Vector database pipelines made easy

Vectors have become a foundational data structure for AI. Modern vector databases are quickly becoming essential infrastructure for AI-native teams, but they're only as good as the context you feed them. At the surface, working with vector databases is simple: take unstructured data, embed it, and write to your database along with attributes for filtering and reranking based on business logic.
Unfortunately, building the real-time pipelines to keep those attributes fresh is extremely difficult. Consider a simple example: when a user's permissions change in your operational database, how quickly can you reflect that change across millions of vectors? Every minute of lag is a minute where users might miss critical information they need or worse: see results they shouldn't.
The problem is that traditional approaches to data ingestion force a difficult choice: either accept stale attributes (and poor user experiences), or burn compute cycles recalculating attributes—on write if you're storing attributes directly in your vector database, or on read if you're joining them externally via pre or post-filtering. At scale, most teams cobble together specialized pipelines trying to thread this needle – CDC streams, read replicas, cache layers, and queue systems – creating a web of complexity that's fragile, expensive, and full of correctness issues.
The stakes couldn't be higher. Getting this right is the difference between agent responses that seem accurate and relevant, and lost trust in yet another AI initiative. Unfortunately the design patterns for doing this correctly are usually out of reach due to time or budget constraints.

In this post, you'll learn how Materialize can streamline your vector database ingestion pipeline by keeping attributes up to date to support filtering and reranking on fresh, correct data. The key is using incremental view maintenance to move core denormalization work from a reactive approach where the work happens on demand, to a proactive one, where work happens as source systems change.
We'll use turbopuffer as our primary example throughout this post. We'll also use a customer support system as our domain example.
Attribute Filtering
Vector databases increasingly support applying filters based on attributes (structured data) during vector search, rather than only through pre- or post-filtering. Turbopuffer pioneered an approach to this problem called native filtering, which improves both performance and recall by finding results based on similarity and filters simultaneously.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
To enable native filtering, you need to write attributes alongside your vectors. While embedding is a well publicized cost, the hidden expense is calculating correct and relevant attributes from your operational data.
Example vector representation: "Payment timeouts after deploy 8451" → [0.2, -0.4, 0.8, ...]
Full payload example:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
Attributes may look simple but they're often the result of expensive data transformation, or denormalization, potentially across multiple operational systems. Computing a single ticket's attributes might require joining customer data, aggregating lifetime order values, calculating support history metrics, checking SLA breaches, and combining it all into composite scores. Correctly reflecting the consequences of a single write can mean scanning millions of records.
These costs are in tension with getting the best search experience by putting as much context as possible into your vector database.
