
Traditional data warehouses — or ‘analytical’ data warehouses — are frequently used as a starting point for data workloads. With large quantities of historical data, and ad hoc querying, analytical data warehouses allow you to build SQL logic and test experimental use cases with ease.
However, analytical data warehouses sometimes struggle to operationalize these workloads because they process compute in batches. Real-time use cases, including fraud detection, alerts, and personalization, are not ideal for batch processing. The latency and compute demands of real-time workloads are too strenuous for analytical data warehouses.
These real-time use cases are better-suited for operational data warehouses. With streaming data, SQL support, and incremental updates, operational data warehouses can run real-time workloads in an optimal fashion.
In this guide, we’ll outline why you should migrate your real-time workloads to an operational data warehouse, along with some real examples from our customers.
What is a Data Warehouse Workload?
A workload is any computing process that requires compute resources and storage space. This broad definition captures most of the work done by a data warehouse, from a single script, to a complicated data pipeline.
Workloads can span multiple components or multiple environments. You might have part of a workload on-premise, part in the cloud, and part based on inputs and outputs from external partners.
For a closer look at workloads, let’s examine the data pipeline example we mentioned.
Data pipelines are a common type of data warehouse workload that combines multiple data sources – object storage, relational databases, hardware signals – in a multi-tier architecture. This can consist of an eventing system, a data transformation layer, a target system, and a reporting and analytics engine.
Taken together, all of these different units comprise a single workload — a data pipeline. The data pipeline workload uses CPU resources and storage to extract data and transform it into usable output.
However, different workloads require different levels of data freshness. For example, consider the data freshness requirements for:
- A historical report that relies on monthly data to project future trends
- A win/loss analysis report that leverages weekly sales data to track the performance of sales reps
- A fraud detection algorithm that needs data “immediately” to stop an illicit payment in progress
A real-time workload is outlined in the last example. Real-time workloads require data to be as fresh as possible. In practice, this means data that updates in seconds, rather than hours or even minutes.
Why Migrate Workloads to a Real-Time Data Warehouse?
Some companies build their real-time workloads on analytical data warehouses. The combination of historical data and querying flexibility allow teams to refine workloads before they operationalize them.
Initially, some companies run their real-time workloads on their analytical data warehouses. This can work, up to a point. But eventually, this approach fails.
Analytical data warehouses are designed for batch processing, not real-time data.With batch processing, work is queued and computed in batches at a single point in time. Query results after the work is completed.
As data volumes expand, processing time slows down. Data freshness declines with these increased volumes of data, putting real-time workloads like fraud detection at risk.
Operational data warehouses rectify these shortcomings. An operational data warehouse combines streaming data with SQL support, so you can continuously transform data and have access to results in real-time.
This is why it makes sense to migrate real-time workloads over to operational data warehouses. Companies can operationalize real-time workloads with streaming data, and transform the data continuously for use in business processes.
Now let’s examine some real use cases, taken from two of our own customers: Ramp and Superscript.
Ramp: Productionize SQL Logic for Real-Time Fraud Detection
Ramp is the finance automation platform designed to save businesses time and money. By integrating corporate cards with SaaS software to manage non-payroll spend, Ramp turns bothersome financial processes into painless experiences.
Ramp looked to Materialize to add new capabilities with minimal disruption to the SQL and dbt workflows that had worked so well for the company so far. The team’s first real-time workload detected when fraudsters attempt to take over customer accounts. These Account Takeovers (ATOs) can result in poor customer experience, reputational harm for Ramp, and significant monetary losses.
By prototyping on the analytics warehouse in SQL, the Ramp Data Platform team could collaborate with the Risk Ops team to build out fraud detection logic. Ramp was able to quickly prototype a rules-based fraud detection method using SQL transformations in their analytical data warehouse.
Their approach was to build a “feature table” that computed key input metrics for accounts and transactions. A service then layered more logic on the table to determine whether to flag a transaction for fraud.
Ramp needed to detect fraud in seconds, in order to stop fraudsters before they inflicted serious financial damage. However, the workload initially took 30 minutes to execute. This grew to over an hour as the company scaled.
