A Terraform Provider for Materialize

Materialize makes it easy to build streaming applications. After you spin up your first cluster, you can start writing SQL and transforming data in real-time. However, as your Materialize project starts to mature from one materialized view to dozens spread across multiple clusters, you may want to organize and manage your resources in a more sophisticated way.
Many engineering teams have adopted Infrastructure as Code (IaC) to manage their systems, especially as they begin to stretch across multiple cloud environments. Internally at Materialize, no changes happen to any of our accounts without an accompanying code change. Knowing first hand the benefits of managing configurations this way, we are happy to announce our Materialize Terraform Provider (with a Pulumi provider on the way). With this provider you can now manage your Materialize resources as code.
What is Terraform?
Terraform is a declarative Infrastructure as Code framework that manages the desired state of systems. Using configuration code similar to YAML, Terraform will handle the creation, updates and deletion of resources to reach the expected state set in your configuration.
Let’s say you wanted to create a cluster with two replicas in Materialize, you could run the following SQL to create these resources:
1 | |
2 | |
3 | |
4 | |
With Terraform it would look something like this:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
With your configuration files set, you can manage these resources by running Terraform. To create the cluster and replicas you would simply run terraform apply. The underlying provider is then responsible for interpreting your configurations and executing the necessary SQL commands to reach the desired state.
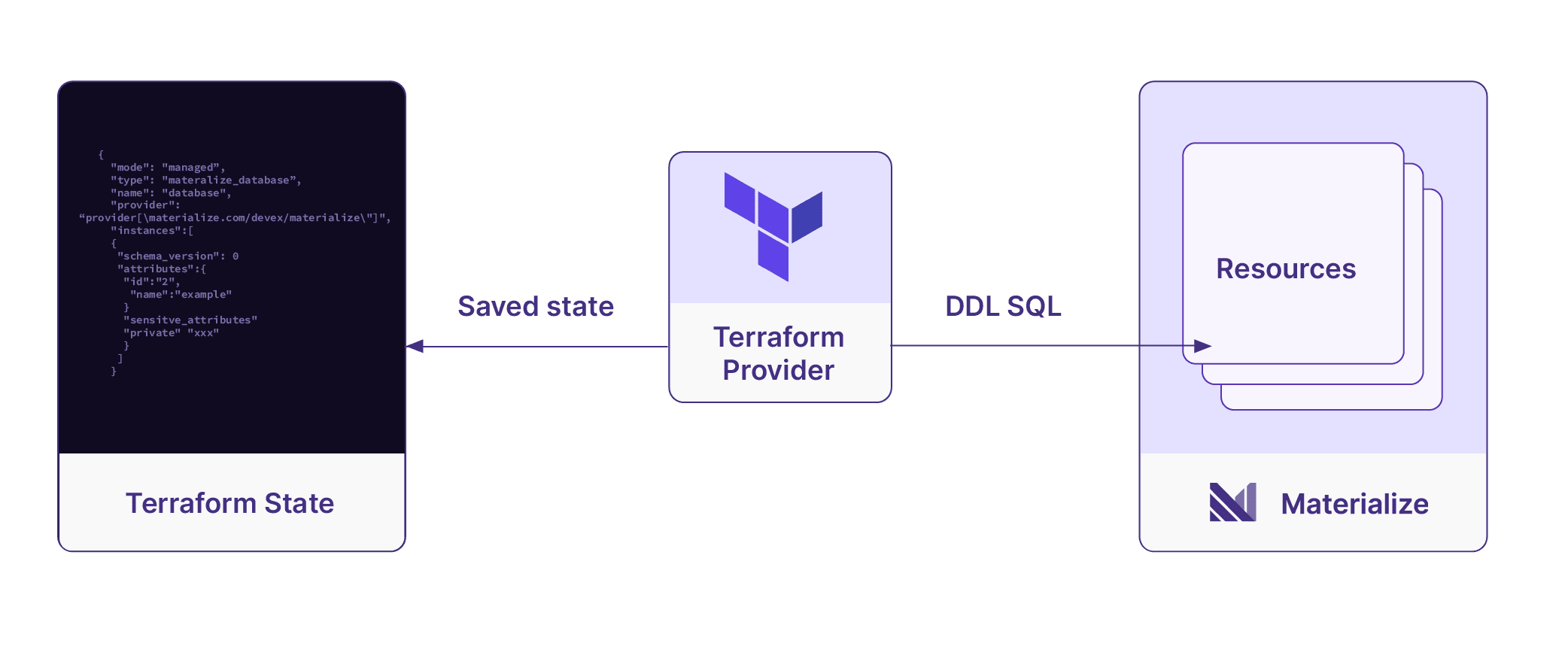
Later if we decide we do not need our second cluster replica, we can simply remove that section from our configuration and rerun terraform apply. Now the provider will compare the current state of our Terraform project against what exists in Materialize. Seeing there is a change that needs to be applied, the provider will delete the unnecessary cluster replica.
