
info
If you’re not familiar, Materialize is an operational data store, the functional complement to an analytical data warehouse. Whereas an analytical data warehouse lets you use SQL to analyze the past, an operational store lets you write SQL to describe and drive future operations. The moment your data changes, an operational data store reacts. It will propagate the changes through a cascade of SQL views, maintained indexes, and downstream consumers.
Today we’re launching a new way to get data into Materialize: Webhooks! This means that, in addition to streaming in data via Kafka and from Postgres databases via replication, you can also bring in a long tail of data from SaaS tools, platforms, services, really anything that lets you send data via HTTP POSTs.
What are Webhooks?
Webhooks are an almost universally supported way to send event-driven data between two applications. You provide the external application with a URL, and when the application takes some action, it sends you an event. Most applications have native support for webhooks, like Segment or Amazon Web Service’s EventBridge, but for applications that do not, tools like Zapier or IFTTT provide the necessary glue for your workflow.
Why we built a Webhook source for Materialize
These may look like a toy next to their sibling Kafka and Postgres Sources, but they scale to millions of events per day and are vitally important to making Materialize a fully connected operational data store. Here’s why:
Centralize event-driven workflow logic in SQL in an operational store
With webhooks + Materialize, you can build fully event-driven operational workflows that start with an action somewhere outside Materialize, push an event payload in, enrich and process the data through any