Day AI: Production Context Engineering for Modern Systems of Record

Overview: Reimagining the System of Record in a Post-Agent World
Day AI is reimagining the system of record for a world where humans and AI agents work in concert. Their next-generation CRM is designed so agents can ingest, enrich, reconcile, and act on data continuously, while humans interact with a system that feels radically more responsive, more insightful, and more capable than anything possible with previous generation CRMs.
As demand for their service increased, they overcame several hurdles that traditionally cause most agent projects to fail to leave the lab. A deep architectural tension emerges: the way you need to write down every fact with full fidelity so agents have the ingredients for accurate and verifiable context is fundamentally at odds with the way you need to read that data to support agentic decision-making. Taking the messy, real-world truth of an organization and transforming it continually into trustworthy, low-latency context is the key to agentic systems that actually work.
This problem is one of the reasons RAG pipelines have evolved into the broader discipline of "context engineering". The issue isn't that the models aren't sufficient, but rather that teams can't operationalize their data. The team at Day AI ultimately pioneered a new architectural pattern to deliver the context needed to reliably support production agentic workflows. Instead of making a tradeoff between the fidelity of data capture and the freshness of their context, they took the system of record and the system for context access and split them, creating a write path optimized for recording everything, and a read path optimized for delivering structured, trustworthy context to agents and humans.
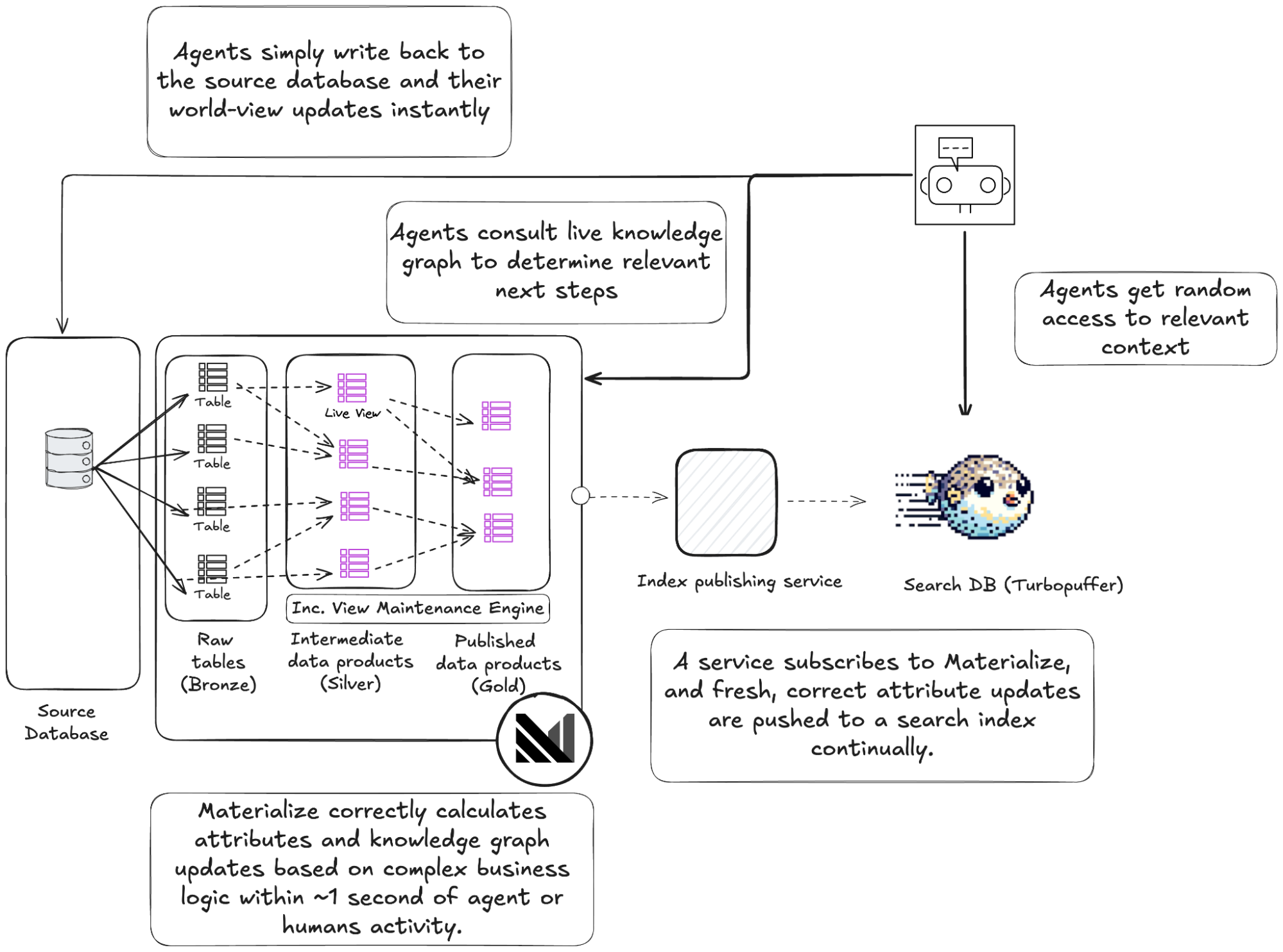
Historically this separation wasn't practical. The tooling didn't exist to maintain these representations in lockstep without building a web of custom services and stream processors. Day AI adopted Materialize as a core building block they'd been missing: a way to maintain continuously updated, query-ready context directly from the full-fidelity truth.
The Challenge: Reconciling Agent-Native Reads and Writes
In a traditional CRM, the data you capture via custom fields reflects an opinion about future questions, weighted against the work required for humans to manually enter that data. An agent, by contrast, would write down every fact it observes about a customer, every enrichment, every manual override, every revision. When reading, it needs not just raw data but distilled context for decision-making, plus an up-to-date view of the business (via a knowledge graph or ontology) to understand relationships and execute multi-step tasks.
