Quickly Building Real-time Application Development Processes at Datalot
With Materialize, Datalot removed load from their existing SQL database. From a cost-savings perspective, using standard SQL allowed more people at Datalot to participate in the development process without having to hire additional support. From a tactical perspective, Datalot can now take the same analytics that previously were embedded in reports, and use them to notify people the moment something becomes an issue, rather than spending time looking through a report or dashboard.

Transform, Deliver, and Act
Book your demo today.At a Glance
Founded in 2009, Datalot provides digital marketing and analytics solutions for insurance policy sales at scale. Their SaaS product provides the largest marketplace of live, in-market insurance shoppers and delivers qualified customers to some of the largest insurance companies in the world – as well as to a broad, distributed network of independent providers.
Datalot: Transforming the Marketing Insurance Experience
With data at the core of its business, Datalot enables their customers to spend less time and money on marketing campaigns, and more time focusing on what they do best. Previously, the insurance industry lagged in terms of digital marketing and customer targeting, and Datalot started with a mission to improve the quality of data -- delivering qualified customers directly to the appropriate insurance company or agent.
Advancing Data Engineering at Datalot
Josh Arenberg leads data engineering at Datalot as the Director of Engineering, reporting into the Datalot CTO, and is primarily responsible for the company's data environment. Arenberg brings more than two decades of engineering expertise to Datalot, with prior experience in data science, threat and botnet detection, and big data analysis, as well as experience with streaming frameworks like Apache Spark, KSQL, and Flink. As data plays a critical role in their business model, their small data engineering team is always looking to do more with less.
Arenberg arrived at Datalot with a very broad remit -- figure out how to modernize their data infrastructure. Everything had been based around a central SQL database, which had grown and grown over the years with many read-only replicas attached and services that were pulling frequently for updates.
As Arenberg describes: "We were architecturally at the point where continuing to just add and add on top of the cluster was clearly not going to work through the next several years for the business."
Datalot needed a way to offload some of the actual load off the database -- and to build some better patterns around how analytics are built, and how that data is derived.
Digital transformation and streaming data at Datalot
Datalot (as the name suggests) is very driven by analytics -- with SQL queries at the heart of their data approach. These queries ran periodically -- critical metrics ran on shorter periods, whereas less critical metrics had a slower rate of refresh.
According to Arenberg, "In the old days, we'd probably say this company had hit the stage where you would start to build some ETL process -- doing some nightly load off of MySQL, building an analytic schema and putting it into some sort of columnar data store. That's how we used to solve these problems."
This batch-oriented approach would not suffice for the short- or long-term requirements at Datalot. While there are many solutions to alleviate load from a database, Datalot also needed a platform to enable the development of downstream applications in ways that a data warehouse is not designed to do -- and make data more timely.
"Building a real-time pipeline to Snowflake solved a very immediate problem for us -- more horsepower around analytics queries -- but somebody still had to go in and run those queries manually. While that's a very good fallback for us, I don't see us using Snowflake as a platform to build off of. Traditional data warehouses are not designed for application development."
Datalot needed to introduce a new framework for building and maintaining critical analytic reports -- both in their applications, as well as internal dashboards powered by Business Intelligence tools like Mode. They identified Apache Kafka as an important transport layer for real-time interaction with data.
Digital transformation and the introduction of streaming data
"There are lots of time critical aspects to this business," Arenberg explained. "Exposing the data in a way that wasn't just a nightly ETL process was very important."
"There's a paradigm shift -- thinking about the data in terms of a set of evolving conditions that are going to drive systems and building this machine that responds to events as they happen -- rather than data as a static thing that we ask questions of. Data is an evolving thing that drives logic."
While real-time data remains a goal for many companies, the initial shift from a traditional batch-oriented transactional data model -- which can be extremely reliant on relational joins -- is a common challenge. Companies depend on common sets of joins across several different tables to generate and monitor critical business metrics.
As Arenberg describes: "That reality is probably blocking a ton of similar companies from making use of streaming data. In order to get to the base facts of the business, we've got to join a bunch of data together, and that's not that easy to do in a typical streaming framework."