Managing your Materialize configurations in one place gives a holistic view of what exists in your account. You can find more details about the individual Materialize resources and how to manage them in the documentation on the Terraform Registry. If you run into any issues or have any questions please feel free to add an issue to the repo.
Provider Ecosystem
Another benefit of managing Materialize with Terraform is that your Materialize resources can be managed alongside other cloud resources and accounts. For those already using Terraform this can help to easily get Materialize integrated with your other systems.
Say you have an AWS MSK cluster deployed that you would like to use via PrivateLink. Since Materialize can read Kafka clusters as a source you probably want to configure your Terraform to join these two resources. Combining multiple Terraform providers allows you to collocate your resource configurations and pass necessary configuration values. This makes it much easier to safely manage your streaming resources and ensure all systems writing and reading from Materialize remain in sync.
Keeping with our PrivateLink MSK example, we will want to pass certain connection details to Materialize when we create our source resources. However we may not know those connection details until the MSK cluster has been spun up. By combining our providers we can correctly resolve those dependencies and pass values between resources. This keeps it simple to manage your entire tech stack in one place without manual intervention.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
dbt Adapter
For those using dbt you may be wondering what the overlap is with Terraform. Many Materialize users rely on dbt to manage their business logic and deploy their SQL models on Materialize as materialized views. This may sound similar to Terraform, but it is better to see them as complementing each other. Using both the dbt adapter and the Terraform provider you can fully manage every aspect of your Materialize applications with code.
So when do you use Terraform vs dbt? Part of this will depend on your team, but you can break it down along a few criteria:
- User needs
- Deployment cadence
- Workflow ownership
User Needs
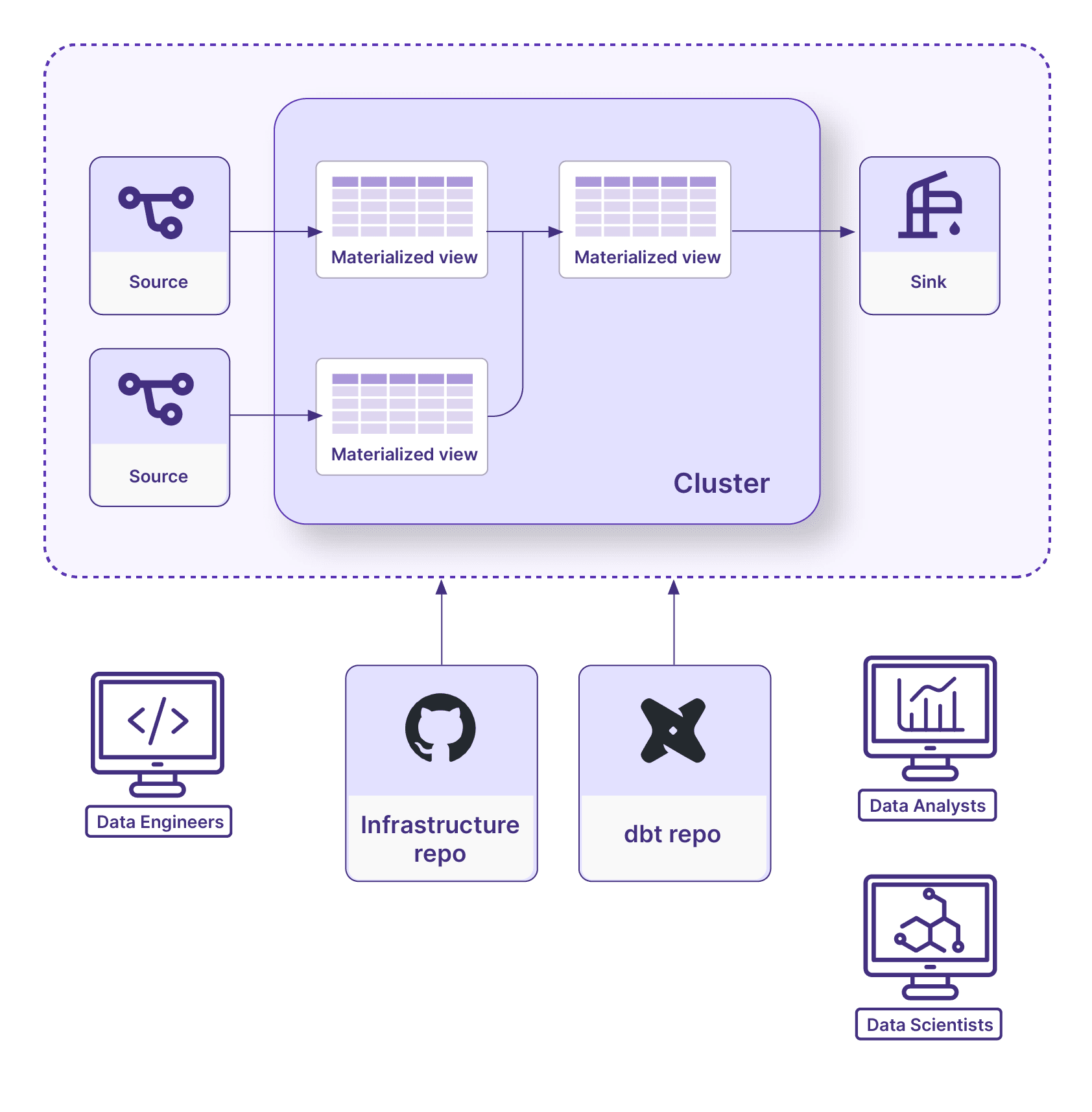
Part of the reason dbt is used by so many teams is it hides the complexities inherent in building data applications. Data teams have a number of specialized roles and not every team member should be responsible for every part of the data stack.
Separating out what is done by different roles also applies to tools. Those who focus on the core business logic and SQL development will be more concerned with the materialized views, so dbt is a perfect interface for them. Data engineers who need to ensure that Materialize is properly provisioned and configured may spend more time in Terraform fine-tuning resources like cluster and replicas.
