Why You're Doing Context Engineering Wrong

AI systems continually gain ever more sophisticated capabilities at a dizzying pace. There’s one serious problem, though: our current data architectures and workflows simply are not built to provide the current, curated data that AI agents and applications require to turn tokens into value.
In 2025, context engineering arose as the way to systematically optimize the data we feed to AI agents and applications, particularly in production systems. Context engineering itself is a practice, designing architecture to feed an LLM the right information at the right time. It's about building the data pipelines that connect a disconnected model to external data and information to ground its responses in facts, not just training data, and overall has been the right first step. In 2026, though, it is clear that context engineering itself is only part of the solution.
Relevance and live data are crucial for context engineering because, while context is a critical resource for agents, it’s also finite. In the same way human working memory has only so much capacity, LLMs have an “attention budget” that they draw on when parsing large volumes of context. Every new token introduced depletes this budget by some amount, increasing the need to carefully curate the tokens available to the LLM.
Tokens are the crucial currency of agentic systems, but they're only valuable when the context window contains the right information at the right moment. Giving AI applications the right information at the right time requires the right data architecture.
How we are doing context engineering wrong
The LLM context window, where an agent's given task (or subtask) is ultimately performed, can only hold so much information at once. This fundamental constraint shapes what agents and agentic systems are currently capable of, but the inputs we’re feeding into agents as context are often fragmented across different databases, multiple APIs, and various microservices. Attempting to orchestrate and control this data flow leads to some common context engineering mistakes that might seem like the right thing to do, but lead to inferior agent performance and, ultimately, inferior results.
Triggering critical failure modes in the context window
The first and most common context engineering breakdown is assuming that shoving every bit of data into ever-larger context windows is a simple way to solve this problem – after all, current LLM models offer huge query capacity. At time of writing, 1 million tokens is the common starting point for most standard LLMs while others, like Gemini 3 Pro and Llama, offer a massive 10 million token capacity.
Every token placed in the context window directly influences what the model can "see" and how it responds, so giving more information intuitively feels like the right thing to do. But feeding an LLM the maximum amount of input data it can consider at one time is not only expensive — the larger the context, the longer the processing, while pricing scales steeply as token usage increases — but also leads to critical agent failure modes that emerge as context grows:
- Context confusion: Irrelevant or old data crowds the context, distracting the model and causing it to work with the wrong information
- Context poisoning: Incorrect or hallucinated information enters the context, which the agent reuses and produces errors that continue and compound.
- Context distraction: Too much information overwhelms the agent, which then over-relies on repeating past known data rather than reasoning fresh from current data
Context clash: Contradictory information is fed into agent context, such as stale data from one database plus current state from another database that reflects upstream changes. The agent must attempt to reconcile the conflicting assumptions, which is often when it will hallucinate incorrect information, or the process aborts outright.
Context engineering does not create effective and reliable AI systems. Better data architecture does.
Losing to agent latency
Operational data lives in silos (your CRM, transaction databases, inventory systems, customer service logs). Stitching that together is solvable with engineering effort, but many context engineering attempts overlook the nested constraint: the latency budget.
The data latency budget is the time that a user must wait for an agent to gather context, think, and respond, and it matters immensely. A payment approval isn't just a technical transaction but a moment where a customer is waiting at checkout. In the same way, a chat agent isn't just processing a query but participating in a dialogue where a slow response signals disregard for the user’s time. In both cases, the AI might eventually produce a great answer, but "eventually" destroys the value.
This is the real-time window you have before a user interaction with your AI system fails not technically, but experientially or operationally, as the user loses patience and clicks away. But engineering ideal agent context with a reasonable latency budget is complex and labor intensive in regular data architectures, so many teams are forced to take shortcuts. They approximate data, accept stale inputs, or sacrifice correctness for latency, creating sub-optimal context that leads to marginally worse agentic decision-making. This compounds over time, as agents recycle and re-ingest flawed information, ultimately degrading agent performance or causing processes to fail outright.
Learn more about agentic latency budgets and live-layer data patterns in our Low-Latency Context Engineering for Production AI post.
Mis-managing metadata
Vectors are the language of AI, and they are also the source of another common context engineering mishap: missing, stale, or irrelevant metadata.Working with vector data is conceptually simple. You’re taking unstructured data, embedding it, and writing to your database along with any initial attributes you assign to it for filtering and reranking based on business logic — ie, metadata. Unfortunately, too many engineers simply stop here because, well, that’s as far as traditional data architectures typically go.