Materialize as a new approach to stream data processing
Using a combination of Apache Kafka and Debezium, an open source distributed platform for change data capture, Datalot established the foundation of a real-time data pipeline.
As Datalot began the process of re-writing their analytics dashboards for real-time, they discovered a ton of institutional knowledge baked into their existing batch-oriented dashboards, and were hoping to utilize these existing models without a major overhaul. At this point, Arenberg engaged Materialize.
Materialize easily processes complex analytics over streaming datasets -- accelerating development of internal tools, interactive dashboards, and customer-facing experiences. The platform delivers incrementally-updated materialized views in ANSI Standard SQL. Materialize is the only technology that can enable engineers to completely develop for streaming data in a powerful declarative language -- PostgreSQL -- instead of building custom microservices.
"As I was managing our tech refresh, the timing was too good to not try to marry up some of these things. Previously where a lot of the dashboards before would have relied on summary table views, now the dashboards could simply rely on Materialize."
Use cases for Materialize at Datalot
Datalot created a roadmap of use cases for Materialize -- starting with visualizations and alerts and moving towards advanced automation of processes through machine learning models. "The hope is to move from manual decision making to automated decision making," says Arenberg. "The first step is exposing and making these signals available."
Streaming frameworks hold a wealth of potential for a data-centric business like Datalot. According to Arenberg, "Streaming data can really revolutionize this business by taking analytics that are embedded in summary tables and exposing them in a way where they can become signals that can drive other services. The vision is moving from observability of data to automation of business processes."
Use Case 1: Visualizations and live alerts on streaming data
The first iteration for Datalot was to use Materialize to build real-time dashboards and analytics visualizations. With a standard SQL interface, Materialize makes it simple to connect data visualization tools and applications and keeps query results incrementally refreshed with millisecond latency as new data arrives.
With Materialize, Datalot was able to roll out new dashboards without a significant investment from engineering in building something new. "We were already building these dashboards," according to Arenberg. "Materialize meant that refresh could happen very quickly." Access to real-time data analysis can improve operations across Datalot, deepening the kinds of notification services that alert Datalot employees on their clients' performance.
