Stream Analytics with Redpanda & Materialize | Materialize
October 19, 2021

We at Materialize are so excited that the Vectorized team is building Redpanda because it helps open up access to powerful streaming architectures previously only available to enterprise teams. Today we'll take a look at Redpanda and how it can be used together with Materialize to build streaming analytics products that are fast to develop, scalable, and easy to maintain.
If you’re not already deep in the Java ecosystem, or if you’re already using Kafka but unhappy with the operational burden, the Redpanda + Materialize stack is worth looking into.
What is Redpanda
Redpanda is a modern streaming data platform for building mission critical applications. It has the safety and durability of a transactional database, 10x better performance than Kafka, and the ease of use of a toaster. Redpanda is wire compatible with Kafka and can act as a drop in replacement for existing development pipelines and production deployments, making it the first real Kafka alternative. Customers are able to reduce infrastructure and operational costs, while improving their KPIs due to higher throughput, lower latency, and reduced complexity.
Redpanda is free to use under BSL and the source code is available in Github. You can get started quickly with Redpanda by using Docker or installing pre-built binaries on Linux hosts. A managed cloud service is coming soon with an option to run Redpanda on your own virtual private cloud (VPC).
What is Materialize
Materialize is an operational data store that takes a feed of inputs (messages or events) and lets users join, aggregate and model the input data using materialized views written in SQL.
The magic of Materialize is that under the hood the SQL views are mapped to dataflows. As new input hits, traditional SQL engines would do a full rescan of the underlying data to update the view, but Materialize can incrementally maintain the results fast and efficiently via these dataflows.
Like Redpanda, Materialize is free to use under the BSL and provides a cloud version, currently in beta.
Materialize and Redpanda have something more fundamental in common. Both are following the same strategy for increasing developer productivity:
Take complicated technology with blazing fast performance and make it accessible by packaging it nicely behind a familiar API
The result: Your infrastructure is fast, modern, cutting edge but your APIs are stable, well-known, and already integrate with a vast ecosystem of tooling.
Hands-on with Redpanda and Materialize
For a hands-on feel for redpanda and Materialize, we'll switch our fictional e-commerce architecture from Kafka to Redpanda and create some topics and views to illustrate the stack.
Redpanda, like Kafka, plays the role of streaming message bus, allowing us to decouple the data producers (a database and an analytics service) from the consumers (Materialize). We’ll use Materialize to turn the raw data into valuable analytics aggregations for use in a business dashboard and downstream automation.
Initial Kafka architecture
Here’s what the original demo infrastructure looks like when we’re using Kafka:
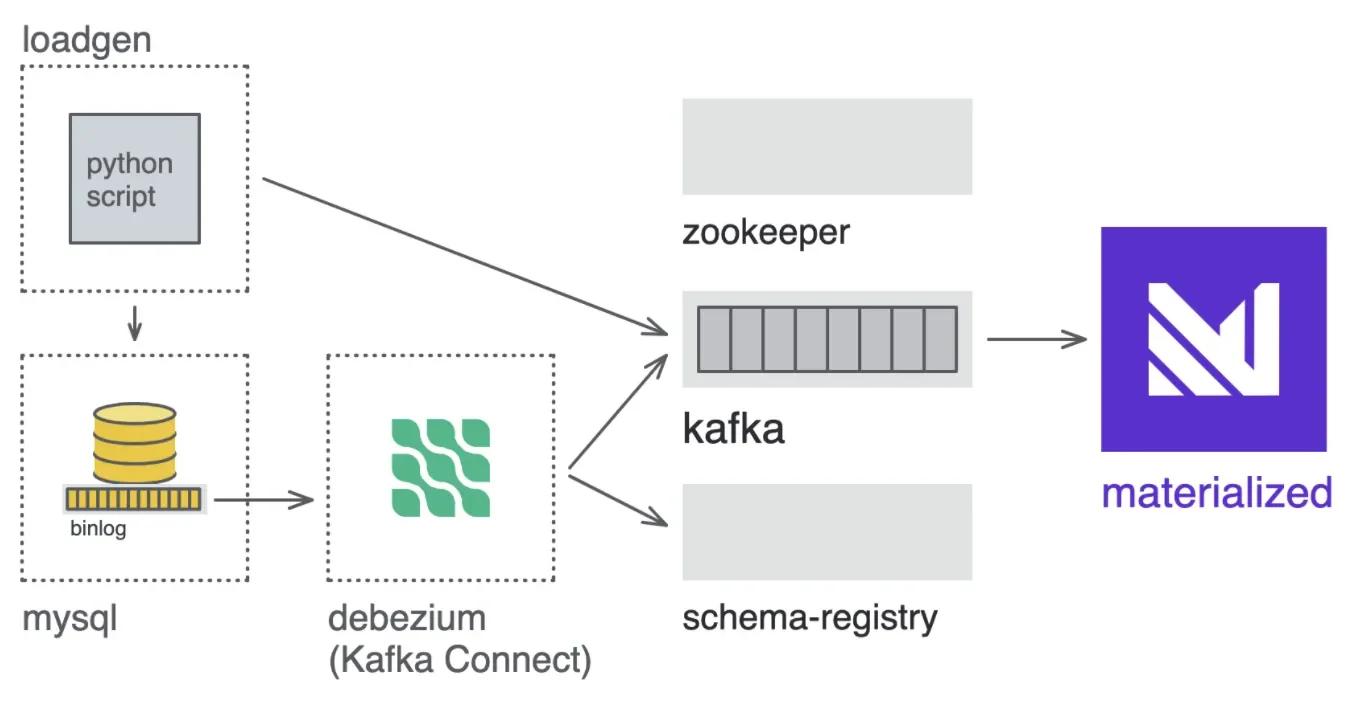
You can see the Kafka-related services defined in the docker-compose.yml file.