But agentic systems wobble when (1) the model isn’t given the full information it needs to do its job or (2) the right data is there, but in an inaccessible format (even the most advanced LLMs can’t conquer the “garbage in, garbage out” problem). AI applications need complete and relevant vector metadata both for all attributes assigned to the vector, and the vector embedding itself. The problem is that metadata changes constantly in business systems, and live data pipelines that can keep vector embeddings and attributes fresh for accurate, up-to-the-minute AI results are extremely difficult to build using traditional data architectures.
Learn more about live vector data pipelines in our Your Vector Search is (Probably) Broken: Here’s Why blog post.
The right way to do context engineering
These common context engineering failures all point to the same conclusion: the limiting factor for traditional data architectures in AI systems is not LLM models but the ability to transform operational data into fresh, relevant context. This is a core design challenge for any AI application or agentic system, and you can't fix it by writing better RAG or cranking up context window size. You have to build your data system around the model.
Effective context engineering for agents needs some form of embedding-based, pre-inference retrieval to present relevant context that an agent can reason over, delivered in a “just in time” approach. Rather than pre-processing all relevant data up front, AI agents built with the “just in time” approach maintain lightweight identifiers (file paths, stored queries, web links, etc.) and use these references to dynamically load relevant, live data into the agent’s context at runtime.
The solution? A new wave of AI infrastructure centered on live data products — always-fresh, constantly updated data, pre-computed context, intelligent caching — instead of the models themselves.
info
Human-in-the-loop?
This new breed of context that’s engineered via live data infrastructure works very much like human cognition, actually. People don’t usually memorize entire stores of information, because that’s not effective or efficient (or, honestly, even realistically possible). Instead, we use external organization and indexing tools like database tables, file systems, and even bookmarks to find and retrieve formatted, relevant information when we need it.
Solving critical failure modes with live-data context engineering
Agentic systems are prone to failure modes like context confusion, context poisoning, etc., because pre-AI data infrastructures basically force agents and AI apps to piece together raw data at inference time no matter how carefully context window inputs are engineered.