amount of business logic in SQL, and push updates out to connected systems on the other side.
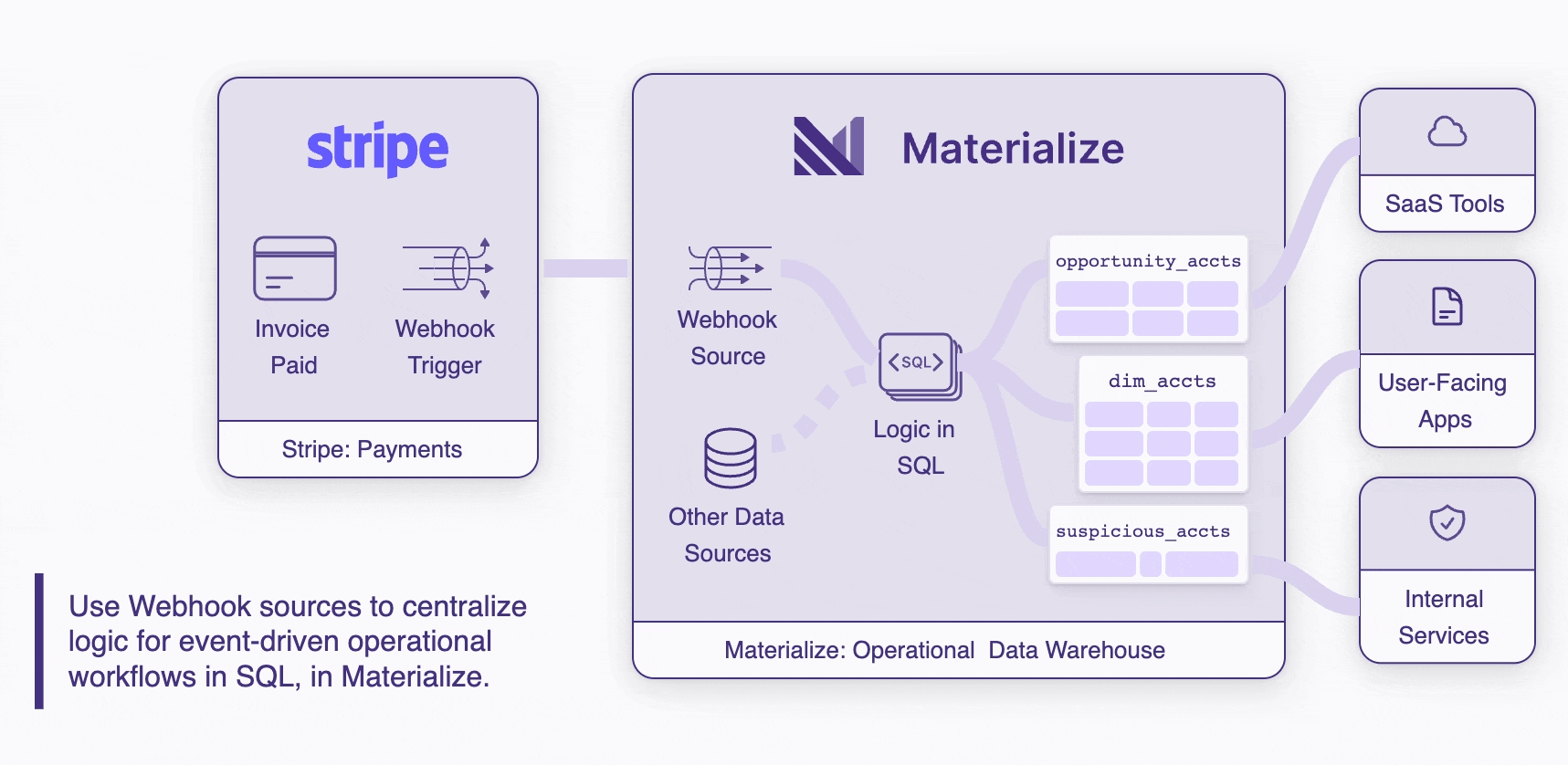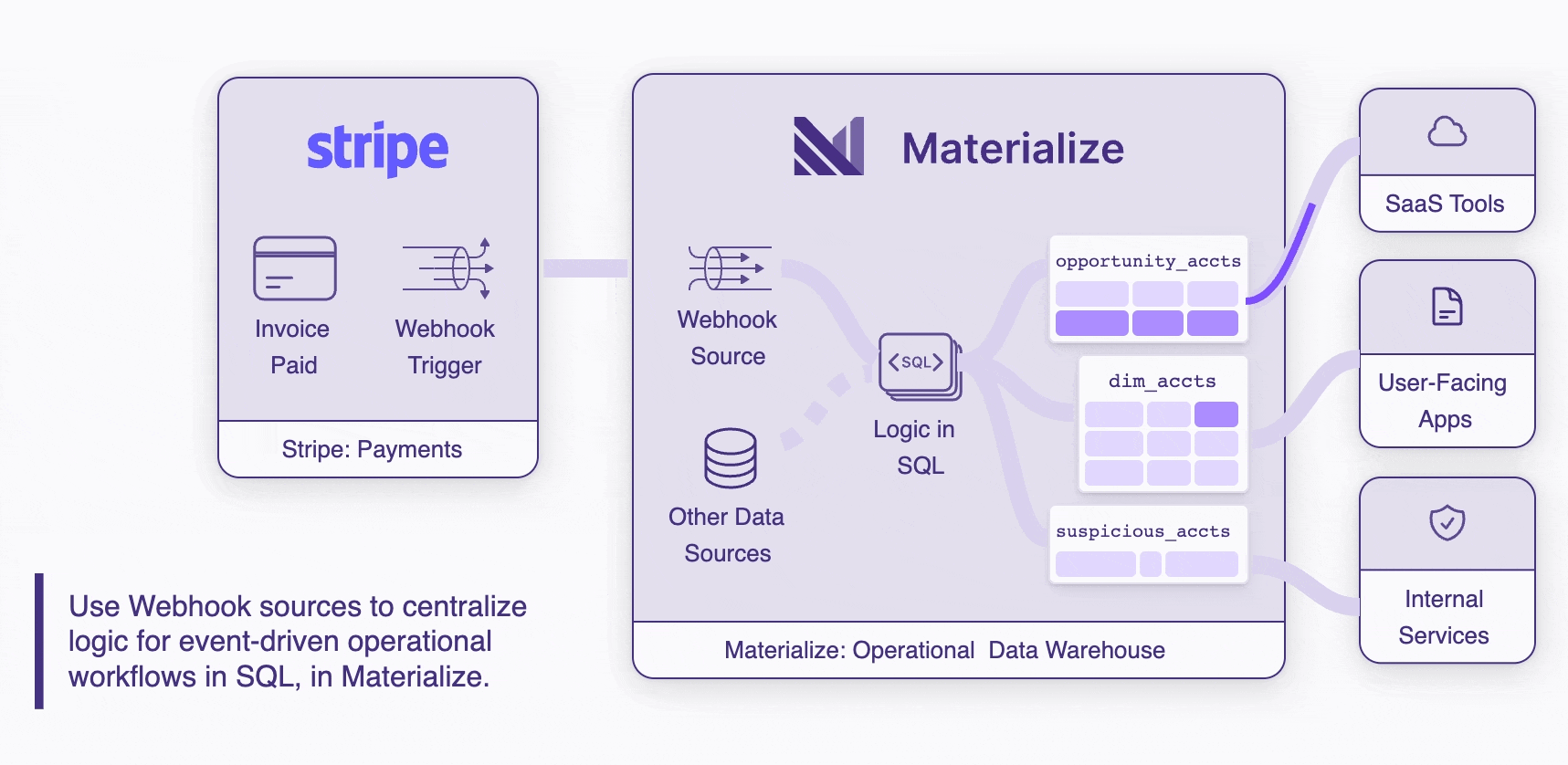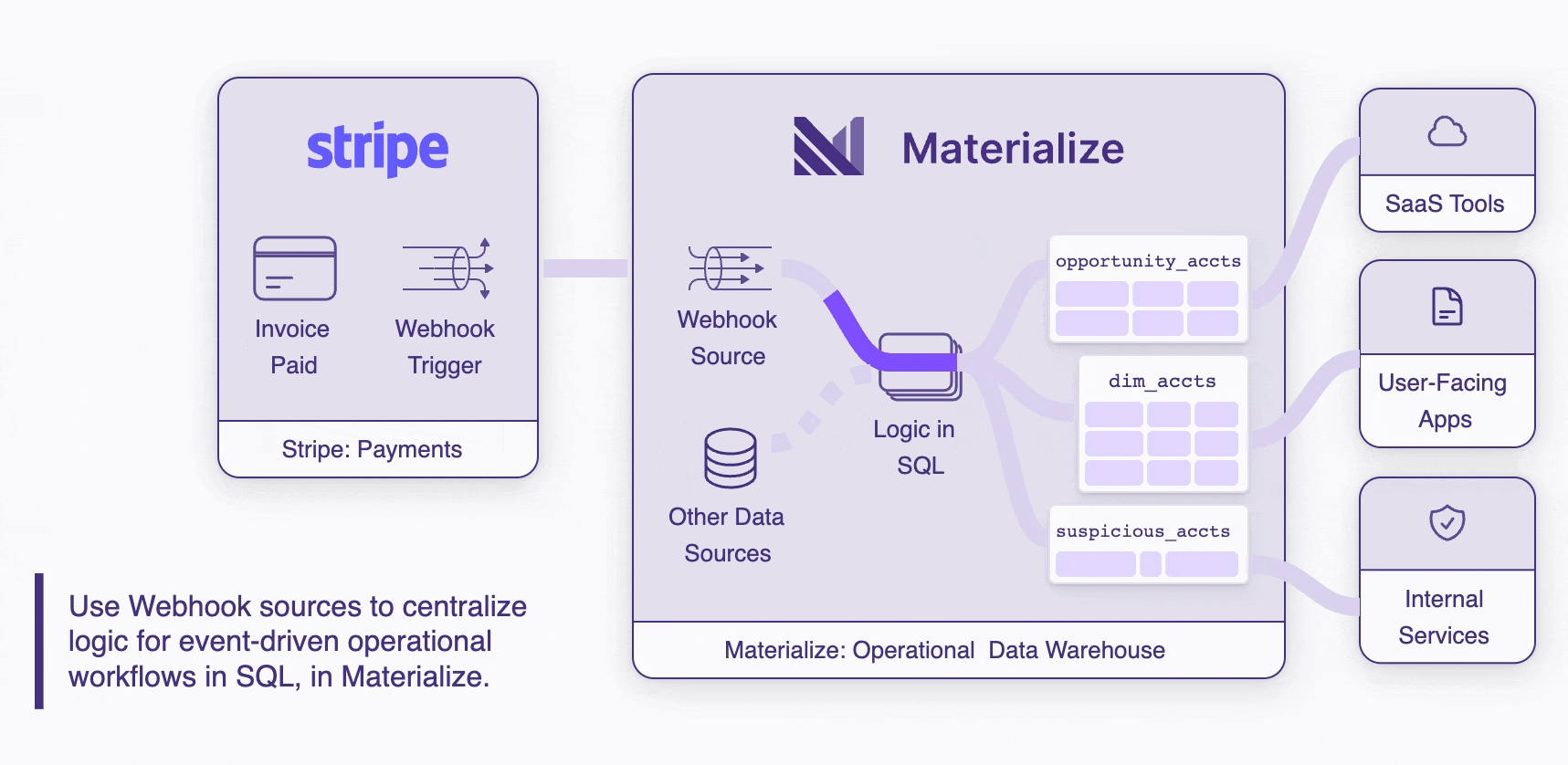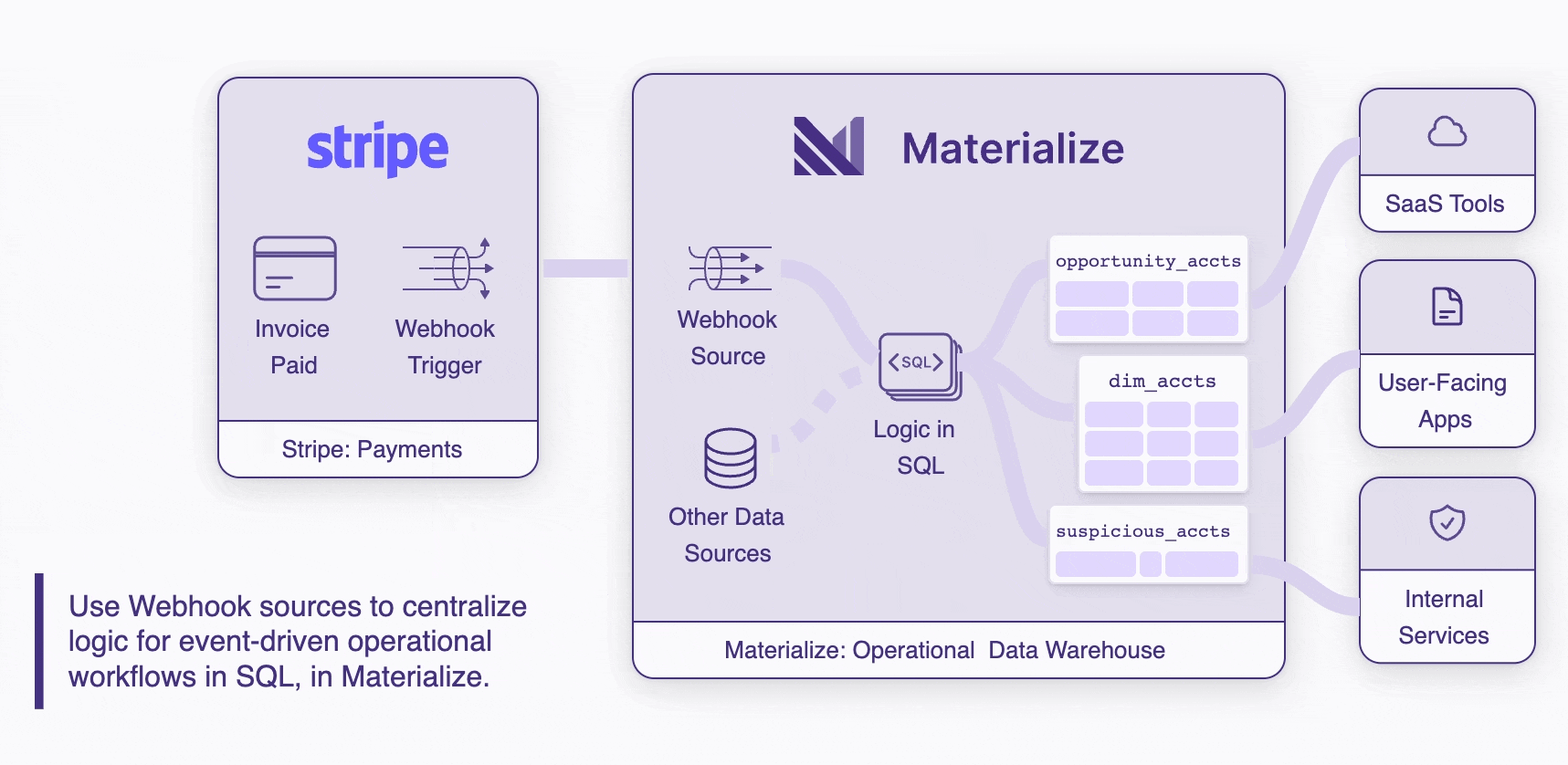
Bring together more sources of data
Just like our analytical warehouse ancestors, operational warehouses like Materialize are uniquely good at joining together disparate sources of data. Webhooks unlock a long tail of new data sources that, when joined together, create operational value that is greater than the sum of the parts.
