Direct PostgreSQL Replication Stream Setup | Materialize
February 16, 2022

When someone says "event driven", most of us immediately think about consuming events from a message broker, like Kafka. That might be essential for LinkedIn-scale, but it's not necessary for all event-driven architectures.
When Petros Angelatos joined the Materialize engineering team, he proposed a feature that would allow Materialize users to build event-driven architectures without requiring the complexities of message brokers. How? By consuming "events" straight from the database log!
Materialize allows users to easily define and incrementally maintain complex queries ("views") in SQL. But the source data for these views can be, well, anything. The first place that folks usually look to store their data is a database. Given our love for the Postgres dialect of SQL (Materialize is wire-compatible with Postgres at the SQL layer), the natural starting point was reading directly from the Postgres replication log.
What follows is our experience building the Direct PostgreSQL Source at Materialize, as originally documented by Petros.
Sourcing data directly from PostgreSQL
In Materialize, we always planned to connect to a (growing) handful of data sources - be it message brokers like Kafka or Kinesis, or object storage like S3. And many of our early-adopters were using Materialize with Change Data Capture data extracted from their upstream database by Debezium.
We decided that building a direct PostgreSQL source was worth the effort for a couple of reasons:
- Simplify the Operational Overhead - Many users want the benefits of low-latency event-driven architectures, without the complexities of managing a message broker. With a direct connection to Postgres, users could build powerful, event-driven applications with just two systems (PostgreSQL + Materialize), all with just SQL.
- Clean, totally ordered data in a single log. - By consuming an ordered database log directly, a lot of the challenges with building event-driven architectures can be deferred - such as dealing with out-of-order messages, and partitioned Kafka topics.
Enter the PostgreSQL logical replication protocol
How would we do this? The good news is that since version 10, PostgreSQL exposes all the info we need via a low-latency logical replication log.
The replication log feature has always given users the ability to export the stream of transactions to copy over to replicas (either used as read-replicas to offload read query paths, or as standbys for failover). However, until 9.4, PostgreSQL primarily supported only a physical replication stream. A physical stream is only really useful for a second copy of Postgres itself - since it's meant to be applied at the disk-level. It uses the internal formats of Postgres, and isn't easily parseable by a different system. But with a logical replication log, the actual INSERTs, UPDATEs and DELETEs are streamed in an easy-to-understand format.
So the first step in connecting Materialize with a PostgreSQL database is to set the replication level (specified via wal_level) from the default of replica to logical.
Interpreting logical replication messages in order
The logical replication stream is mostly a binary protocol. But the actual column values are transmitted as text. This means that when Postgres itself is writing and reading the WAL it's also serializing and deserializing values.
There are many different message types that appear in a WAL, but the ones Materialize is most interested in are:
- Insert(new_row)
- Update(old_row, new_row)
- Delete(old_row)
A single transaction consists of multiple messages and each message is annotated with:
- A transaction ID (XID)
- A Log Sequence Number (LSN)
- A Timestamp
Three notions of order. Fun! Our next task is to unravel the WAL and push changes into Materialize in the correct sequence so that we can maintain the transactional consistency guarantees that users expect with systems that handle their data.
To illustrate, let's start with a visual representation of three transactions on the WAL:
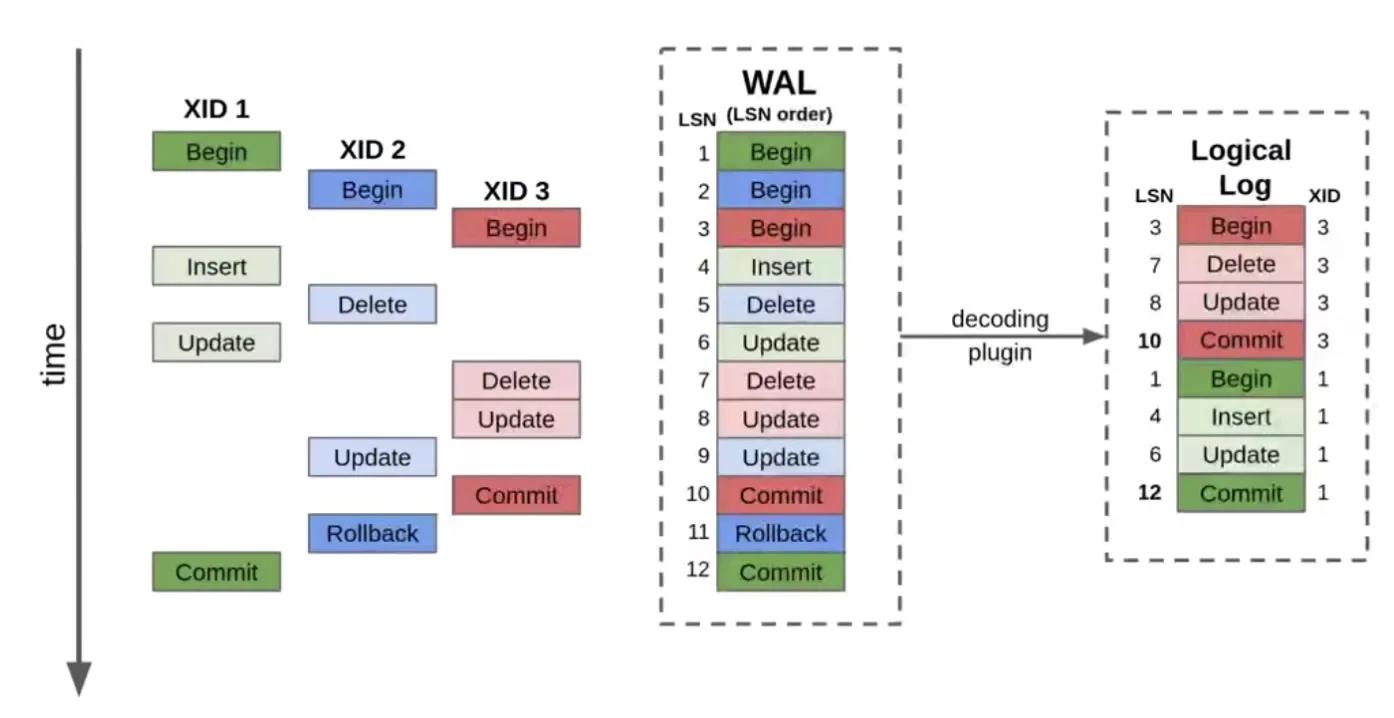
This diagram demonstrates the relationship between absolute time (progression down the vertical axis) and the different identifiers: Transaction ID (XID) and Log Sequence Number (LSN).
