Virtual Time for Scalable Performance | Materialize
June 14, 2022

Materialize allows you to frame SQL queries against continually changing data, and it will compute, maintain, and serve the answers even as the underlying data change.
Consistency is a watchword at Materialize. We are able to maintain query outputs that at all times correspond exactly to their inputs. This is a solution to the cache invalidation problem, one of the core hard problems in computer science.
That sounds like a bold claim, so there is probably a catch. For sure, you could reasonably imagine that the problem can be solved "in the small". One carefully written process or tightly coupled system could work hard to keep everything in check. The issues arise when your system needs to grow, to involve more and varied resources. The complexity of managing all of their behavior causes systems (or their properties) to collapse.
As it turns out, the mechanisms Materialize uses for consistency do scale to large systems. In this post we'll explain those mechanisms, and outline our plans for scaling out Materialize to a platform for consistent, continually changing data.
Some context
Materialize is undergoing a fairly dramatic internal architectural shift. It has historically been a single binary, with some scale-out aspirations; one that handles data ingestion, incremental view maintenance, and query serving, all in one place. This design has changed, to one with separated storage, compute, and serving planes, so that each plane can operate and scale independently. You can ingest arbitrary volumes of data to elastic storage (think S3), you can spin up unlimited numbers of compute instances to read from, transform, and write this data back, and you can serve results to as many concurrent connections as you like.
With all of these ambitions, how do we avoid racing forward with tangled shoelaces and landing immediately and forcefully on our face? How do we achieve both strong consistency and scalable performance, for continually changing data?
Materialize's consistency mechanism
Materialize uses virtual time as the basis of its consistency properties.
Virtual time is a technique for distributed systems that says events should be timestamped prescriptively rather than descriptively. The recorded time says when an event should happen, rather than when it did happen. That may sound a bit funky, and virtual time is definitely not for all systems. It is however a great fit for systems tasked with maintaining views over data that undergo specific, externally driven changes.
Materialize records, transforms, and reports continually evolving, explicitly timestamped histories of collections of data. These explicit histories promptly and unambiguously communicate the exact contents of a collection at each of an ever-growing set of times. If we are doing our job well, these times are always pretty close to "right now", and if you want that answer you just have to wait a moment.
Once input data are recorded as explicit histories, the potential confusion of concurrency is largely removed. Problems of behavioral coordination are reduced to "just computation": components must produce the correct timestamped output from their timestamped input, as if the input changed at the recorded times and the component responded instantaneously. The components are not themselves required to run in that exact sequence, though (nor instantaneously). Much of Materialize's machinery is then about efficiently computing, maintaining, and returning the specific correct answers at specific virtual times.
Virtual time is related to multiversioning, used by traditional databases for concurrency control. Multiversioned systems maintain recent historical values of data, potentially several, to decouple the apparent and actual changes to the data. However, these multiple versions are usually cleaned up as soon as possible, and only rarely exposed to the user. Multiple versions are a first class citizen in Materialize's data model, rather than an internal mechanism for optimizing performance.
Materialize's Unbundled Architecture
Materialize is architected in three layers: Storage, Compute, and Adapter. Virtual times are the decoupling mechanism for these layers.
- Storage ensures that input data are durably transcribed as explicit histories, and provides access to snapshots at any virtual time and subscriptions to updates from that time onward.
- Compute transforms explicit input histories into the exactly corresponding explicit output histories, and maintains (adds to) those output histories as the input histories evolve.
- Adapter maps user actions (e.g.
INSERT,SELECT) to virtual times, to present the users with the experience of a transactional system that applies operations in sequence.
The three layers do not need to have their executions coupled. Their behavior is only indirectly synchronized through the availability of virtual timestamps in the explicit histories.
Importantly, each of these layers can be designed independently, and their operation scaled independently. As we'll see, these designs will follow different principles, and will avoid scaling bottlenecks with different techniques.
Storage: Writing things down
The Storage layer is tasked with durably maintaining explicitly timestamped histories of data collections.
Storage is driven primarily by requests to create and then continually ingest "sources" of data. There are various types of sources, detailing where the data come from, its format, and how to intepret each new utterance about the data. However, all sources have the property that once recorded they present to the rest of Materialize as explicitly timestamped histories of relational data. Storage captures this representation, maintains it durably, and presents it promptly and consistently.
Storage is the place we pre-resolve questions of concurrency in data updates. The virtual time an update is assigned becomes the truth about when that update happens. These times must reflect constraints on the input: updates in the same input transaction must be given the same virtual time, updates that are ordered in the input must be given virtual times that respect that order. Once recorded, the explicitly timestamped history is now unambiguous on matters of concurrency.
Storage's scalability relies on the independence of timestamp assignment for unrelated sources. Sources can be spun up in independent containers, added as new sources are defined and retired whenever they are dropped. The containers are each capable of scaling horizontally as the inputs permit (e.g. through partitioned Kafka topics) and recording sharded output. Behind the scenes, elastic cloud storage ensures that there needn't be bottlenecks for writing or reading these histories.
Compute: Transforming data
The Compute layer is tasked with efficiently computing and maintaining views over explicitly timestamped histories of data collections.