You can prototype an agentic CRM in an afternoon. Spin up a database, put an MCP server in front of it, and let an agent take some actions. It works fine at small scale, but you’d eventually find tokens spent trying to figure out how to join and transform raw operational data, rather than moving closer to a business goal. You’d also quickly see that as the agents started asking questions at machine scale, your operational database would buckle under the load.
This is incredibly difficult to get right at scale. Day AI found that the format perfect for agent-native writes (capturing everything with full fidelity) is fundamentally at odds with the format required for agent-native reads, where context must be flattened, ranked, reconciled, access controlled, and delivered fast enough that agents can chain think and take actions without databases falling over and without users losing patience. Human edits need to sync with agent-visible context with essentially no lag. All while maintaining explainability at machine-scale concurrency.
A data warehouse isn't fresh enough. An operational database can't handle the complexity of reconciling multi-source truth or denormalizing permissions at scale. In the enterprise this challenge is compounded with siloed systems and fragmented state, forcing teams into sprawling pipelines where each component becomes another brittle point of failure.
The Solution: Creating a Live Data Layer for Agent Context with Materialize
Day AI resolved the tension between agent-native writes and agent-native reads by building an agentic variation of the Command Query Responsibility Segregation (CQRS) pattern. Their Postgres database is tuned exclusively for what agents do best: writing down everything. Every enrichment, every override, every inference, every human correction, every temporal shift in the representation of a customer is captured in full fidelity as raw truth.
But raw truth isn't what agents need at read time. To reason, they need a live semantic representation of the business: the reconciled, flattened, permission-aware "state of the world" as it exists right now. And it needs to update fast enough that when a single permission flips or new input context lands, every agent's understanding shifts within a second.
