Build interactive vector pipelines with SQL
Keep embeddings and attributes continuously up-to-date, with live SQL views over your operational data.
Fresh, interactive search on your operational data
Vector databases and search indexes have to stay fresh, so applications and agents can act on an accurate picture of the world. But operational data is constantly changing and spread across upstream sources, so it's hard to trace which change affects which attributes and embeddings. As a result, teams are forced to choose between stale documents, expensive batch updates that touch more than they need to, or custom pipelines that are complex and costly to maintain.
Materialize keeps your index fresh to hundreds of milliseconds, just using SQL. You connect your operational data, then write SQL views that aggregate, join, and flatten it into the shape your index expects. Materialize keeps those views up to date incrementally, doing only the minimum work required for each upstream change, and pushes deltas into Elastic, OpenSearch, Turbopuffer, or any other index. Agents can then read, act, and read again against the fresh index, or query Materialize views directly when they need the full record.
Why is it so hard to keep your search index fresh?

OLTP Databases
Your OLTP databases are siloed and assembling a flat, denormalized search document means heavy joins twice: once to create the document you put into the search index, and again on read to rehydrate the results.

Data Warehouses
Warehouses can do the heavy integration and denormalization work, but they run in periodic batches, often measured in minutes to hours, behind reality, drifting further from the truth after every batch. At that latency you can’t have an interactive agent that teams with humans, one that writes to upstream systems and sees the result of that write in its context moments later.

Do-it-yourself
Building custom pipelines using stream processors like Flink mean complexity, specialized talent, and low agility. Adding a new aggregation or join can be weeks of effort to get into production.
Keep your embeddings and attributes up to date
Attributes and embeddings can be complex to derive, often joining and transforming data from many operational systems. A single upstream change can ripple through your search documents in unpredictable ways, making it difficult to know when each one needs updating. As a result, many teams resort to batch processes, which force a choice between stale results and expensive recomputation on every write.
Materialize keeps your search index efficiently up to date in hundreds of milliseconds. As upstream data changes, it updates only the affected documents and pushes precise deltas, so you update or re-embed only what changed, even when the business rules behind a permission flip or an attribute change are complex. Embedding costs scale with what actually changed, not how often the batch runs.
Search is how agents see the world. Read how up-to-the-second attributes and embeddings power tight agentic loops in production.

Get the full picture in one query
Most teams keep search indexes thin, because including every attribute can increase costs and impact query performance. Agents and applications therefore need to join search results with operational data to get the full picture, usually meaning complex enrichment steps against multiple systems.
In Materialize, you can transform and enrich your operational data into live views, just using SQL. Complex joins, aggregations, and recursion are supported, letting you navigate and flatten data into any document shape, including from graph structures. Agents, re-rankers, and RAG pipelines can then query these views over a standard Postgres connection, so every consumer can rehydrate the full record in milliseconds.
Learn how to build vector pipelines that stay fresh at scale — without constant reembedding.

Adapt the pipeline, just using SQL
Most search pipelines force a trade-off between flexibility and liveness. Teams either build on a warehouse and accept minutes-to-hours latency, or stand up custom data pipelines for every new use case, which are expensive and complex to support.
In Materialize, sources, documents, filtering, and ranking are all expressed using SQL. You can quickly connect a new source, change a view, or add a new index, as well as safely roll out changes with blue-green deployments. Materialize also integrates with tools like dbt, so any engineer can ship new features with the SDLC you already have.
"Materialize lets you strike a different point in that trade-off: latency acceptable for interactive applications, with the flexibility you'd traditionally only get from non-interactive systems."

Three primitives, end to end
Three primitives turn ordinary SQL into a continuously fresh pipeline from your operational data to any vector or search index.
Connect Postgres, MySQL, SQL Server, Kafka, and other operational systems.
Express your document shape, filters, scoring, as SQL-defined views. Materialize maintains it continually as upstream data changes.
Subscribe to updates and sync them to your search index directly, through Kafka, or using Iceberg.
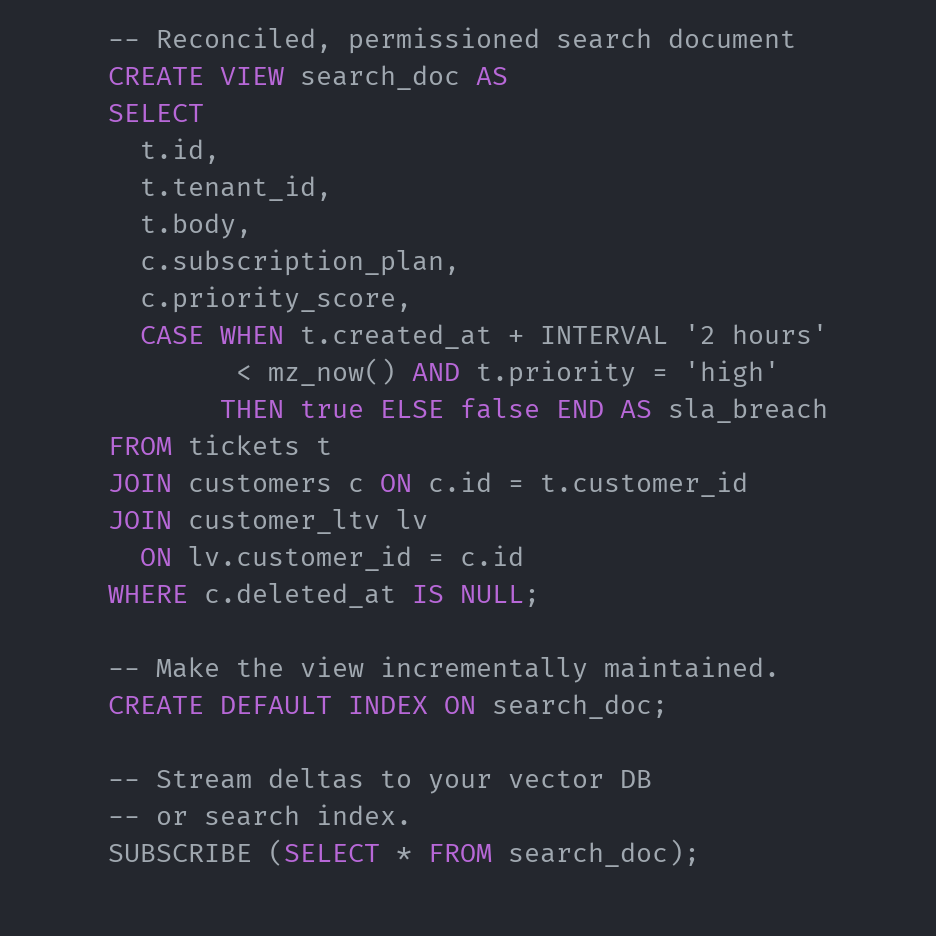
Built for interactive vector pipelines
Stream in from databases over CDC, Kafka, and webhooks. Publish to vector databases, search indexes, and downstream systems.
Joins, aggregations, windows, CTEs. Everything you'd expect from Postgres, with semantics preserved across incremental maintenance.
Index a view to make it incrementally and continuously maintained. Point lookups respond in ~10ms.
SUBSCRIBE for precise deltas as upstream data changes. No polling, no diffing, no drift.
Transactional boundaries preserved across views. One upstream change produces exactly one downstream event.
Express hierarchical, fine-grained access control and tenant scoping using standard SQL.