Compute is implemented by differential dataflow atop timely dataflow. These are high-performance, scale-out dataflow systems, designed exactly for the task of maintaining consistent views over changing data with high throughput and low latency. The output of these systems are the output histories that correspond exactly to the transformed input histories.
Compute achieves scalability by independently deploying bundles of dataflows, relying on the determinism of differential dataflow to provide consistency between otherwise independent bundles. Stacks upon stacks of views lead to dataflows whose output histories nonetheless align exactly at each virtual time, because that is what differential dataflow does. These dataflows can run on independent resources, with performance and fault isolation, and can each be themselves scaled horizontally.
Adapter: Serving results
The Adapter layer is tasked with assigning timestamps to users actions to present the experience of a system that moves forward sequentially through time.
Users come to Materialize looking for the experience of a SQL database and strong consistency guarantees. However, they likely do not know about virtual time, and their SQL queries certainly do not. The users hope to type various SELECT and INSERT flavored commands, perhaps surrounded by BEGIN and COMMIT, and would like the experience of a system that applies the commands of all users in one global sequence.
This does not mean that Materialize must actually apply these operations in a sequence, only that it must appear to do so.
Adapter assigns a virtual timestamp to each user command, which determines their intended order. Once this has been done, the apparent operation of the rest of the system, and specifically updates to managed tables and query results returned back, are all "determined". Materialize still has some work to do to actually return the results, but the coordination problem has been reduced to producing the correct answer for the virtual time.
Adapter scales largely by avoiding substantial work on the critical path of timestamp assignment. Several concurrent SELECT commands can be assigned the same virtual timestamp and deployed concurrently. Several subsequent INSERT commands will get a later timestamp and not be reflected in the prior writes, by virtue of the timestamps rather than the order of execution. The virtual timestamp assignment is relatively cheap compared to the Storage and Compute work the commands translate into.
Putting the pieces back together
Virtual time underlies Materialize's consistency guarantees, and its decoupled architecture. Independent components coordinate only indirectly, through the availability of virtual times in explicit histories. Their actual implementations operate as efficiently as they know how.
Diagram of timestamping and consistency behavior across Materialize services.
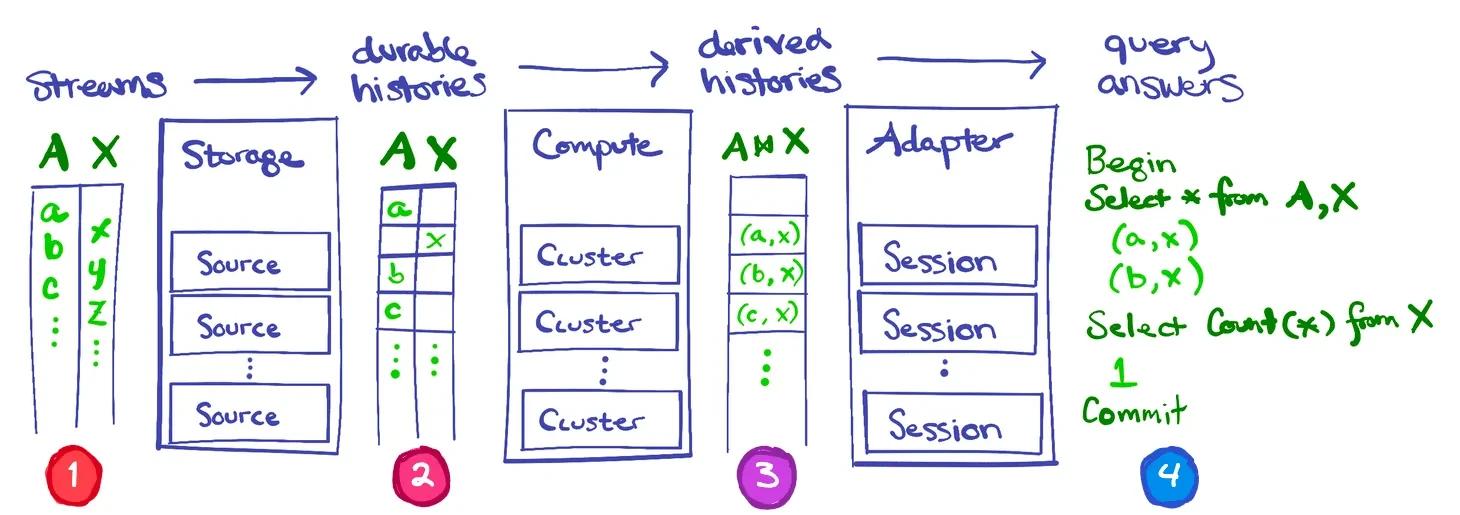
<strong style={{"color":"#db001e"}}>(1) Each stream is individually ordered, but are not correlated with each other.
<strong style={{"color":"#b10349"}}>(2) Histories introduce a common reckoning that respects the ordering requirement for each stream (but gets to choose how they line up).
<strong style={{"color":"#9430a3"}}>(3) Derived histories should exactly track the correct answers of the input histories.
<strong style={{"color":"#3455cf"}}>(4) Within the same transaction, adapter is looking at the same "snapshot" of data and thus able to provide correct results.
This decoupling allows scalable, robust, distributed implementations of low-latency systems, which .. is just really exciting.