Materialize sits downstream of Postgres and incrementally transforms the full-fidelity record into clean, query-ready context. This becomes their live digital twin. While they could serve reads directly from Materialize through its MCP server, the access pattern for agents behaves more like search: broad, exploratory queries across the entire business state. So Day AI layers Turbopuffer as their search engine on top. Materialize publishes the deltas—the exact changes—to Turbopuffer as they happen, giving them perfect cache invalidation and sub-second freshness. If a single fact changes anywhere in Postgres, both Materialize's semantic layer and Turbopuffer's search index reflect that change almost instantly.
Why a search index? First, agents are exceptionally good at turning tokens into topical terms to find relevant information rather than joining across tables; full text search is great for this. Second, agents need to perform arbitrary ad-hoc combinations of filters and sorts across many fields. There's no common access pattern to optimize for; it's whatever combination of attributes the agent needs at that moment. This is the same reason legacy CRMs run massive search clusters behind their data tables. Notably, the Day AI team found that they could accomplish their use case without relying on vectors.
"Materialize is a flexible platform for expressing how you want to build live representations of what all the data you're storing actually means—in a way that matches how an agent or human would want to read it."
- Erik Munson, Founding Engineer, Day AI
The result: a simple, incremental pipeline instead of sprawling, brittle infrastructure. A small team achieving what used to require dozens of senior engineers.
Building a Graph-Like CRM: Objects and Relationships
Day AI's architecture goes beyond flattening individual records. They also model relationships between objects using a knowledge graph or ontology-style structure. A person can be linked to a deal with fields on the relationship itself, such as "this person is the economic buyer" or "this person is irrelevant to the decision."
These relationships go through the same reconciliation process as object fields. An AI job might infer that someone is the economic buyer on a deal, but a human can override that in the UI. Materialize maintains a second set of views specifically for relationships, applying ranking logic that can be even more complex than for object fields.
The result is "a CRM that feels more like a social network." You can open a person record and instantly see everything they're connected to: deals they influence, meetings they attended, organizations they belong to. This rich, AI-generated web of connections creates a fundamentally different product experience – one that was impossible when humans had to manually enter every association.
For agents, this graph structure is how they prefer to explore the world. They can find deals matching certain criteria, discover the people attached to those deals, examine a particular person's connections, and keep walking the graph until they find what they need. As Erik Munson, Founding Engineer, explained: "It's kind of like watching a coding agent work through a codebase – exploring directories, finding interesting files, following connections until it figures out what it needs."
Building Contextual Objects from Postgres Raw Truth
Day AI's write path uses an Entity-Attribute-Value (EAV) schema to capture every possible detail. As mentioned above, reading from this information-dense representation directly is infeasible. As Erik Munson, Founding Engineer, described:
"We might have a handful of different upstream data sources, plus some AI workflows, plus some humans all collaborating on decisions like what somebody's first name should be. That might amplify into eight rows in the database."
Querying this directly would require scanning multiple values, applying business rules (e.g. humans override LLMs), and checking permissions. Doing this for a single field would be expensive. Doing it for an entire customer record or the results of a search that contained multiple records based on some filter would melt an OLTP database.
Materialize solves this by keeping a flattened representation of this structure up to date as writes come in. Day AI defines this flattened reconciliation declaratively in SQL, indexes it, and then Materialize maintains it incrementally:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
Each view now becomes a new, up-to-the-second contextual building block. Critically, the moment any update happens from a human or an agent, Materialize emits a precise delta on the flattened world view, which flows directly into Turbopuffer's index and is immediately available for future agent or human queries.
Now Day AI has a live digital twin of an entire organization and permission structure, which is fresh, always consistent, always explainable, and ready to be served to agents at interactive speeds.
Why "Interactive" Matters
Erik emphasized a distinction that's easy to overlook: the difference between fast queries and truly interactive data. Even a 100-millisecond query from a well-tuned OLAP database isn't the same as interactive.
