a global configuration parameter that specifies the number of dataflows that are allowed to hydrate at the same time. When a cluster is restarted, all dataflows installed on it must be re-hydrated. Materialize ensures that dataflow hydrations are sequenced according to the configured hydration concurrency. In clusters that run multiple materialized views, limiting the hydration concurrency lets us reduce the overlap of the hydration memory spikes. The peak memory usage of such a cluster is thus bounded by the size of the largest MV, not the sum of the sizes of all installed MVs.
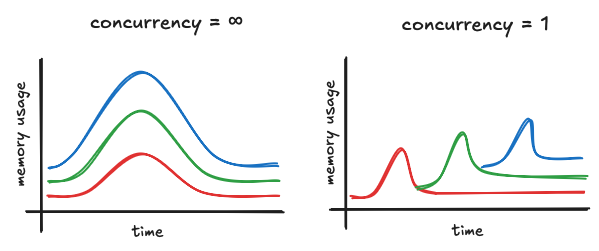
In addition to reducing peak memory usage, limiting hydration concurrency can also speed up hydration, by removing some runtime overhead and loss of locality induced by frequent context switches between multiple dataflows.
Materialize makes use of Linux swap to spill the dataflow memory to disk under memory pressure, enabling clusters to tolerate MV hydration spikes that exceed the size of the available memory. Spilling memory to disk may induce a performance penalty, due to the additional disk I/O required. However, the performance impact is limited to hydration time and doesn’t affect the MV computation in steady state. The MV correction buffer is also implemented with disk-spilling in mind and utilizes an LSM-like data structure to minimize the amount of slow random disk accesses.
Replacing materialized views
We originally invented the self-correction mechanism for materialized views to ensure correctness in the face of output drift. However, as it turns out, the same mechanism is essential for an exciting feature we introduced recently: in-place materialized view replacement.
MV replacement allows modifying the view query of a materialized view in place, or moving its computation between clusters, without loss of consistency. This is a crucial building block for data mesh architectures, in which different teams are responsible for different parts of the SQL graph and upstream teams need the ability to make modifications to their own views. Without the ability to replace materialized views, such modifications require the re-creation of the affected views, as well as all downstream views, including those maintained by different teams.
To replace a materialized view, users perform a two-step process. First they set up a replacement using a CREATE REPLACEMENT MATERIALIZED VIEW command. The replacement is required to have the same output schema as the target MV to be replaced, but it can have a different view query and run on a different cluster. Under the hood, Materialize creates a dataflow with an MV sink that points at the same storage collection that the target MV writes to.
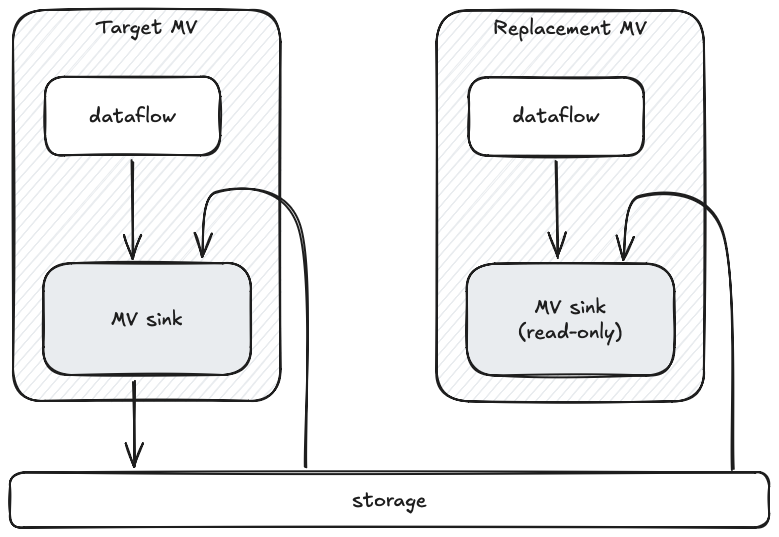
The MV sink comes up in a read-only mode: It isn’t allowed to write to the storage collection yet, but it is able to read its contents and fill its correction buffer. As the replacement dataflow hydrates, the MV sink receives the snapshot of the computation results and pushes those into the correction buffer as well. Once hydration is complete, the contents of the replacement’s correction buffer represent the diff between the target MV and the replacement MV.
Once the replacement has hydrated and has been verified as behaving as expected, a user can apply it using ALTER MATERIALIZED VIEW ... APPLY REPLACEMENT. When that command is issued, the old MV dataflow is dropped and the replacement’s MV sink gains permission to start writing to the output storage collection. It writes out the diff stored in its correction buffer, updating the contents of the storage collection to reflect the replacement’s view definition. From that point on, MV computation proceeds normally with the new definition.
In a way, replacing the definition of a materialized view induces a form of intentional output drift. The self-correction mechanism is key in ensuring we end up with a persisted state that matches the new definition.
Conclusion
Self-correction is how Materialize keeps materialized view outputs consistent even when upgrades change the results of the underlying computation. The core idea is to continuously compare the outputs produced by the dataflow with what has been durably written to storage, and write out the diff so the two converge. In addition to ensuring correctness across version upgrades, self-correction allows replacing materialized views in-place, providing a way to evolve large dependency graphs without having to rebuild them from scratch.
