Cloud Data Warehouse Uses & Misuses | Materialize
July 27, 2023

Cloud Data Warehouses (CDWs) are increasingly working their way into the dependency graph for important parts of the business: user-facing features, operational tools, customer comms, and even billing. Running this kind of operational work on a CDW might look promising initially but companies paint themselves into a corner as workloads expand: Either the cost (in warehouse invoices) to deliver the work outpaces the value delivered, or hard performance limits inherent to the design of analytical data warehouses prevent teams from delivering the capabilities necessary to serve the work in production.
Why? Operational workloads have fundamental requirements that are diametrically opposite from the requirements for analytical systems, and we're finding that a tool designed for the latter doesn't always solve for the former. That said, teams running operational work on the warehouse aren’t completely irrational. There are many good reasons for building this way, especially initially.
What is operational?
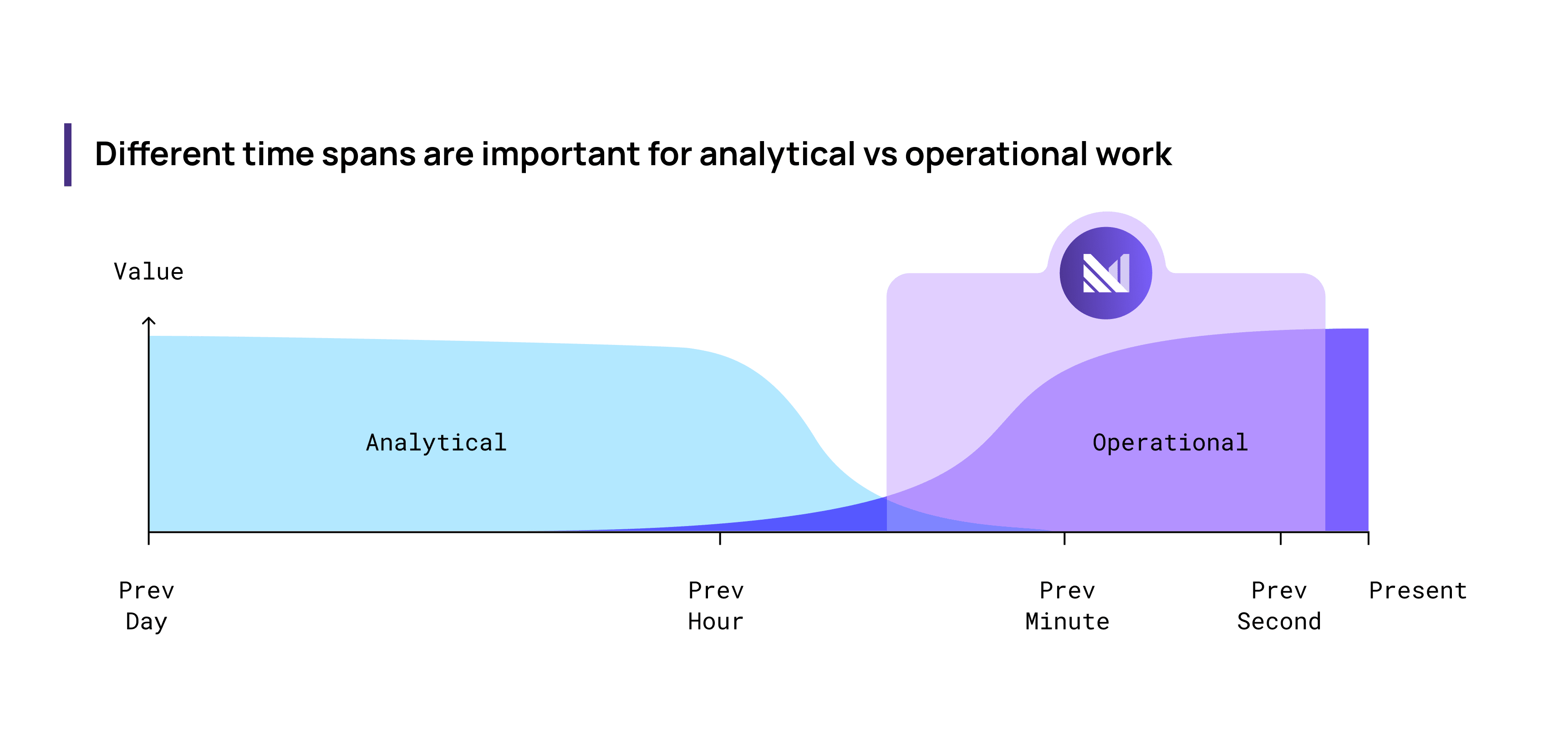
First, a working definition. An operational tool facilitates the day-to-day operation of your business. Think of it in contrast to analytical tools that facilitate historical analysis of your business to inform longer term resource allocation or strategy. If an operational system goes down for the day, there are people who will either be unable to do their job, or deliver a degraded service that day.