Switching from Kafka to Redpanda
Here's a walkthrough of using the alternate docker-compose with Redpanda swapped in. It takes over the role of Kafka, Zookeeper and Schema Registry.
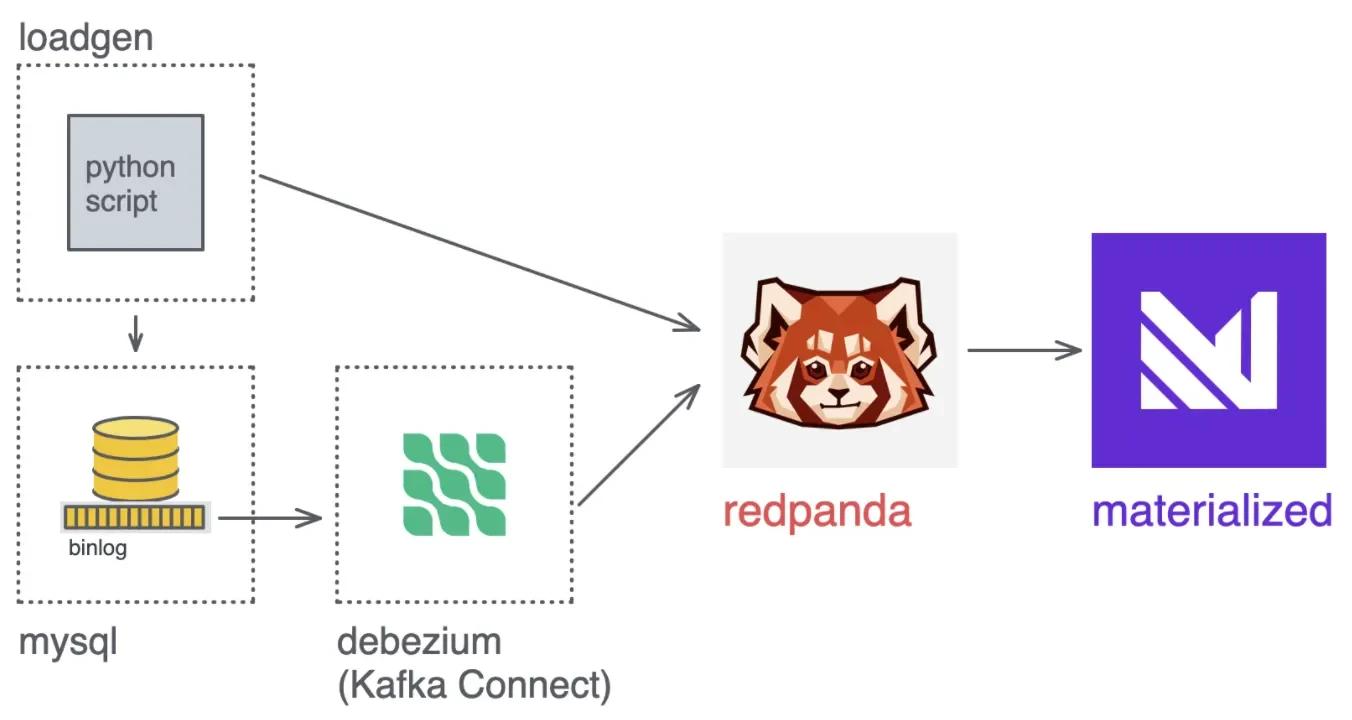
Redpanda is able to remove these dependencies by using a raft-based replication protocol to handle the work of Zookeeper, and raft-based storage to let any node act as schema registry.
