
Summary
Streaming SQL is about taking the same declarative SQL used to write database queries, and instead running it on streams of fast-changing data.
This is useful because:
- Data is often more valuable when you can act on it quickly
- The existing tools for deriving real-time insights from streams are too complex.
The “declarative” nature of SQL plays an important role in addressing the second point because it allows the user to focus on WHAT they want, and lets the underlying engine worry about HOW it gets done.
In the real world, Streaming SQL is used to:
- Enable new internal and customer-facing insights, automation, and applications
- Increase value of business intelligence data by providing a single up-to-date source of truth for key metrics
- Simplify microservices by replacing code doing data coordination and transformation
What is streaming SQL?
Let’s start by being specific about what we mean when we say streaming and SQL.
Streaming (event streams)
Streaming refers to message brokers like Kafka, Kinesis, or Pulsar that handle data as a continuous stream of events or messages.
Event streams handle everything from transactions to user actions on sites or mobile apps, IoT sensor data, metrics from servers, even activity on traditional databases via change data capture.
SQL
In the context of streams, SQL gives users a declarative language for:
- Creating views that join, filter, and group the raw data from the stream into more useful outputs (
CREATE MATERIALIZED VIEW) - Selecting data from sources and views (
SELECT)
NOTE: The CREATE MATERIALIZED VIEW command is the core concept in streaming SQL. It comes from databases, where it’s used to precompute the VIEW ahead of time in case the data changes. In streaming, the data is changing all the time, so queries are often more useful when maintained as materialized views.
Other common SQL verbs like INSERT, UPDATE, and DELETE have roles in streaming SQL, but for this article we’ll focus on the core concepts of reading from streams, joining/filtering/transforming these streams, and making their outputs queryable or writing out to a new stream.
Differences between SQL on streams and databases
A soon as you try using SQL on streams, a few key differences become apparent:
Point-in-time vs continuous queries
Running a SQL query on a traditional database returns a static set of results from a single point in time.
Take this query:
SELECT SUM(amount) as total_amount FROM invoices;When you run it, the database engine scans all invoices that existed at the time of the query and returns the sum of their amounts.
With streaming SQL, you could run the exact query above and get a point-in-time answer. But you’re querying a stream of fast-changing data, and as soon as you’ve gotten the results back they’re probably out-dated. In many cases a query that continually updates itself (a materialized view) is much more useful in a few ways we’ll describe below.
To turn the query above into a materialized view, you’d write:
CREATE MATERIALIZED VIEW invoice_summary AS
SELECT SUM(amount) as total_amount FROM invoices;When you first create it, the SQL engine will process the entire history of invoice events it has access to up to the present, and then continue to update as new invoice events come through.
Response time vs lag
Traditional databases have the concept of query response times: you run a query, some time elapses while the engine computes the results, and you get the response.
In streams the initial response time is only a factor when you first materialize a view. But there has to be some kind of time penalty in streaming results if we get a sudden surge of input events. That penalty is time lag: by how much time is the output trailing the input?
Like response times in traditional databases, most end-users won’t need to think about time-lag in streaming systems, but knowing it exists helps to write and use streaming SQL in ways that avoid issues.
Different actions create work for the underlying engine
On the READ side, a traditional database engine idles until it receives a query, then it plans and optimizes it and gets to work providing the results. Once it responds with the results it idles again until it gets another query. The sending of queries is what creates work for the engine.
If you go back to the materialized view from above, new data from the stream creates the work for the engine. In Materialize, this approach is made possible by incremental computation: the work done to update the view is proportionate to the data coming in not the complexity of the query. We don’t need to do a full re-scan of data to update the results.
This paradigm shift makes streaming SQL best for queries that ask the same question over and over again (e.g. dashboards, reports, automation, most application code) and not ad-hoc queries.
Why is streaming SQL useful?
1. Data is often most valuable when it first appears
There are two reasons for this, one obvious and one less so:
Faster data = faster decisions --- The stock market is a clear example of this idea taken to an extreme.