Datalot is also building out real-time alert services using Materialize. Arenberg is encouraged by the potential of this simple implementation, stating "We can take the same analytics that used to be embedded in our reports, and use them to let people know as soon as something becomes an issue, rather than them needing to find any report or a dashboard."
"It is the simplest use case for this, but where we see that heading is driving further automation, with conditions that build more of an automated machine to handle a lot of these things."
Pictured below is an outline of data moving into Materialize from streaming sources and moving out to applications.
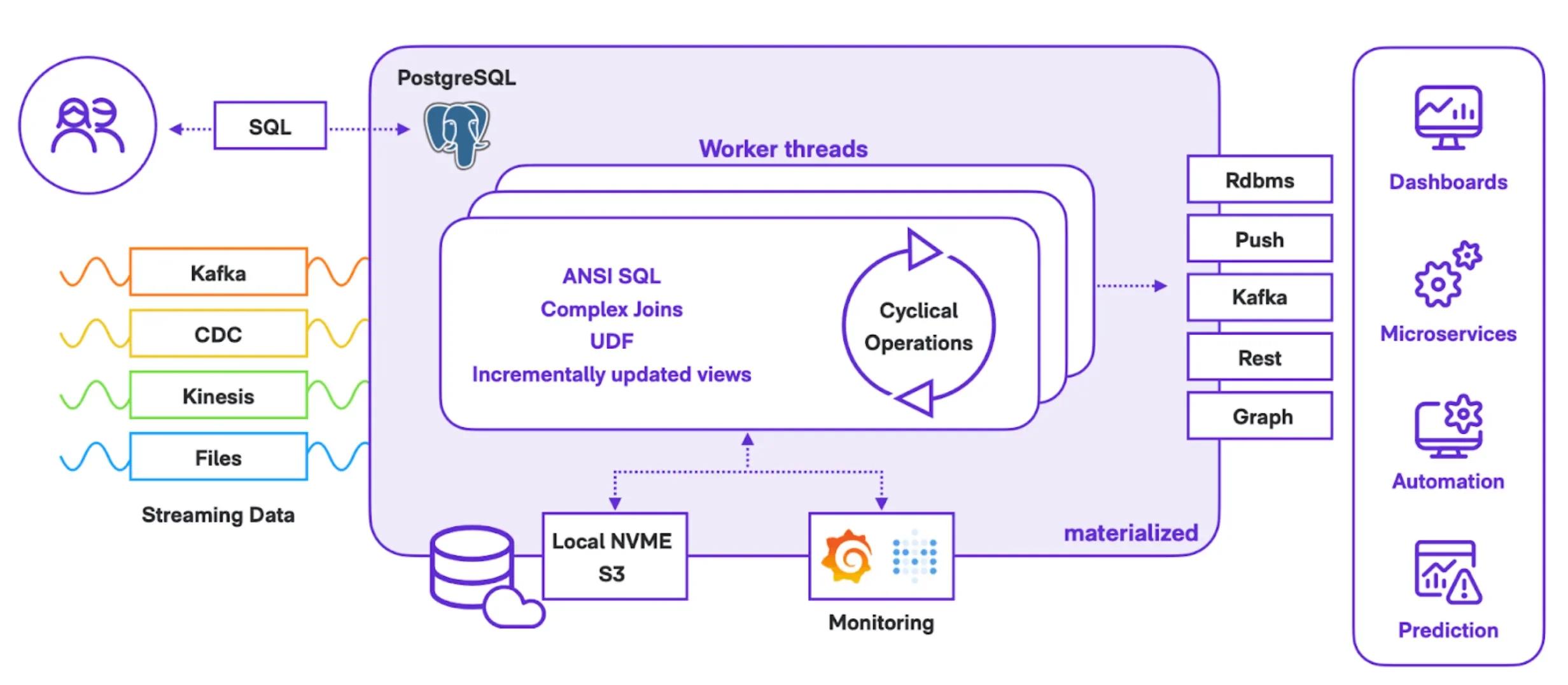
Datalot architecture for Real-Time Dashboards
Most data moving into Materialize is coming from Debezium, which they run via Strimzi on Kubernetes (AWS MSK). The team also has some airflow jobs that pick up data from various provider APIs on a regular schedule and deliver them into Kafka.
The Datalot Kafka pipeline feeds a home-grown real-time ingestion pipeline into S3 & Snowflake. Their production Kafka cluster also gets mirrored using Mirrormaker into a secondary instance, which runs on Strimzi and Kubernetes and gets snapshotted 3 times a day into EBS. All Kafka Connectors and Mirrormaker run on Strimzi as well in Kubernetes.
Downstream, Datalot uses GraphQL for populating Materialize data into their applications. They use Faust to run alert services and machine learning code, which will be fed by Materialize sinks. There are also plans to put analytics schema results into Snowflake via those sinks and an S3 Kafka connector.
Querying and Creating Views with Materialize
The initial implementation for Datalot was to replicate two of their most complex summary table views from MySqlDB and replicate them as views in Materialize. These new materialized views feed analytics dashboard pages in the Datalot app. While these queries are a bit simpler, they still require a significant amount of joining and lots of case statements. Several other queries power the alert service that tend to have time aspects to them -- for example, a query that would compare current revenue by client to the 5- day average.
According to Arenberg, Materialize offers several advantages with the kinds of queries that are complicated by time. "With Materialize, the fact that I don't have to worry about time windows -- that's huge. The fact that if I see a result from Materialize, it's a correct answer for the time that it's giving me."
This approach provides additional advantages to non-technical users as well, says Arenberg. "Conceptually, I don't need to train analysts to think about that data differently than they're used to thinking about data. They don't have to think about -- well, what if this table is 30 seconds ahead of this other table, that sort of thing. It simplifies the whole process enough where a company like ours, with a very relational data model can wrap our heads around it."