Without this architecture, agents must query low-level database tables, figure out joins, and apply business logic themselves, consuming tokens as it goes. A customer service agent, for example, might pull from the orders table, join it with customer records, check support history, calculate loyalty status, and apply business rules to understand who it's talking to. Much of this context, though, is likely redundant or irrelevant to the actual task, making this the point in the agent’s workflow where failure modes creep in.
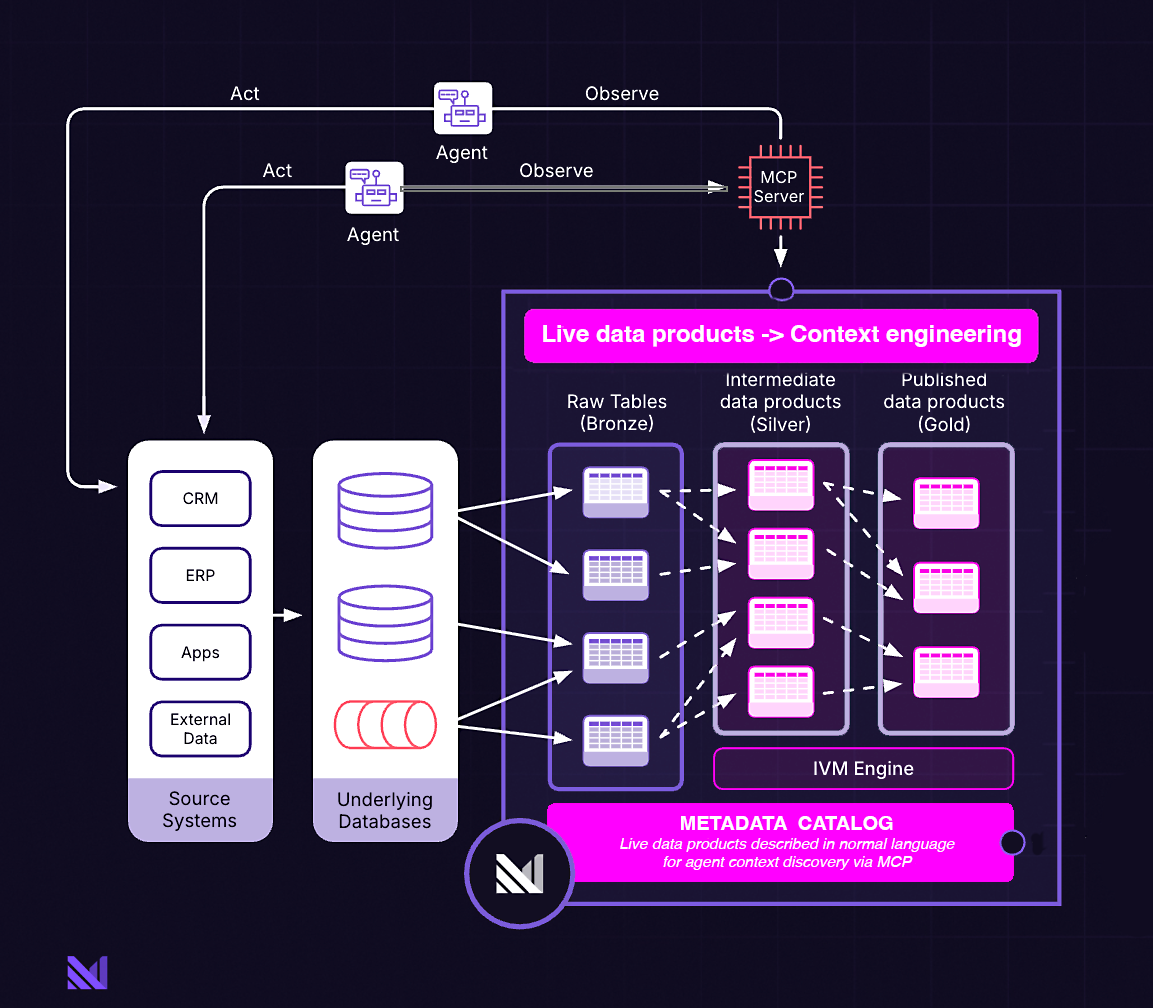
A live data layer architecture fundamentally changes context engineering by curating the right data before it ever reaches the context window. Context is pre-computed and continuously maintained in the exact form (often as business objects, but any type is possible) that a specific agent needs for fulfilling its task.
With a live data layer, agents interact with coherent, pre-assembled entities like "Customer" or "CustomerOrders" that already encode relationships and business rules. The heavy transformation work happens continuously in the background, not at inference time, and the context window contains only what the agent actually needs: a curated, semantically rich representation of the business domain rather than a sprawl of raw data.
Context confusion disappears because irrelevant data never enters the window. Context poisoning is averted because the data layer tracks lineage and knows exactly which upstream changes affect which outputs. Context distraction diminishes because agents receive focused, purpose-built data products instead of everything-but-the-kitchen-sink dumps. And context clash resolves because the live data layer maintains a single, continuously updated source of truth rather than stitching together conflicting snapshots from multiple systems.
The result: smaller context windows that deliver better outcomes, because every token carries meaningful, current, accurate information.
Context engineering for solving agent latency
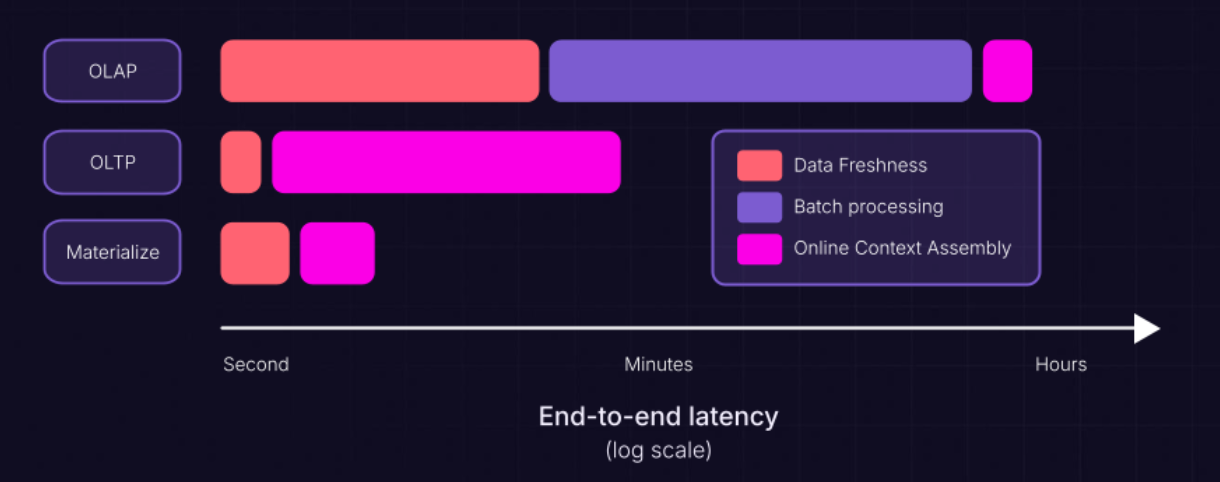
Context engineering's core challenge is to deliver rich, accurate context to agents within the tightest possible latency budget. Traditional architectures, though, offer only the tradeoff between querying multiple operational databases for fresh data (slow) or pointing agents at a pre-integrated lakehouse (fast but minutes or hours stale). Neither option supports effective context engineering because you're either exceeding your latency budget or feeding agents stale information.
