Flare: Building a Live Data Layer for Legal Services at Scale

Transform, Deliver, and Act
Book your demo today.At a Glance
Flare, a fast-growing legal services platform, needed a way to unify live operational data from microservices and Salesforce to deliver a seamless, trustworthy experience for clients and attorneys. With Materialize, they built a live data layer that powers real-time product features, scales effortlessly, and keeps every view fresh within seconds.
Challenge
Microservices architecture created operational data silos that slowed product innovation and made it difficult to build real-time, data-driven features. Flare needed a way to unify live data without sacrificing the independence or speed of their existing systems.
Results
- 10× faster query performance, powering responsive in-app experiences
- Unified live data from microservices and Salesforce within seconds
- Improved data correctness and trust, eliminating stale or inconsistent views
- Enabled new AI-driven use cases, like real-time attorney-client matching
- Compounding impact — each new feature builds faster on existing data models
Overview: Simplifying Complex Professional Services with Operational Data
Flare is a software platform that simplifies the delivery of complex professional services, addressing consumers' expectations for ease and clarity throughout the legal process. With its technology, law firms can elevate the legal experience and improve access to services. But as Flare scaled rapidly, delivering that experience meant solving a fundamental infrastructure problem: accessing fresh, unified data across siloed systems with sub-second latency.
The Challenge: Customer Demand Outgrew Architecture
As the company scaled, Flare's microservices-based architecture, which is essential for rapid development, began reaching the natural limits typical of fast-growing distributed systems, making it challenging to build the data-intensive features their product and AI roadmap demanded.
The core constraints:
- Data silos: Microservices are fundamentally about loose coupling, and to get the most value of them this also means not forming tight dependencies on underlying databases. The downside of this is you create operational data silos. As the business grew, microservices needed to coordinate data across services, which introduced latency that began impacting the user experience. Moreover, critical data sources like Salesforce weren't easily queryable.
- Complex online queries: Delivering a unified view of complex objects like a legal case to the UI meant running online queries against operational databases. As the business scaled, response times were increasingly unable to meet the sub-second expectations of modern applications.
- Correctness and trust issues: pulling data from multiple siloed services meant maintaining data consistency across domains became increasingly complex as the system grew, undermining confidence in what the platform was showing.
The Solution: Building an Operational Data Mesh with Materialize
Rather than attempting to rearchitect their microservices or build a complex data pipeline from scratch, Flare's data team – Arik (Data Engineer) and Amir Kachlon (Data Group Manager) – chose Materialize to create a unified, live data layer on top of their existing operational databases.
To do this, they ingest change data from all upstream sources into Materialize, then used dbt to create canonical business objects in SQL. Materialize kept those objects up to date within a second of updates happening at the microservice level, and the Flare team could now expose those live objects back to the application layer. This pattern, an operational data mesh, allowed Flare to maintain the loose coupling and iteration speed of microservices architecture while providing developers with the unified, live view they needed.
The Journey: Three Use Cases and Compounding Value
Use Case 1 – Case Status View
The initial use case: creating a unified view of a legal case by combining data from multiple microservices. This went live in ~6 weeks, establishing the foundation for everything that followed. Performance was 10× faster than the previous coordination approach, and queries that previously exceeded acceptable response times, now completed in milliseconds.
Use Case 2 – “My Clients” Dashboard
Building on the case status foundation, Flare created a view showing all clients for an attorney. This was faster to implement than the first use case because the data infrastructure was already in place.
Use Case 3 – Online Attorney-Client Matching
The most complex use case yet: an online feature store delivering context to a machine learning-driven system that matches incoming clients with the best-fit attorney. During the customer checkout process, based on the prospect information provided in an intake form, Materialize calculates 60+ features and delivers them to the matching model. all within a strict latency budget.
This is a textbook example of how online feature computation enables AI-driven product experiences. The latency budget is tight (roughly 100-200ms to stay within the sales conversation flow), but with Materialize's incremental view maintenance, Flare can calculate an extensive feature set without exceeding it. Without Materialize, they'd face an untenable tradeoff: either pre-compute and sync features across systems (expensive denormalization with stale data) or query PostgreSQL directly (which can't handle the computational complexity in the time required).
The matching algorithm fundamentally changed what's possible; this feature was entirely out of reach with their previous architecture.
The Compounding Returns of a Live Semantic Layer
Flare found that with Materialize, each subsequent use case became faster and cheaper to implement than the previous one. What took weeks to conceptualize and build initially now takes days, with most data already prepared by the platform.
This is the power of building a live semantic layer: once you've created canonical business objects (in Flare’s case, the case, the attorney and the client), each new feature development starts from a foundation of fresh, unified data. You're no longer coordinating across silos or struggling with stale joins; you're building on top of a trustworthy, up-to-the-second digital twin of your business that is easy to use and extend.