Data volumes and latencies
Datalot has raw tables with over a dozen years of data that they are pulling into their system, with an ongoing need to process terabytes of information. While specific benchmarks have not been developed, Datalot has been satisfied with the support for low-latency queries and high throughput that Materialize provides. According to Arenberg, "It has never been a problem. I think with some of these newer jobs to trigger alerts and ML, we'll have to start paying more attention to that, but my sense is that it's pretty good."
Use case 2: Creating a unified analytics schema around streaming
As real-time capabilities began to circulate around Datalot, Arenberg noticed a progression of understanding start to take hold. In addition to a series of automated services off of streaming data, another ambition for Datalot is to converge on an analytic schema for the company.
"The first thing people think is -- Okay, we can build like real-time visualizations. That's a certain utility, but then you can get alerts, which are good, and we can see where that helped.
But then -- this really changes our whole relationship to the data. Streaming data becomes something that we can build logic directly against. Rather than having systems that are going to give you views on the data, it's like you have this evolving view on the data that is making other things happen. It's this second level of capability."
This approach would open up the ability for more people within Datalot to explore data, discover insights, create valid queries and manage complex analytics for the company. Streaming services can unlock a series of improved customer experiences for Datalot -- including real-time bidding on advertisements, customized offers for customers, and optimized conversion flows.
According to Arenberg, "I would like there to be a standard set of base materialized views that a lot of our analytics are built off of. We can sink those views into a data warehouse as well, and slowly port our batch analytics on top of those baseline materialized views."
"I think it will be really a positive development for the company to have standard ways of asking common questions of the data that don't require stitching together a bunch of tables in the transaction database."
Use case 3: Introducing real-time machine learning
For further future ambitions, Arenberg sees Materialize as a key component to introduce real-time machine learning models into Datalot. The first step is to create a new record in the database that has all columns completed and all dependent variables present. From there, Materialize can signal a machine learning model, and the entire process could just be a materialized query that's running.
"We see all sorts of possibilities once the signals are there -- including embedding machine learning in this loop," says Arenberg. "Materialize seems like a very good fit for driving machine learning."
Datalot presents a compelling model for companies looking to move through their own digital transformation journey -- from the introduction of streaming data from batch-oriented models, to the creation of visualizations and alerting services, to the development of advanced analytics systems and automated processes. With Materialize, developers can create real-time applications quickly and efficiently enabling a business to move towards proactive decision making from earlier reactive mechanisms.
Working with Materialize - Doing more with less
When Arenberg joined Datalot, there was immediately the realization that it was time for a tech refresh in a few areas of the stack -- balanced with a growing understanding of what was going to be possible with the size of the team.
According to Arenberg, "We're a small organization. In my last job, I was doing streaming data, too -- but I had a team of eight people to work on it, and they all knew Java. There's not a team of eight Java developers in this company -- it's just not the scale that we're at."
"Materialize is letting us use our existing knowledge. We have a small analytics team that works all day long in SQL. We have 10 years worth of SQL logic that has been built around the business already. From a very practical perspective, I need to balance our technical ambitions and what I think is going to be good for the business with what is practical and what we're going to be able to achieve without tripling the size of the engineering staff."
Whereas if Datalot had to move their streaming analytics into more of an imperative, code-based approach, they would have been constrained by resources -- now they are unlocking ways to have parity between dashboard visualizations and signals on the back end. A much broader pool of analysts using a dashboard can go in and click any of the elements and create alerts and signals that can potentially drive other actions.
Partnering with Materialize
As a young company, Materialize has benefited immensely from a productive partnership with Datalot. As Arenberg described his rationale for working with Materialize, "My personal philosophy is to not shy away from early stage technologies, but -- especially with a team as small as ours -- you need to really pick where your bets are with early technologies."
While Materialize is at an early stage, Datalot has seen mature results from the platform. From Arenberg: "Although there's obviously a lot of new code in Materialize, the underlying correctness of Timely Dataflow is well tested. And that's held up."