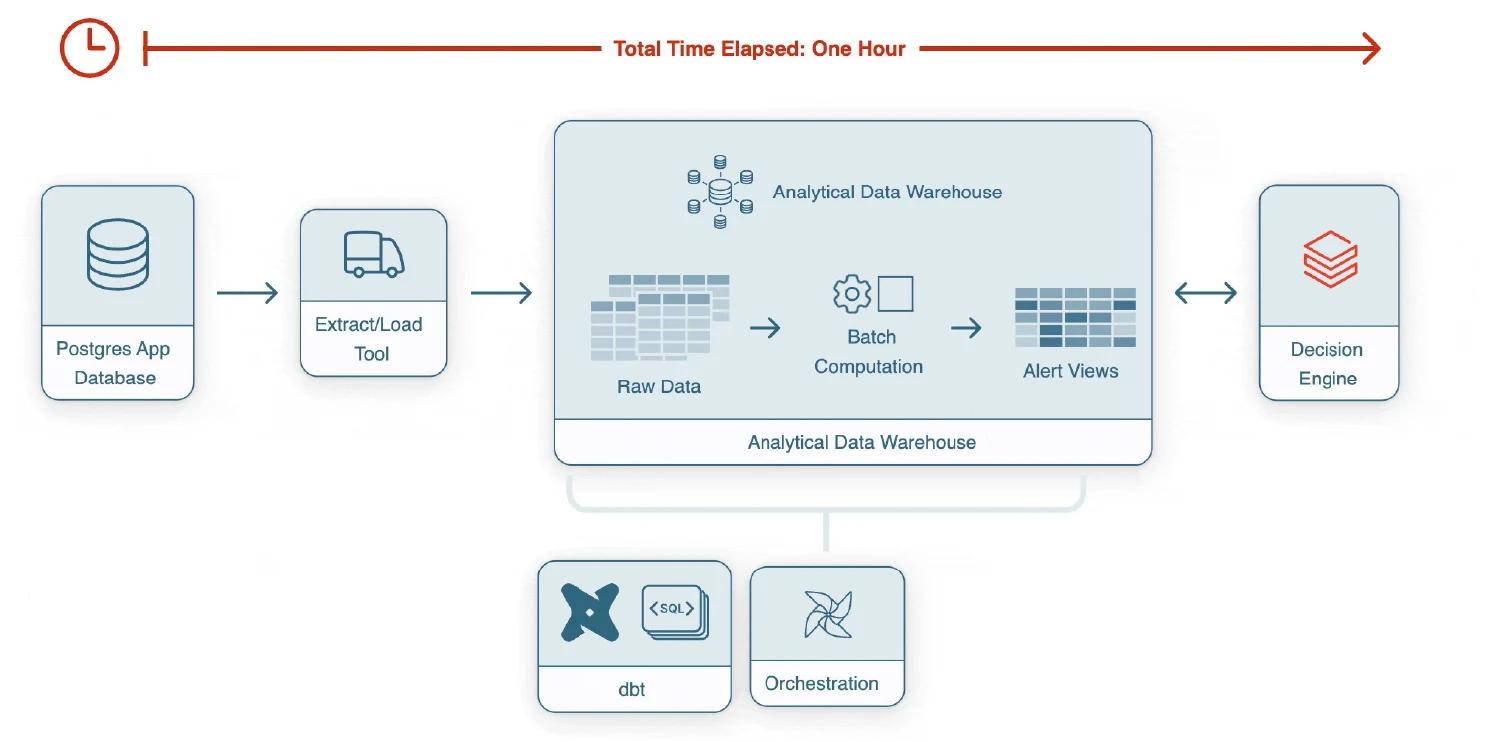
As Ramp acquired more customers, computation ran continuously in their analytics warehouse for just the ATO workload. This accrued significant compute costs. Despite this increase in compute, fraud detection still took over an hour. This gave fraudsters plenty of time to escape before alerts went out.
Ramp needed a way to take batch business logic and “ship it” as a service that runs continuously. Materialize provided this service, with an event-driven model that dramatically lowered latency. The team also considered stream processors as a solution. But stream processors would require a complete rewrite of the logic at significant cost in engineering time.
The team was able to port the rules-based fraud detection SQL logic to Materialize with minimal changes. With Materialize, the team could keep the logic consistent in SQL with the Materialize dbt adapter, and organize and version-control it in a dbt project backed by a git repo.
Materialize cut fraud detection time dramatically. With real-time data, and continuous data transformation, Materialize enabled Ramp to shorten fraud detection from over an hour to 1-3 seconds.