We can see the details of the change in the updated docker-compose-rpm.yml file:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
enable_transactions and enable_idempotence are two important options that need to be explicitly set with redpanda to ensure all features of Materialize work.
This can also be done in a redpanda config file:
1 | |
2 | |
3 | |
Because Redpanda is API-compatible with Kafka, everything that expects to connect to Kafka or schema registry can just be pointed at Redpanda and it all just works.
Debezium to Redpanda
Debezium is a Kafka connect component, so it still needs to run separately. The debezium configuration needs to be updated to replace references to both kafka and schema-registry addresses with redpanda.
Here’s a full article on working with Debezium in Redpanda
Redpanda to Materialize
Materialize can also just be pointed at redpanda and told it’s kafka and it will consume events the same way it always does. Any technical limitations will be documented and tracked here: MZ Docs: Using Redpanda with Materialize
At a high-level there are three areas of impact when making the switch:
- Reduced operational complexity - Using Redpanda in the demo above shows how complexity is reduced by collapsing three Kafka services -- Zookeeper, the schema registry, and the broker -- into a single Redpanda service. In a production context, you also get the benefit of auto-tuning and automatic leader and partition balancing. This translates to fewer, more concise automation scripts, easier upgrades, simpler monitoring, and shorter run books.
- Performance - Built on native C++, and designed to leverage modern multicore systems, Redpanda demonstrates 10x or better performance over Kafka in benchmarks on the same hardware. While operational performance matters less in a Docker setup meant for development and testing, there are still benefits in terms of reduced startup times which can add up in integration testing pipelines that involve multiple setup/teardown cycles.
- Developer productivity - Redpanda enhances developer productivity, not just by being simpler, easier and faster to deploy. It removes Kafka’s partition count limit, which constrains data modeling options, especially in multi-tenant environments. Shadow indexing gives architects more options to design for data retention and resiliency. The Redpanda team is also working on an embedded WebAssembly (WASM) engine, which will allow new capabilities such as stateless data transforms.
Going Further: Accept HTTP inputs via pandaproxy
The same HTTP REST endpoints on every redpanda binary that are used to power schema registry can also be used to produce and consume data, this is a feature called pandaproxy.
Let’s demonstrate this using a Materialize concept called demand-driven queries. Say you need a real-time view of detailed activity for a specific user for troubleshooting, but you only ever need to look at one user at a time.
Instead of defining an expensive view that maintains the results for _every _user, JOIN your view to a “config table” where your admins can flag specific users they want to troubleshoot.
To illustrate, we’ll use curl and pandaproxy to push a single flagged user profile message from the terminal:
First, use rpk to create a new topic in redpanda called dd_flagged_profiles
1 | |
Then, push a message into the topic with a simple curl request"
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
Then we’ll create a new SOURCE in Materialize: dd_flagged_profiles
1 | |
2 | |
3 | |
4 | |
And finally, we’ll create a demand-driven Materialized view that only maintains the memory-intensive aggregations for users flagged in the 'dd_flagged_profiles' topic:
1 | |
2 | |
3 | |
4 | |
Now to troubleshoot - admins can push a new ID to the dd_flagged_profiles and the view will immediately update to only aggregate that profile's data.
The availability of a simple HTTP REST API to use as input and output to Redpanda opens up a long-tail of use-cases that would, in the Kafka world, require you to spin up additional services and write additional "glue" code to proxy data from HTTP to Kafka.
Going Further: Writing back out to Redpanda with a Sink
So far, everything we’ve shown ends with data maintained in a materialized view, where it can be queried like a database and pulled out. But that’s not using Materialize to its full potential, we can also push data out of Materialize as soon as it’s updated using a SINK.
To demonstrate, let’s create a SINK that flags users crossing $10,000 in lifetime value and outputs them to redpanda:
First, the SQL view:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
Second, here’s the CREATE SINK syntax:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
We won't be able to preview the results with rpk because it's AVRO formatted. But we can actually stream it BACK into Materialize to confirm the format!
1 | |
2 | |
3 | |
4 | |
5 | |
Other services can consume this topic and trigger emails or alerts.
Conclusion
Ready to get started? Everything is source available on GitHub and free to download and run. Try the Redpanda + Materialize (RPM?!) stack for yourself and give us your feedback in our Community, we're excited about the potential of a radically simpler and more powerful streaming platform that gives developers superpowers behind well-loved API's.
The two cloud products should integrate seamlessly as well! If you're interested in testing out an all-cloud version of Redpanda + Materialize, create a Materialize account here and get in touch with the Redpanda team here.
