What Chipotle Can Teach Us About Real-time Data Products
When I talk to engineering and data leaders about the challenge of data-intensive applications and pipelines, I always come back to the same question: how do you get access to transformed data that is both fast and fresh?
A UI that responds instantaneously to user input. Streamlined microservice development by pushing and consuming relevant state throughout your system as soon as writes are processed. Agents that can take action on operational databases and see the results immediately, unlocking multi-agent workflows or human-in-the-loop teaming.
Most people assume you can't. You either have an operational database with fresh data that blows up when presented with complex queries, or a data warehouse with fast queries that's fundamentally stale. For the adventurous, you could try building a streaming pipeline, but the complexity and talent bottlenecks bring agility to a halt as each new feature takes longer than the last and changes become increasingly fraught.
But there's another option. It involves a fundamental rethinking of the data supply chain. To get there, let's first look at an example from a physical supply chain.
What Chipotle Figured Out
Chipotle popularized a solution to a problem that looked impossible: fast food that's actually fresh, with enough flexibility to offer a customizable menu.
Next time you're in a Chipotle, look past the counter. There are people working in the kitchen, and it doesn't matter if you're ordering something, it doesn't matter what you order: they are back there continuously taking raw ingredients and doing some amount of work to transform them into semi-finished goods. They're taking the raw chicken and turning it into grilled chicken. They're taking the avocados and turning them into guacamole.
Chipotle figured out that if they wait for you to order before starting most of the work, they can't prepare your food fast enough for you to wait in line, so they'd have to give you a number and call you later. That reactive approach doesn't get them the experience they want. So they do a ton of work proactively to have transformed ingredients that are essentially building blocks for your order. Then, when you order, they quickly assemble your burrito. The reactive part, the part that happens when you actually show up, happens in moments, because most of the work is already done.
What really makes this work isn't just the proactive preparation. It's the thinking behind which semi-finished goods to have ready.
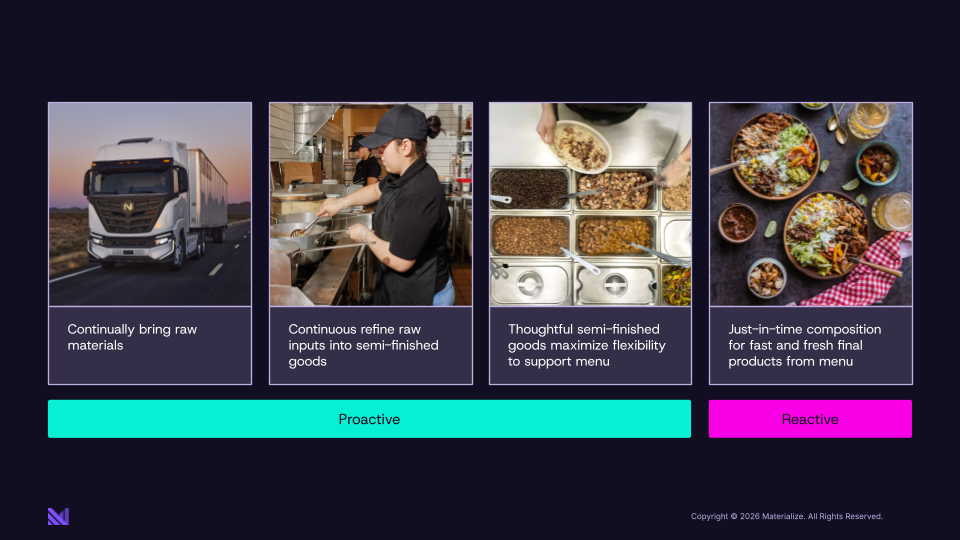
When you look behind the glass at Chipotle, there is real thought behind the number of bins and what goes in them. What is the minimum set of bins to give you the most valuable menu options? You're going to see the set that gives customers the most flexibility and the ones most likely to be used if made proactively: the combinations that unlock the most of the menu.
And here's what I love about this: the menu isn't a fixed, finite list of outcomes. It's a starting point. The bins are what enable infinite combinations based on what you actually want. You can have your burrito bowl with extra guac, no sour cream, light rice. Chipotle didn't pre-make that exact bowl. They pre-made the ingredients that let them assemble any bowl quickly. The proactive work is on the ingredients, not the final answer.
So there's this massive proactive component, and then a small reactive component when you walk in the door. That combination is what lets them deliver fresh and fast at the same time.
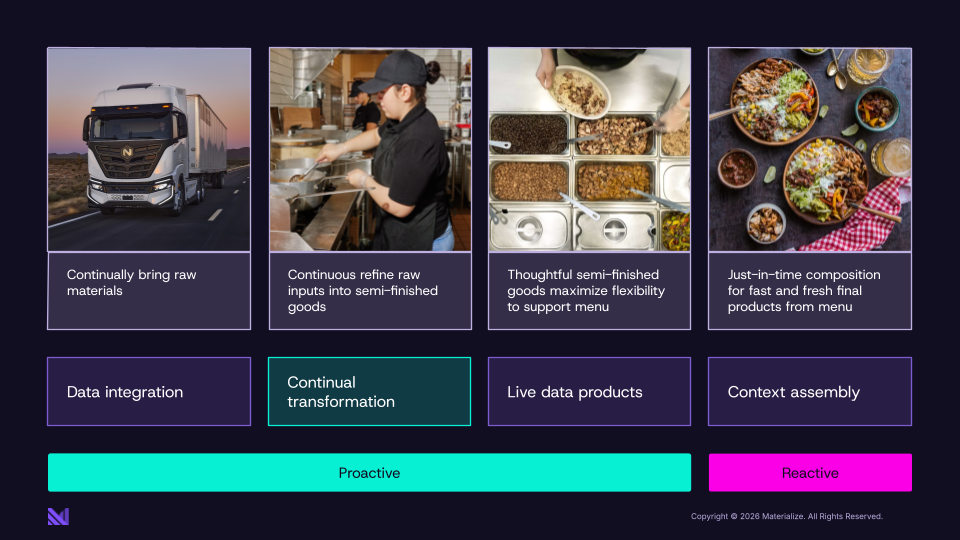
Applying these ideas to your data infrastructure
What if we took the same idea and applied it to your data infrastructure? How do you create flexible data APIs or provide fresh, fast context for AI agents?