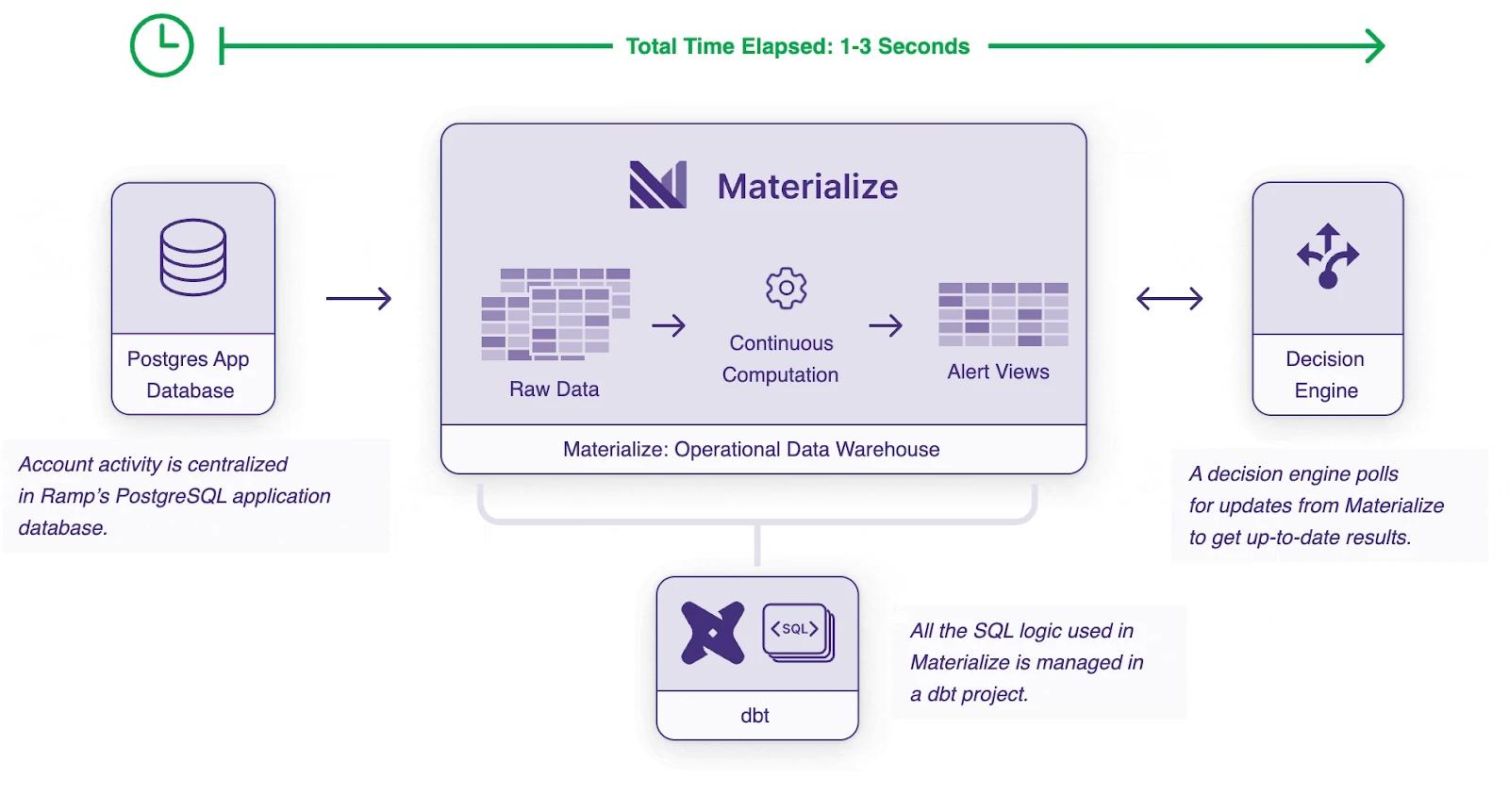
While the analytical data warehouse proved a good place for prototyping, efficient fraud detection was not possible within the constraints of batch systems, and these limitations resulted in high compute costs. Once fraud detection alerts were operationalized in Materialize, Ramp turned off the associated workflows in their analytical warehouse to eliminate the compute costs.
Ryan Delgado, Staff Engineer at Ramp, provided a summary of Materialize’s impact on Ramp :
“By moving SQL models for fraud detection from an analytics warehouse to Materialize, Ramp cut lag from hours to seconds, stopped 60% more fraud and reduced the infra costs by 10x.”
This is the ROI Ramp realized by porting real-time workloads from their analytical data warehouse to Materialize.
Superscript: Operationalize Prototyped SQL with a Streaming Data Warehouse
Since its inception, Superscript has redefined insurance for the digital age. The London-based firm specializes in bespoke, flexible policies for tech-savvy SMEs, start-ups, and scale-ups.
Superscript needed a way to take a user data model (a feature store) built on static data in a warehouse, run it on live data in production, and wire it up to multiple ML services that optimize the conversion funnel.
And Superscript needed to do this without the help of an engineering team. All the while, the team needed the same level of control, consistency, and accuracy as batch processing. The overall goal was to create a better buying process, increase conversions, and ultimately grow revenue.