"The way I think about the difference between interactive and non-interactive is: can you actually see and work with data as it exists right now, live, and feel like it's this sort of mutable thing you're touching in the interface? Instead of looking at a report of what the data was like recently."
- Erik Munson, Founding Engineer, Day AI
In practice, this means you can click on a cell in a data table, change the value, hit enter, and see it reflected everywhere (in the UI, in search results, in what agents see) in less than a second. That's fundamentally different from generating a report, even a fast one. In traditional infrastructure, you can't click on an aggregated column in a report and change it; it's derived data.
This interactive quality is what enables Day AI's product experience. Data tables aren't just displays; they're live, editable views into the business. When a salesperson corrects a contact's title, that correction flows through Materialize, updates Turbopuffer, and is immediately available to every agent and every other user viewing that record.
"Traditionally, what you have to do is make trade-offs around flexibility or around liveness. You can do something really flexible and complicated that lets you add use cases over time, but it's going to have 10-second latency—you're going to use it as a report, a dashboard. Or you need interactive, transactional systems, and new use cases mean new services, new databases, maybe new teams, new PagerDuty rotations. Materialize lets you strike a different point in that trade-off: latency acceptable for interactive applications, with the flexibility you'd traditionally only get from non-interactive systems."
- Erik Munson, Founding Engineer, Day AI
Results
Before adopting Materialize, Erik and the Day AI engineering team were wrestling with an architecture that would have required a larger team and a forest of custom pipelines to deliver the latency and scale required to disrupt legacy CRM. Transformations that would have been trivial in a proof-of-concept in reality ballooned into operations that would have melted their Postgres instance in production. Even relatively simple tasks like finding and flattening the canonical fields for a small number of records took half a second to multiple seconds per query. UI views took seconds to load as a result. Scattered implementations of the logic for assembling data on read led to inconsistencies between subsystems and made it hard to trust data quality. Most of the team’s time was spent keeping the read path alive, and working around places where fast query response times were architecturally impossible.
After introducing Materialize, the emphasis flipped. Because they defined the majority of the transformations to go from raw data to contextual, indexed building blocks, now they primarily just needed to focus on writes. Just add a customer record, just update a permission, just overwrite an agent's decision. Even though the implications of those writes could be far reaching, it didn't matter. Materialize would do the exact minimum amount of work to keep the results up to date and send the information to Turbopuffer for interactive search. No bespoke, use-case specific transformation systems required.
This shift didn't just accelerate the system, it changed how quickly Day AI can build. New use cases can be deployed quickly based on existing building blocks, and for every new canonical business object they add, it results in an exponential increase in what their agents can do. What would historically demand dozens of engineers maintaining Redis clusters, denormalization services, bespoke caches, and fragile pipelines is now handled by a small team. And with everything incrementally maintained, Day AI now operates with subsecond latency from write to confident action.
Conclusion: Disrupting a mature market with a new architecture
Day AI's architecture shows what is required when context engineering goes from pilot to production. When agents generate the majority of your reads and writes, the core problem isn't the quality of your AI model, it's whether the system can take every raw fact, reconcile it correctly, permission it appropriately, and deliver it fast enough that both agents and humans can act confidently.
Traditional systems force a difficult tradeoff: optimize for fresh data but slow queries, or optimize for fast queries and give up freshness. Day AI broke out of that tradeoff by using Materialize to maintain a semantic representation of their business with sub-second latency that powers their core context delivery. What arrives in Postgres is reflected through the semantic layer, search index, and UI all while maintaining the ability to audit and cite agent decisions.
With modern AI architectures, time to confident action becomes a defining metric. It's not just when data lands in a database—it's when it's transformed, reconciled, permission-checked, and displayed correctly so that an agent or a human can trust it enough to take the next step.
As agents become the dominant consumers and producers of operational data, companies that master production context engineering will define the next era of enterprise software. Day AI demonstrates that with the right building blocks, even a small team can build systems that were effectively impossible just a few years ago and deliver disruptive experiences that feel like the future.