To simplify things, most operational work can be generalized as automated interventions in the business.
How is it different?
Going deeper into the technical requirements for analytical vs operational workloads, there are clear conflicts:

Static data is a feature for analytical work, but a bug for operational work.
When you’re doing iterative exploratory analysis or navigating between business reports, it’s convenient to be able to lock the input data down as a constant and assume only the SQL is changing. But in operational workloads it’s reversed: You want to lock down the SQL and always get as close as possible to the "current state" of data to operate on. You don’t want to send notifications that no longer apply to customers.
Analytics needs historic data, operations needs fresh data.
Looking at how data changes over time is crucial to analytics, but less so for operations where you mainly just want the data to be as fresh as possible.
Ad-Hoc SQL queries are a vital part of analytical work, but not operational.
For analyst productivity, analytical tools need to be ready to answer a new SQL query fast, and most CDWs are really optimized for this (and make architectural tradeoffs to make this fast). The operational workload, on the other hand, is more akin to traditional software development: SQL might need to be iteratively written on a smaller scale of data in a dev environment, but in production the SQL is locked down by design.
Uptime is nice to have for analytics, but it's mandatory in operations.
This one is pretty self-explanatory. Yes, downtime is always annoying, but an operational system going down at 3am results in a pager going off and sleep being ruined. This is seldom the case for an analytical system.
It's not all opposites, though. Both types of work add value by combining different sources of data. Both use SQL queries that are complex, join-heavy, multi-level. Both need to handle many different team's workflows without disruption. A tool built from the ground up for operational purposes might share some design choices with analytical ones, but the differences add up to some pretty stark inefficiencies in both data freshness and total cost.
We come to praise Cloud Data Warehouses, not to bury them
In spite of all this, data teams continue to expand into operational work on the warehouse. Why? We asked, here’s what comes up as motivating factors:
The warehouse is often the first place the data can even be joined.
Because operational source data is coming from multiple systems, the value is in joining that data together - when we see this signal and this other signal, take this action. If the two signals are coming from a SaaS tool and your transactional database, joining the two sources in application logic can get complicated. In contrast, a single data engineer can set up the loading and integration of data once, (sometimes it’s as simple as a few clicks in Fivetran) and other teams rarely have to come back with change requests to the pipelines. They just work autonomously in the warehouse, in SQL. It’s appealing to stretch that model to cover operational work.
The SQL that analysts write lives after them.
The warehouse is where the SQL is first prototyped. Many operational use cases start with a hypothesis, which needs to be validated with data. The correct place to do that is on your historical data in your CDW. So data teams find themselves with a fully prototyped use case, pondering, well, how do I get the data out of the warehouse and into my operational tools?
It's a way to centralize complex business logic.
Keep in mind that this isn’t a “SQL vs Code” decision: it’s often a “SQL vs opaque point and click integrations” or “SQL vs microservices without clear owners” decision. Operational workloads are often hidden in glue code, API configuration, and scripts whose creators have long since left the company. SQL, especially the kind that’s tracked in git repos and organized in dbt projects, is the superior alternative.
It unlocks SDLC best practices.
Dev/Stage/Prod workflows, automated tests, change review via pull requests, CI/CD, centralized logging… All these things are becoming central to the way modern data teams manage a growing scope of responsibility.
