Build online feature stores with incrementally maintained views
Keep complex features up to date efficiently using SQL. Serve millisecond-latency lookups for fraud detection, real-time personalization, and operational ML models without taxing production databases.

Production results from technical teams
Core capabilities for production feature stores
Purpose-built for serving fresh features to ML models with strict consistency guarantees and millisecond response times.
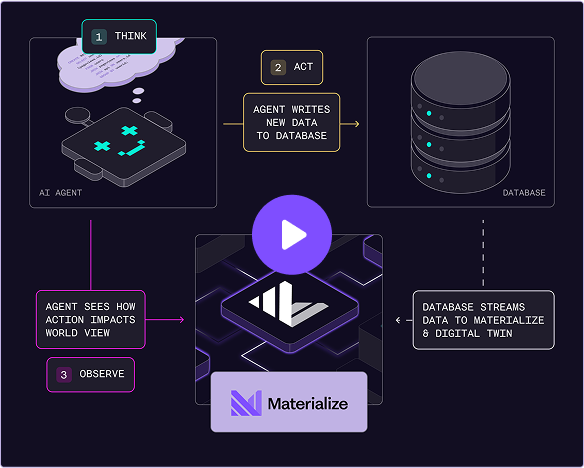
Common online feature store patterns
Track user behavior patterns like spend-in-last-5-minutes, transaction-count-by-merchant, or session-activity-scores that update continuously as events occur.
Join user profiles, transaction histories, and external data feeds with consistent timestamps for comprehensive feature vectors.
Stack materialized views to create sophisticated features. Base aggregations become building blocks for higher-order calculations.
Connect to MongoDB, PostgreSQL, MySQL, and other sources via change data capture without impacting production performance.
Query feature values using standard SQL connections. Integrate with existing application code and ML pipelines seamlessly.
Fraud detection and risk scoring
Process payment transactions in real-time to calculate risk scores within authorization windows. Maintain user spending patterns, merchant reputation scores, and geographic anomaly detection without overloading transactional databases.
Real-time personalization
Generate personalized recommendations and dynamic pricing based on current user behavior. Track browsing patterns, purchase history, and contextual signals to serve relevant content within page load times.
Design patterns for production deployments
Common architectural decisions when implementing online feature stores with strict operational requirements.
Process millions of events per second using efficient incremental computation. Updates propagate through view hierarchies without blocking concurrent reads.
Configure different freshness SLAs for different feature types. Critical features update within seconds while batch-friendly features can tolerate longer delays.
Separate compute resources for different feature workloads. Scale complex aggregations independently from simple lookups based on usage patterns.
Set up data quality checks and alerting for feature pipelines. Monitor feature drift and data freshness to maintain model performance.
Deploy your online feature store
Start with a free trial or explore technical documentation to understand implementation details.