The Chipotle model says: stop waiting for agents and clients to request data before you start doing the work. But don't process that work in batches and serve clients hours-stale data either. Instead, continuously transform your raw operational data into real-time data products. These stay up to date as the underlying data changes, and clients can quickly join them using SQL and apply last-mile transformations. As your sources are writing, you're not waiting for a client to make a request: you are continually transforming that data into the building blocks agents need. When an agent or client comes in, you can quickly assemble those building blocks into context.
info
What is a real-time data product?
Unlike a one-off query, a data product is designed to be discoverable, reusable, and composable across teams and services. When engineering teams build data products for apps and agents, they also need to be accessible at agent and service scale (serving thousands of concurrent reads with millisecond-level latency) and fresh enough to reflect changes in the source system within seconds.
Just like Chipotle: the assembly at the end is fast because you've been doing the hard work all along. And just like the bins, you're not pre-computing answers to specific requests or questions. You're pre-computing the ingredients that let you assemble any answer quickly. Because you are doing most of the work on write, you can efficiently handle reads even at machine scale, an approach that works for online applications where requests come in at machine speed rather than just business intelligence for humans.
How do you know what data products to create? Start by working backwards from the menu you want to offer. What is your microservice API? What skills do you want your agents to have? Rather than answering those directly, try to break out the work you could possibly do ahead of time. The standard approach is to think in terms of the nouns of your business or domain: customers, orders, portfolios, promotions. In the enterprise, producing these entities correctly may require substantial business logic spanning multiple tables or even databases, but the entities themselves are the same regardless of any specific request. When you move from the physical to the data world, you also get efficiencies through data product composition. An order can be made up of inventory items, and you can reuse the work of keeping dynamic prices up to date proactively when maintaining a shopping cart.
As you build more of these real-time data products, it gets easier to build different APIs. And depending on the quality of your model, it gets easier for your agents to discover which data products are available and combine them on the fly in response to a prompt or goal.
As you add more data products, more bins in the Chipotle example, you get a compounding effect. Each new one expands what your agents or microservices can do.
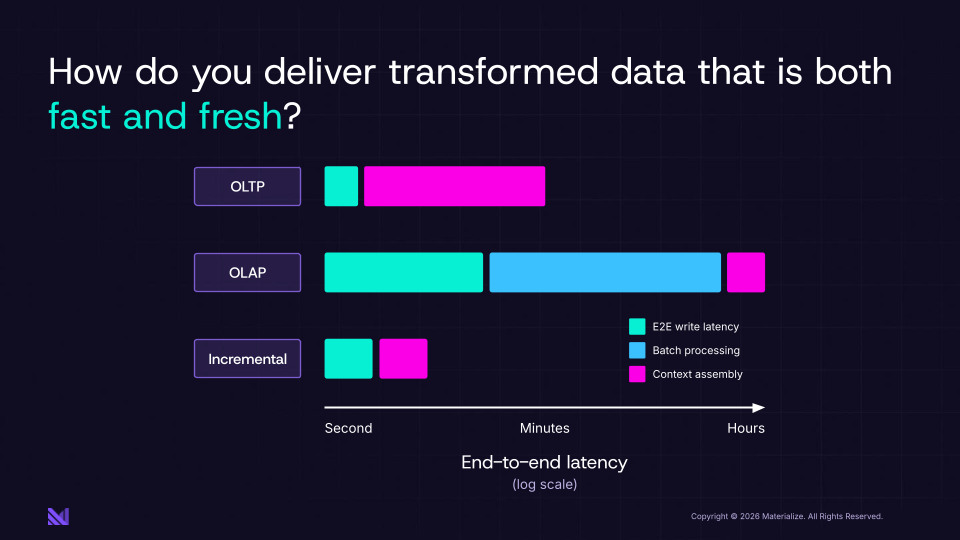
Fresh and Fast at the Same Time
When you build this way, you can transform raw operational data into real-time data products in about a second rather than minutes or hours. From there, you can reactively query the results in milliseconds. You get the best of both worlds: the freshness of an operational database with the read latency of a data warehouse.
To be clear: not every problem needs a Chipotle kitchen. If you're building a BI-style agent that answers questions about last quarter's revenue, batch processing is probably fine. The data doesn't need to be fresh, the agent isn't taking actions and observing results, and a frozen dinner works perfectly well for that job: pull it out of the warehouse, microwave it, done.
The ideas in this post unlock the feedback loops that make agents and microservices genuinely powerful and extremely fast to build and modify. An agent can take an action, see the results of that action, and decide what to do next, all within a tight enough loop to support real human-agent collaboration. Without it, you're giving agents a worldview that's drifting further from reality every second, and they're making decisions accordingly.
At Materialize, we've taken these ideas and built them into a platform for taking siloed operational data and transforming it into real-time data products, just using SQL. If you'd like to learn more, check out our website.