Using a live data layer breaks this tradeoff by shifting the expensive work of integrating, joining, and transforming raw operational data from query time, instead performing continuous background processing. Engineers define views that represent canonical business objects like customers, orders, and portfolios. As updates occur in source systems, the live data layer incrementally maintains these views, performing only the minimal computation required to keep complex context representations current.
These views function as live data products, and these products function as contextual building blocks that can be composed into more complex structures. A manufacturing line rolls up into a plant, which rolls up into a supply chain. A customer record incorporates lifetime value, support history, and account status. Since the data layer handles transformation continuously, you can build these hierarchies efficiently and maintain them incrementally (and without burning compute tokens whenever an agent needs the data).
This data architecture functionally becomes a semantic representation of your business, in the form of a digital twin that reflects real-world changes within seconds. For production AI, these digital twins must live in operational space to be fresh enough to reflect current reality yet fast enough to serve live requests at agent scale. This would be impossible with traditional infrastructure, where you'd either wait for batch ETL cycles or execute expensive joins on every request.
The result is context engineering done right, delivering richer, fresher information within operational time constraints and without the approximations and shortcuts that compound into degraded agent performance over time.
Context engineering for optimal metadata management
Vector data is the language used by almost all agentic AI systems and applications: vector embeddings capture data’s semantic meaning, but vector attributes are where metadata lives – the business logic that enables hybrid search, filtering, and reranking. Effective context engineering depends on both being fresh and accurate. The problem is that traditional architectures make this extraordinarily difficult to achieve.
When upstream data changes, traditional pipelines don't know exactly which vectors are affected or what part needs updating. Is it just the filterable attributes, or is the embedding itself stale because contextual metadata was baked into it? Teams take the safe but expensive route: re-embed everything in batches to ensure freshness. Infrastructure costs balloon, and between batch runs, agents work with stale data that produces irrelevant search results and failed responses.
A live data layer solves this by tracking data lineage and knowing precisely which upstream changes affect which vectors. This enables surgical updates: refresh only attributes when metadata changes (fast and cheap), or re-embed only the specific vectors whose source content actually changed (measured and efficient). No more re-embedding your entire product catalog daily "just to be safe" when only fifty products actually changed.
The result is context engineering that delivers live vector data that is both fresh and correct. Attributes reflect changes from milliseconds ago. Complex joins and business logic are computed accurately. Agents perform hybrid search and reranking with efficiency (and vastly fewer tokens) because the metadata they filter on represents current reality.
Materialize: Live data architecture for AI context engineering
Context failure modes, agent latency bottlenecks, and stale or missing metadata are very different problems with the same cause: traditional data architectures weren't built for AI. They force teams to choose between freshness and speed, between accuracy and cost, between rich context and operational constraints. Practicing effective context engineering to give agents the right information at the right time requires infrastructure designed from the ground up for continuous, incremental data transformation.
Materialize provides this foundation as a live data layer for AI agents and applications. Engineers define views in standard SQL that join, aggregate, and shape raw operational data into canonical business objects. When source data changes, Materialize incrementally maintains these views, performing only the minimal computation required to keep them current. This architectural shift — from reactive, on-demand transformation to proactive, continuous maintenance — is what makes production-grade context engineering possible.
Materialize supports creating live data products using multi-way joins, complex aggregations, and even recursive queries that would normally take minutes in traditional operational databases. Agents can further query and transform views on the fly with SQL, so you don't need to define everything up front.
Materialize helps your team optimize their context engineering practices with the data data freshness of an OLTP system, the last-mile context assembly of a data warehouse, millisecond-level access to context that is sub-second fresh, and zero compromises.
Next steps
Materialize is a platform for live data architecture and agent-ready digital twins, using only SQL. It is built around a breakthrough in incremental-view maintenance, and can scale to handle your most demanding agent-scale context production workloads. Deploy Materialize as a service or self-manage in your private cloud.
We’d love to help you make your operational data ready for AI. Go to materialize.com/demo/ to book a 30-minute introductory call.