Architecture in Evolution: From Microservices to Data Mesh
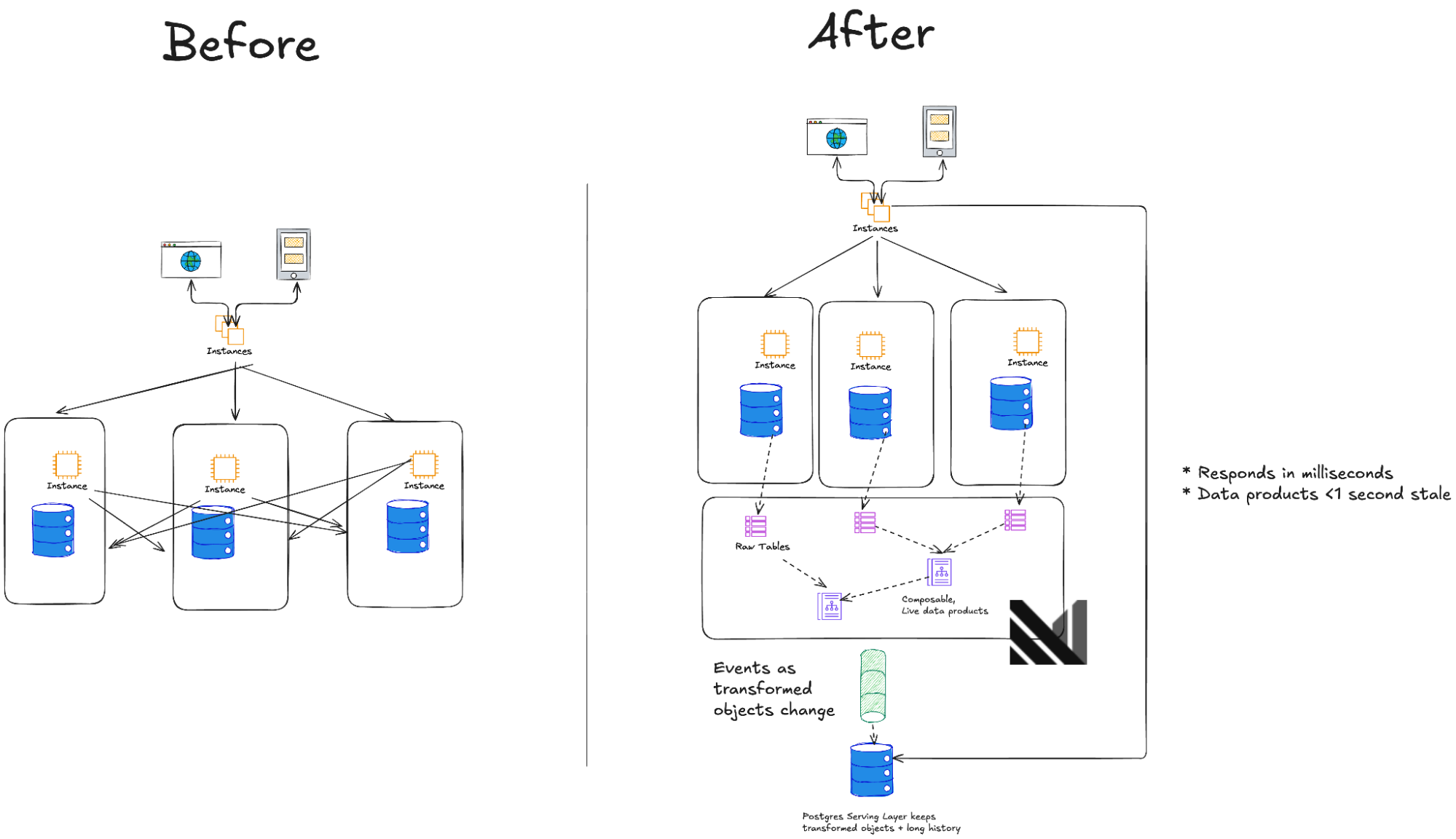
Flare's architecture demonstrates the operational data mesh pattern: microservices maintain their independence and write to their own databases, but Materialize creates and maintains governed business objects that span silos. Materialize is their store for live data, but they still need the ability to do historical queries based on long histories; to enable this they followed a kappa architecture:
- Ingest: Change data from microservice databases (MongoDB), Salesforce, and various other sources.
- Transform: Deploy dbt models in Materialize and maintain complex SQL views that join, aggregate, and enrich this data, creating live canonical business objects that are ready for fast access in milliseconds.
- Output: Fresh, semantically relevant updates are pushed from Materialize to PostgreSQL, where it can be combined with historical snapshots. This created a “kappa architecture” , where live incremental updates are unified with historical context without the complexity and cost of maintaining separate hot and cold paths.
- Serve: Applications query PostgreSQL for complete views that reflect current and historical state for UIs or AI workflows.
This pattern sidesteps the data freshness issue of data warehouses while avoiding the latency and correctness issues of direct microservice calls. The kappa architecture model means Flare gets the best of both worlds: Materialize handles the expensive computation, while PostgreSQL becomes a unified query surface for applications. A lean data team can scale impact across the entire organization because each new use case compounds on prior work.
Conclusion: Lean Team, Massive Impact
Flare's journey illustrates why a live data layer resonates with fast-growing, product-driven companies. Rather than hiring a large engineering team to build and manage bespoke pipelines, Flare used Materialize to transform fragmented microservices into a unified, operational data platform. This enabled them to build features that were previously impossible, radically improve developer velocity, and create a foundation that compounds in value as new data products are added.
In an environment where AI is increasingly driving product decisions and applications demand sub-second latencies, having live, unified data isn't a nice-to-have, it's essential. Flare is proving that with the right tools, a lean team can build infrastructure that scales far beyond traditional approaches, delivering experiences that were architecturally infeasible just months before.