The Missing Element: Incrementally Updating Attributes
To resolve this tension, you need to think differently about when, precisely, you do the work to calculate attributes. This is where Materialize comes in.
info
Materialize ingests data continuously from source systems, typically from operational databases or Kafka. Then, instead of reactively scanning millions of rows to recompute, say, a priority score when a relevant update happens, Materialize proactively maintains a live representation of each ticket's priority scores along with live models of intermediate metrics.
As writes come in, Materialize does work proportional to the data that actually needs to change, rather than the complexity of the transformation itself.
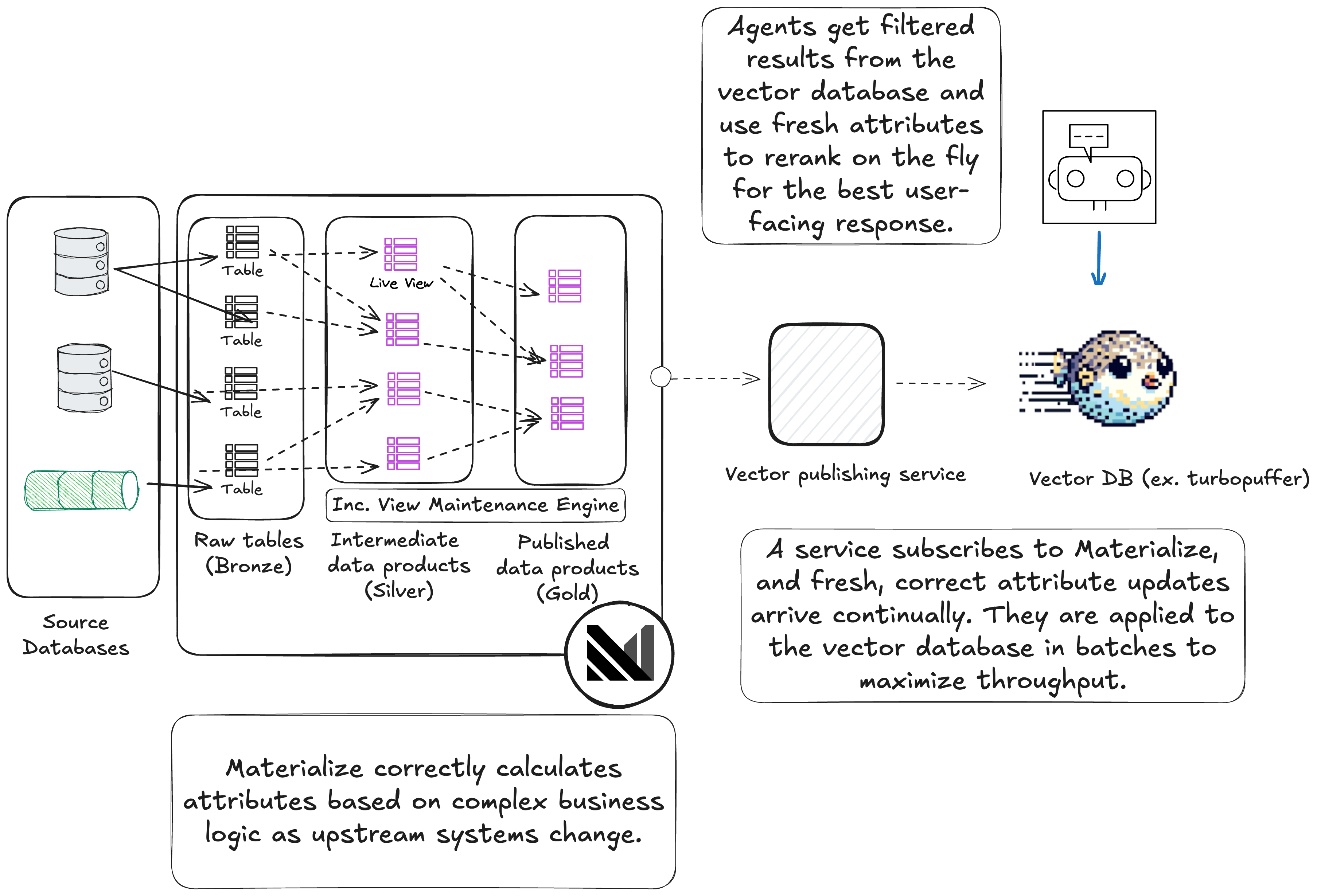
Materialize works by creating SQL views that build up into "data products." These data products typically represent the core entities of your business like customers, orders, or projects. Here's an example of a ticket data product built from lower level attributes.
First create the intermediate data products of customer_ltv and support_metrics.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
Then build those up into the final data product, ticket:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
23 | |
24 | |
25 | |
26 | |
27 | |
28 | |
29 | |
30 | |
31 | |
32 | |
33 | |
34 | |
35 | |
36 | |
37 | |
38 | |
39 | |
40 | |
41 | |
42 | |
43 | |
44 | |
45 | |
46 | |
47 | |
48 | |
49 | |
If Materialize only created views like a traditional database, it would compute results reactively, when queries arrived. You would add indexes to underlying tables to speed things up a bit, but ultimately every time a vector was written or needed to be updated, to get the latest attributes it would grind over millions or billions of rows while applying business logic.
The breakthrough with Materialize is that instead of just indexing tables, you can index the views themselves. When you do this, the view becomes incrementally and continuously maintained as writes (including updates and deletes) happen upstream:
1 | |
2 | |
3 | |
Behind the scenes, when you index a view, Materialize creates dataflows that do the minimum work to keep views current as writes arrive, rather than performing expensive computation on reads. It then goes through a one-time process of hydrating those dataflows to get the initial state of the view.
For larger workloads, the state required to do this is stored across memory and disk. In our example, when a subscription changes or a refund occurs, only the affected view rows update incrementally.
This shifts computation from query time (reactive) to write time (proactive), giving you ~10 millisecond access to fresh derived data for point lookups on indexes, while still preserving the ability to do ad hoc transformations for business logic that can't fully be pre-computed. Importantly, ad hoc queries against maintained views still vastly outperform doing the same query against a relational database because so much of the heavy lifting was done in the incrementally and continuously maintained views.
While updates take a few more milliseconds to reach Materialize than a database (because they have to first be written to the database and then replicate into Materialize), because Materialize maintains underlying data products, the queries are much faster than the original system. The most surprising thing here is that if you write to an upstream database, Materialize can calculate the correct attribute value reflecting that update faster than the database you originally wrote to!