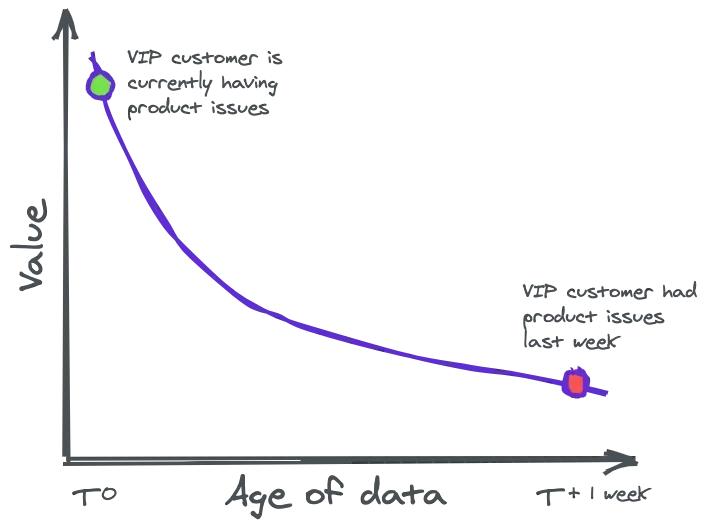 But it also applies to SaaS businesses, verticals like Marketplaces, Travel, Events that need to make fast decisions about rates and inventory, retail and logistics where faster decisions can reduce inefficiency, etc…
But it also applies to SaaS businesses, verticals like Marketplaces, Travel, Events that need to make fast decisions about rates and inventory, retail and logistics where faster decisions can reduce inefficiency, etc…Data closer to its origin has fewer opportunities to be misinterpreted --- Every step that data takes between where it’s created and where it’s used adds more potential for errors of the type where the end-user (person or machine) thinks the data represents something it does not. Time plays a role in this by forcing coordination around order of operations and alignment of work. In this case, switching to streaming data isn’t better because it’s faster, it’s better because you no longer have to think about timing.
2. SQL is a great means of deriving insights from streaming data
Here is another example of a materialized view on streaming events:
CREATE MATERIALIZED VIEW experiments AS
SELECT
experiment_views.name,
experiment_views.variant,
COUNT(DISTINCT(experiment_views.user_id)) as unique_users,
COUNT(DISTINCT(conversions.user_id)) as unique_conversions
FROM experiment_views
LEFT JOIN conversions ON
conversions.user_id = experiment_views.user_id
AND conversions.created_at > experiment_views.created_at
GROUP BY experiment_views.name, experiment_views.variant;- The SQL is not unique to streaming --- The meaning of data doesn’t change when it moves from a stream to a database, so the way we query it shouldn’t change either.
- The declarative nature of it increases productivity --- There are little or no optimization decisions for the developer to make, especially in comparison to the same task in code.
SQL has the added benefit of being a mature language built over three decades with an ecosystem of tooling and education around it. This means a much larger group of developers can work with streaming data and easily integrate it into the rest of their stack.
Example use cases for Streaming SQL
Today, anyone already working with a message broker like Kafka can start using streaming SQL without significant effort. In the future as CDC software matures, that criteria will expand to “anyone with a database.” Here are some examples of how streaming SQL is used:
Business Intelligence and Analytics
When deciding “what is the best way to empower our internal teams to make intelligent decisions from data”, Streaming SQL is one option to consider, with trade-offs that make it better for some cases than others.
In many cases, a materialized view on primary source data done in streaming SQL is a simpler data pipeline. In addition to the benefit of real-time data, businesses use this approach to side-step issues of:
- Coordination of time intervals and order of operations in batch processing
- Extended outages caused by bugs that are not fixable or testable until next batch run
- Slow-loading dashboards
- Inconsistency issues caused by caching, denormalization
For an example, see how General Mills uses Materialize to serve real-time manufacturing analytics and insights.
Microservices
Streaming SQL is used to replace code doing complex data coordination and transformation in microservices.
An event stream like Kafka is typically already a first-class citizen in microservice architectures. Engineers often find themselves building and maintaining complex applications consuming from Kafka. For example: applications that read from an event log to produce insights and measurements on API usage for a SaaS application.
Any component of a microservice that looks like a query might be replaceable with streaming SQL.
For an example, see how Superscript uses Materialize to serve real-time customer data models powering online ML predictors and operational dashboards that help optimize the insurance buying process.
Real-Time Applications
If the value of your application depends on your ability to deliver updates and data in real-time, Streaming SQL may be an alternative to building an expensive or complex multi-component stack.
For an example, see how Onward uses Materialize to serve real-time delivery status and notifications in a customer-facing UI.
New capabilities
- User-facing real-time analytics - Previously, only tech behemoths like LinkedIn and Google had the scale and engineering teams to build user-facing real-time analytics (like LinkedIn’s “Who has viewed your profile” page or Google Analytics’ Real-time dashboard.) By lowering the complexity, streaming SQL opens magical real-time user analytics features up to more companies.
- Business Automation - Once you have streaming SQL powering real-time dashboards, a natural progression is to begin making automated decisions on the same data. (For example: If your e-commerce site gets a spike in traffic from a particular source, add a promotion to the homepage.)
Conclusion
Materialize provides a streaming SQL implementation that’s unique in two important ways:
- In Materialize, you write queries in postgres-compatible SQL. We think it’s worth going through the extra effort to build this because only with this level of SQL-compatibility do you get the benefits of integrating with existing tools and removing the burden that the user understand advanced stream processing concepts.
- The query engine uses incremental computation (Differential Dataflow) to more efficiently maintain materialized views as new data comes in.
For more details on how it works, read the docs, Download the Whitepaper or join our Community Slack to discuss.
You can start using Materialize today.
References
- Inspiration for explaining the “WHY” behind streaming SQL from Julian Hyde - Streaming SQL