"It's exceeded my expectations for where I thought the code quality would be for projects this stage. I also really liked the fact that Materialize is using Rust. I know just enough about Rust to know that if your code compiles, that gives you a lot of guarantees."
Arenberg continued to describe the ease of use of the platform and working with the Materialize team. "Very quickly, we were starting to get meaningful answers, just downloading the code. That built a lot of enthusiasm for Materialize, obviously."
"Materialize has been very predictable. For us, the bigger challenge has been moving from MySQL syntax to Postgres syntax. That's probably been more of the learning curve than moving to Materialize itself. We have run into a few cases where a function doesn't exist yet, and you guys have been great about building what we've needed. That's been amazing."
"The timing could not have been better with where we were with our architecture and app refresh cycle, and where you guys were with your initial release -- but more than that, it's been the great team that you guys have put together that really sold us."
Measuring the impact of Materialize at Datalot
Quantifying the business impact of a new system is always a challenge, but the Datalot team has been thoroughly encouraged by their initial experiences with Materialize.
From the onset, Materialize allowed Datalot to remove load from their existing SQL database. "That has the potential to be a show-stopping problem for the business," according to Arenberg. "If we got to the point where our use of the database was so complex that we'd have daily outages that would cost us money -- there's basically no limit to how big of a problem that could be for the business."
"In terms of saving developer time, one way to look at it is in comparison to some of our other choices for writing streaming data. It has allowed more people in the organization to participate in the development process, which has probably kept us from having to hire developers. There's big cost savings there."
"You could look at it also in terms of business potential of a new capability. It's necessary for us to stay ahead of our competition in the space and be able to deliver these answers faster and better. If I had to put a dollar amount, I don't know where I would start."
Explored alternatives to Materialize: Flink, Spark, and ksqlDB
Materialize is designed to solve the compromises presented by other streaming frameworks -- tradeoffs in latency, query complexity, time-to-market, or cost. In the following sections, Arenberg describes his prior experiences with other streaming frameworks and solutions.
On Flink and Spark
"Flink and Spark streaming were both technologies that I tried in my previous company. I think they were better suited to the environment of that company -- where you've got a dedicated development team just to work on streaming analytics like that."
"With Spark, I was dealing with bigger datasets there that were not sourced from a relational database that required lots and lots of joins. However, joins were the kiss of death with that platform, at least at the scale that we were doing things on it. When we would have to do a join, managing resources was a huge issue. It also very much required a team that was like application development in order to operate those technologies."
On ksqlDB
"We also did a pilot project with KSQL prior to finding Materialize. We were able to do some toy experiments, and they worked well. Since it's coming out of Confluent, it is very well integrated with the Kafka platform. If you're trying to work with one or two streams, and produce a simple filter, or even a simple table, it's a very good choice. Once we got past that stage with it, the next stage was to try to replicate some of the analytics from our summary tables with KSQL. We built one -- it took a really long time, and it was really fragile. One KSQL query could only join two tables, and you couldn't join more than two tables in a query."
"When we tried to build some of these analytics, we'd wind up with these massive flowcharts of trees of joins that would have to converge. If any one of them broke, the whole pipeline stopped working.""Every ksql query also had to sink back down to another Kafka topic. If it took 15 queries to produce an analytic, that's a lot of data duplication and a lot of sinking that same data back into these sort of intermediary Kafka topics that aren't doing me any good except to drive towards one answer. If that was going to be the choice, we would have had to really scale back our ambitions as far as what kind of answers we would be able to produce in the streaming space. I was more in the headspace of -- what can we conceivably do given the constraints of this company. When I started toying around with Materialize and it quickly became obvious that it was going to be a much better match towards the set of problems that we had."
Materialize is a streaming database for real-time analytics. Materialize simplifies how developers build with real-time data, using incremental computation to provide low latency, correct answers - all using standard SQL. With nearly a decade of technical research behind it, Materialize was launched to address the growing need for the ability to build real-time applications easily and efficiently on streaming data so that businesses can obtain actionable intelligence from streaming data.
We encourage you to try us out by signing up for Materialize or join the discussion in our Community!