Superscript had already seen promising results using proof-of-concept tests on its analytical data warehouse. The Superscript team developed SQL logic on its analytical warehouse for:
- Real-Time Scoring - Send customer behavioral attributes to an ML model that flags prospects in need of immediate outreach from customer success
- Live Operational Dashboards - Share live status of operations with internal teams to create shorter feedback loops
But the analytical data warehouse couldn’t operationalize this SQL logic. The Superscript team needed end-to-end latency in seconds, not hours, to run these real-time processes in production. With a batch processing framework, the analytical data warehouse could not achieve the necessary latency.
Additionally, Superscript also had access to valuable streams of real-time data, including: past interactions with Superscript, actions the user is taking, the pages users are visiting, and more.
Initially, they routed this live data through Segment, a real-time customer data platform. This real-time data could theoretically power the prototyped SQL logic built on the analytical data warehouse. But streaming real-time data into the analytical data warehouse wasn’t possible.
Yes, Superscript could test and prototype SQL logic in their analytical warehouse, but Segment only syncs data to the warehouse twice a day. Therefore, the analytical warehouse could not access customer data in real-time.
That’s why Superscript turned to Materialize.
Superscript set up Materialize in just one evening. Superscript used Kafka as a message buffer between Segment and Materialize. And it wasn’t long before the Superscript team started to see how Materialize could be used in production.
The initial Materialize architecture has proven reliable and scalable enough to remain unchanged since entering production:
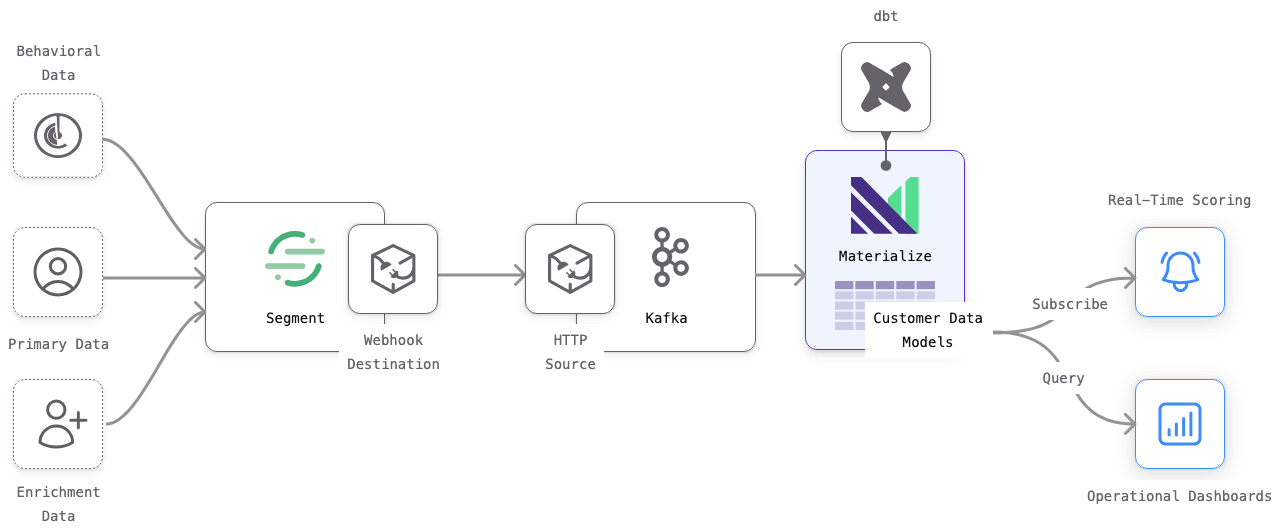
Superscript ported their SQL logic over to Materialize and streamed in real-time customer data to power their conversion optimizations. This generated significant bottom-line revenue as a result.
Tom Cooper, Head of Data at Superscript, said:
“Every week, we’re closing customers that we wouldn’t even have had the opportunity to contact before using Materialize.”
To sum up the whole story: the Superscript data team prototyped SQL pipelines in an analytical data warehouse, operationalized them on Materialize, and expanded bottom-line revenue.
Migrate to a Real-Time Data Warehouse Now
Analytical data warehouses are well-positioned for prototyping and initial modeling, but often fail to operationalize real-time use cases.
With an operational data warehouse such as Materialize, you can productionize the SQL logic you developed on your analytical data warehouse.
With streaming data and SQL support, operational data warehouses allow you to operationalize real-time use cases such as fraud detection, alerting, and personalization.
Migrate your real-time use cases over to Materialize right now. Register an account today and try Materialize for free!