Reduce Administrative Overhead
Webhooks by their nature are plug-and-play. Once configured it is the responsibility of the source and destination platforms to handle the complexity of things like network partitions. This places upfront responsibility on you the administrator to vet how each side of the integration handles things like errors, logging, delivery guarantees. But, once configured, there are no services to maintain, all the work is handled by the source and destination.
Setting up Webhooks in Materialize
Materialize has a concept called Sources. Sources are objects that describe external targets you want Materialize to read data from, once created they continuously ingest data from the the target. In this case, that external target is a webhook. To create a source we only need a little bit of SQL.
CREATE SOURCE my_webhook IN CLUSTER my_cluster FROM WEBHOOK
BODY FORMAT JSONSuccessfully running this command creates our source, and returns the URL we can push data to!
NOTICE: URL to POST data is 'https://‹HOST›/api/webhook/materialize/public/my_webhook'If you ever need to this URL again, it is available in the mz_webhook_sources internal table.
Now we have a source exposed to the public internet that our external applications can send data to. But wait, if it’s exposed to the public internet, anyone can push data to it! We need to add some validation to make sure only legitimate data makes it into our source.
HMAC
Most webhook providers have a way to validate that requests are coming from a trusted source. A common method is to use hash-based message authentication codes, also known as HMAC. You create a shared key that only you and the external application know. Then for every request, the external application hashes the body with the shared key, and puts the result in a header. When receiving a request, Materialize again hashes the body, using the shared key, and checks that it matches the value provided by the external application. If the values do not match, we know the request is not valid, and we reject it!
Let’s recreate our source so it uses HMAC validation! First, we need to drop the source we already created.
DROP SOURCE my_webhook;Second, we need to create our shared secret. Make sure this key is kept safe, because otherwise anyone could push data to your source!
CREATE SECRET webhook_secret AS 'super_secret_123';Finally, we can recreate the source. Webhook providers might validate requests a little bit differently, but let’s say our external application HMAC’s the request body with the SHA256 algorithm, and puts the result in the x-signature header, encoded as base64.
CREATE SOURCE my_webhook IN CLUSTER my_cluster FROM WEBHOOK
BODY FORMAT JSON
CHECK (
WITH (HEADERS, BODY, SECRET webhook_secret)
decode(headers->'x-signature', 'base64') = hmac(body, webhook_secret, 'sha256')
)The CHECK statement we include here matches the logic from our external application, and will validate each request it receives. If a request is not valid, then it is rejected!
For more examples of setting up webhook sources and validating requests, please see our documentation.
Parsing JSON from Webhooks
Much of the time, the data payload of webhooks is delivered as a complex, multi-level JSON object. Materialize uses the same (recently improved) SQL syntax as Postgres when it comes to working with JSON. To give you a head start, we’ve created this JSON to SQL web tool. With it, you can paste in an example of your JSON payload, and get the SQL syntax to parse it into properly typed columns in SQL.

Need some ideas to get started?
We’ve already published documentation guides for connecting Rudderstack to Materialize and Segment to Materialize. These two popular customer data platforms are great places to get started because they make it easy to collect and route behavioral analytics data like web pageviews and mobile app analytics, all in real-time.
Materialize customers are already using the Segment/Rudderstack to Materialize connection to power valuable operational workloads like opportunity identification, dynamic pricing, and more.
If you’d like to see how Materialize works for your use case, you can get immediate access to our platform with a free 14-day trial here, or you can get in touch with our field engineering team to get a demo and talk through your use case here.