The first thing to note is that that transaction IDs are assigned to transactions when they begin: First Green (XID1), then Blue (XID2), then Red (XID3).
But, as we've highlighted in this example, transactions might not commit in the same order that they began: Red (XID3) commits first, then Blue has a rollback, and Green (XID1) commits last. If we try to play back these changes based on transaction id, it would be incorrect.
The second thing to note is illustrated by the Blue transaction (XID2). You might expect to only find successful transactions on the WAL, but as you can see with Blue, this is not true. In reality, as transactions progress, and before they commit, messages are written to the write-ahead log. This allows for an efficient atomic commit for transactions that involve a lot of writes - the writes are staged on disk as they come in. Any consumer of the log also has to deal with rollbacks, just as Postgres does.
Second, we cannot use the LSN ID, as LSNs refer to individual operations - which might have to be applied atomically (in the case of a multi-operation transaction), or not at all (in the case of a rollback). In our example above, the data modifications associated with LSNs 5 and 9 should not be applied at all, as XID 2 is rolled back.
Finally, timestamps refer to the wall clock time when Postgres wrote the message to disk. This isn't useful for Materialize, so we discard it.
Constructing a logical log
When using logical replication, there are a number of decoding plugins that can take the raw WAL and transform it into what we're calling a "logical log" (shown in the third column in the diagram) that replays transactions clumped together in commit order. As a result of ordering by commit, rolled back transactions are omitted.
The messages in this decoded "logical log" are what we use in Materialize. (We're using Postgres' built-in pgoutput decoder plugin.)
Ordering gotchas
For Materialize, we care about replaying transactions exactly as they happened in the upstream database, so users using both systems, get a single, consistent view of their data, with no additional work needed. How do you do that?
If you're using a CDC tool like Debezium, you get messages in Kafka topics - one topic per Postgres table. Kafka does not have a notion of ordering across topics - so if you want to atomically apply a transaction that spans updates to multiple tables, you need to keep track of transaction ids across all topics. Debezium helpfully includes a separate metadata consistency topic. But when we read directly from Postgres, our lives are a little simpler, as all transactions come in a single, ordered stream.
But even within the single stream, it's important to order transactions by the LSN of the commits, applying the entire XID at a single point in time. This requires buffering each transaction when we see a begin statement, and waiting for the corresponding commit or rollback before flushing our buffer.
Cold Starts / Resuming
LSNs are also useful for stability. If there's a hiccup in the connection, when Materialize reconnects to Postgres, it will ask to pick the stream at the last LSN it saw.
However, Postgres doesn't maintain the log's entire history forever. The log is periodically compacted away. What if you request an LSN that Postgres no longer has around? Or, what happens the first time you connect? Postgres also has the ability to send us a snapshot, along with the LSN at which that snapshot was taken, so we can seamlessly switch over without missing an intermediate message, or applying any message twice:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
Normally, a transaction in a database is an atomic change, you won't see data moving around inside your transaction.
But with the USE_SNAPSHOT modifier, we "entangle" the snapshot and replication slot (which holds a pointer to where we are in the stream of changes on the WAL) to a single point in time.
This gives us a perfect handoff: Within the transaction, we can first get efficient bulk copies of the tables, and then switch over to consuming the WAL stream at exactly the first change after the snapshot. Better yet, even if the bulk copy take a while, Postgres knows this is our intended use, so does not compact the log past that LSN until we are able to start consuming it and moving the cursor set in the replication slot forward.
Putting it all together
With the WAL sorted, we're able to connect Materialize directly to PostgreSQL as if it were a read-replica. But this is no ordinary read-replica!
Here are some of the things you can do with Materialize attached to PostgreSQL:
- Move a view from Postgres to Materialize and it will be continually kept up-to-date. - Never again run
REFRESH MATERIALIZED VIEW, it's incrementally maintained on every write. - Take a repetitive complex query from Postgres and turn it into a materialized view in Materialize. - Now, point your reads at Materialize and it's fast and scalable because it's just reading from memory.
- RethinkDB-style push queries - As a free byproduct of the dataflow architecture in Materialize, you can open up TAIL subscriptions to changes on a view. When a write in Postgres triggers a change in Materialize, subscribed clients are pushed an event documenting the change.
- PostgreSQL↔Kafka Joins - Create a view that joins your Postgres tables with event data in Kafka using standard SQL.
Materialize is source-available and free in a single-instance configuration. The cloud platform automates operation of Materialize and is free to try. Here's an example of connecting Materialize and PostgreSQL, try it yourself and give us your feedback! We have big plans to continue to improve the performance and ergonomics of the PostgreSQL source.