How did data teams get here?
Teams like Superscript find Materialize after hitting limits in warehouses, but reverse ETL tools like Census and Hightouch are evidence that others can succeed running some amount of operational work on the warehouse. Here's why:
The data size frog is boiled slowly.
Companies logically put in place "modern data stack" tooling to tackle the historical analytics workloads, and as warehouses have lowered the low-end cost to make themselves viable even for smaller businesses, companies are starting this journey earlier and earlier. Operational workloads can particularly look viable early, purely because of the small scale of data involved. Data freshness becomes a problem over time as datasets grow, and the ETL pipeline goes from minutes to hours.
It’s possible to throw money at the problem.
Initially, companies can pull (expensive) levers in the warehouse to keep up with operational requirements: They can load data/run dbt more frequently, upgrade the resources dedicated to doing the work, and generally spend more to alleviate freshness.
We spoke to a company that prototyped fraud detection logic in their warehouse. Initially it was workable, data was loaded every 30 minutes and the query completed in 5 minutes. But as they grew, the data for the query grew, causing it to take more than 30 minutes to complete. Eventually they were running compute 24hrs a day just to deliver stale fraud-detection data at hourly intervals. This happened gradually.
It's possible to throw (engineering) time at the problem.
There are upfront pipeline optimizations that can be done on analytics warehouses, but they only buy performance with complexity. dbt has a useful solution for lowering the amount of data you work over: incremental models that let you specify logic to only take the changed rows, and merge it up. Unfortunately, this requires rewriting your SQL, handling new concepts like late arriving data, and essentially defining an entire lambda architecture in SQL, with all its associated pitfalls.
Ultimately, we believe serving operational workloads out of a data warehouse is a dead end: Either you run into a hard technical limit that forces you to walk back everything and initiate a major rebuild, or you run out of money as you approach those limits, because you’ve given it all to the warehouse so you can treat it like an OLTP database. That brings us to our next point:
Can you extend an analytical data warehouse to serve operations?
Warehouses themselves and an ecosystem of tools around them have recognized this trend and begun adding features to enable operational work, but that won’t solve the core problem. We argue that it comes down to the query model and architectural tradeoffs that were made to solve analytics users first.
The core of the problem: A batch/orchestrated query model.
Somewhere deep in the bowels of a datacenter, servers are repeatedly pulling your entire universe of business data out of object storage, running a massive computation on it, and caching the result. They do the same amount of work every time, even when only a few rows of input and output data change, unless you do the delicate work of writing incremental models. Getting operational outputs to update when the inputs change is also a delicate exercise of chaining together a waterfall of loads, transforms, and reverse ETL syncs.
As a result of the query model, the rest of the architecture is misaligned with operational requirements too:
A fragile serving layer.
The first thing every tool querying a CDW does is cache the results (now you have to monitor and worry about cache invalidation, which usually adds a surprising amount of staleness). This is because the query interface is just not designed for operational use-cases. There are hard, low limits on query concurrency, and point look-ups (SELECT * FROM my_cached_table WHERE user_id=123;) are costly and not performant when queried directly from the CDW, so Redis it is.
Loaders optimized for infrequent updates.
The problem also works its way into upstream tools, services, even APIs that are two degrees from the warehouse. Every loading service is designed to build up a batch of updates and merge it in as infrequently as possible.
How will operational work be handled in the future?
Data practices are rapidly evolving, and always have. Consider how our use of CDWs evolved over time: Businesses organically found the ELT model, starting with Looker's persistent derived tables (PDTs). Then the dbt community took a step back to look at the problem and emerged with a generalization of this to use SDLC practices to manage the full complexity.
We think that the next step in the eternal quest to deliver more shareholder value is that data teams work will tend towards unlocking production, operational use cases. Operational use cases will drive data teams to pick products that are designed from the ground up to service operational workloads. But that doesn't mean that data teams will have to give up their tooling. The modern operational tools will have to meet data teams where they are - with dbt, SQL, and a cloud-native design.