Deployment Cadence
Another difference between your dbt and Terraform code is the deployment cadence. Regardless of how you organize your code, you likely update your business logic and infrastructure code at different rates.
Even on small data teams it is common to push changes to dbt models multiple times a day. Good analytics teams are able to remain agile and easily make changes as business requests come in. Infrastructure code tends to be much more stable. You might add a new connection and source if you are pulling in new data, or tweak a cluster replica size down the line when data volume increases but overall these resources tend to see fewer day-to-day changes than the materialized views
Keeping business logic in dbt and infrastructure in Terraform allows you to decouple these workflows and ensures that both can be tailored to specific cadence and need.
Workflow Ownership
When I worked on data teams and would onboard analysts, one thing they would often say is “I just don’t want to break anything.” I usually replied “If you break something, I made a mistake.” This is something you should keep in mind when deciding what should be managed and owned by dbt vs Terraform. At a high level, your dbt project should not manage resources that the dbt project cannot safely delete.
It is perfectly appropriate to have dbt manage your materialized views because dbt is responsible for creating and dropping those resources as part of its normal workflow. However, dbt should not manage the creation of a resource like connections. Most connections only need to be created once and contain references to secrets which likely contain sensitive data (such as passwords). Managing resources like this do not fit as easily into a typical dbt run.
Another example where it might make sense to have dbt own the resource is with something that is ephemeral and only exists as part of the dbt run. If your dbt project contained a macro to create a short-lived cluster separate from production to run your models during testing, that makes sense as it is part of the dbt workflow. You would not want analysts to run a Terraform apply every time you wanted to test out some logic change within your models. Going back to our discussion around users, we want users to remain in their area of expertise and do as little context switching as possible.
Conclusion
Data applications are no longer peripheral to the organization. Many are part of the critical path and kept to the same engineering standards as the core application. We hope our Terraform provider will make it easy to incorporate your resources as part of your existing IaC stack or help if you are new to managing your infrastructure with code.