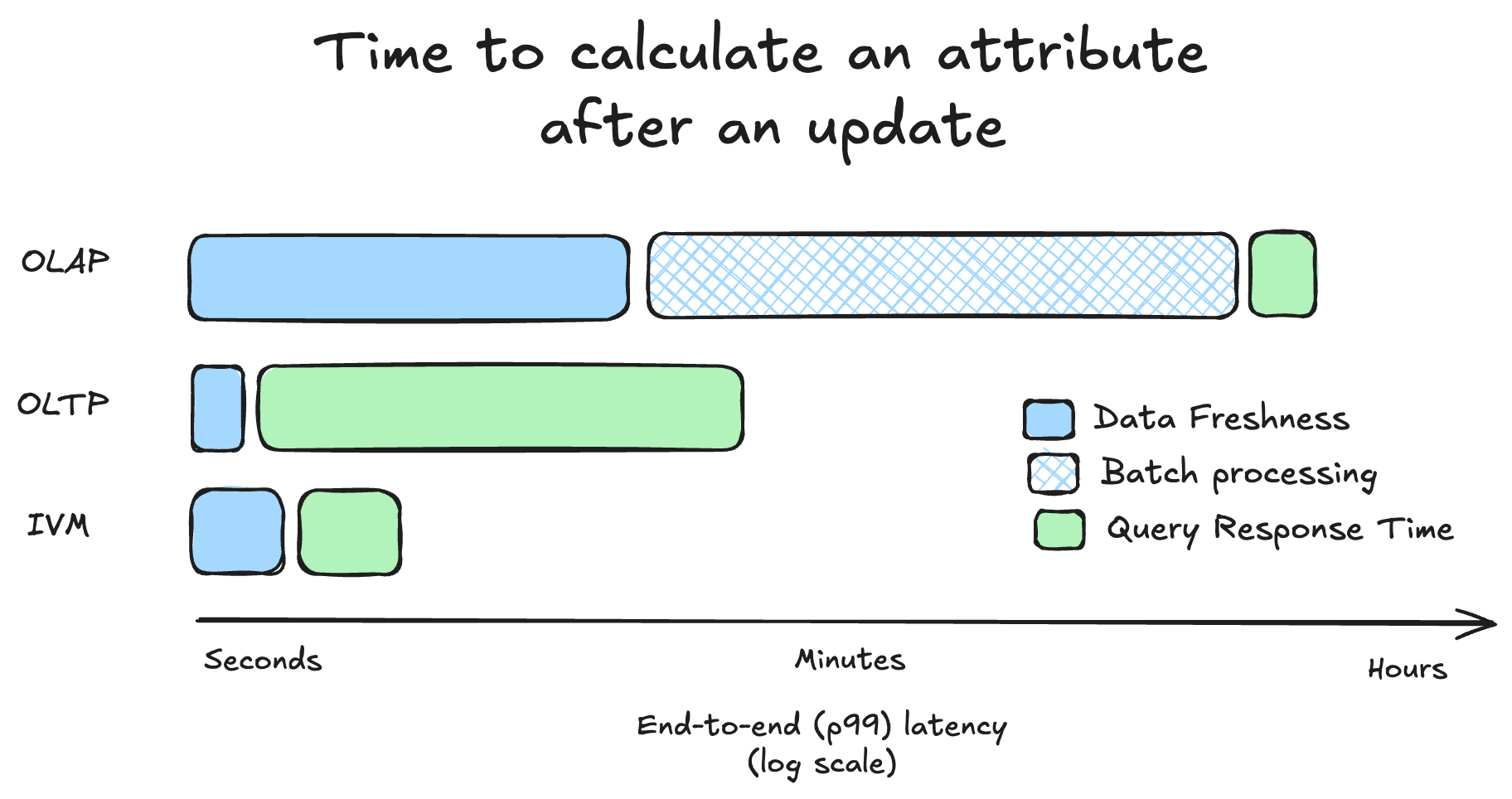
Now when some upstream event happens, Materialize can reflect the correct result within a few hundred milliseconds of the event happening in the real world, orders of magnitude faster than issuing this same query from a replica and with much greater freshness than traditional data pipelines.
Once your views are maintained in Materialize, you can subscribe to changes and push them to your vector database:
1 | |
At scale you'll likely queue up many updates from subscribe so you can update your vector database in batches to maximize throughput.
Finally, when a client or agent queries your vector database it will get filtered results, while also getting any attributes it needs for reranking before sending the final response to end users.
The Architectural Breakthrough
With Materialize in your vector database pipeline, the fundamental tradeoffs for operating with vectors, and search more broadly, change. You can now choose where each attribute lives—in your vector database or external—based on write patterns rather than computational complexity.
Storage Strategy
Traditional architectures force you to choose between expensive denormalization when writing to your vector database or expensive denormalization when reading from it. Materialize eliminates this tradeoff by making what was formerly heavy lifting now continual and incremental.
Act confidently on live context
For production AI initiatives using vector databases, your entire vector pipeline matters. Bottlenecks in your ability to ingest context quickly and correctly will fundamentally limit the experiences you can deliver.
Materialize offers a solution by providing incrementally-updated views that keep your vector database attributes fresh. Beyond just fresh attributes, Materialize opens the door to extremely efficient pre- and post-filtering by enabling complex joins against live tables. Finally, by tracking exactly when important context changes, Materialize provides a foundation for surgical re-embedding that keeps context fresh while massively reducing inference costs compared to wasteful batch approaches.
Of course, Materialize adds cost and complexity to your stack, but it typically pays for itself through reduced compute infrastructure and dramatically improved developer productivity.
Whether you're building complex agent workflows or simple semantic search features in your applications, adding Materialize into your vector database pipeline gives you fresher context, better recall, and lowers the total cost of your entire vector stack.
Ready to deliver a better search experience to your customers? Try Materialize on your laptop, start a free cloud trial, or deploy to production with our free-forever community edition.
