The Challenges With Microservices (and how Materialize can help)

Over a decade ago, the microservices architecture emerged to solve a key challenge: allowing multiple development teams to work in parallel without deployment bottlenecks inherent in monolithic systems. By trading the speed of in-process function calls for the flexibility of loosely coupled services communicating over networks—often via REST— microservices enabled the teams to operate functionally independently, iterate quickly, and keep internals private.
This approach has proven effective, as seen in its continued popularity even 10 years later. However, several limitations have emerged over time, particularly around consistency, performance, and resilience. Many of these challenges stem from the reliance on the application tier to manage cross-service data needs, which can lead to inefficiencies and complexity. In this post, we’ll explore these three key challenges and how Materialize helps address them by pushing critical functionality to the database tier while maintaining the core independence of microservices.
1. Data Silos
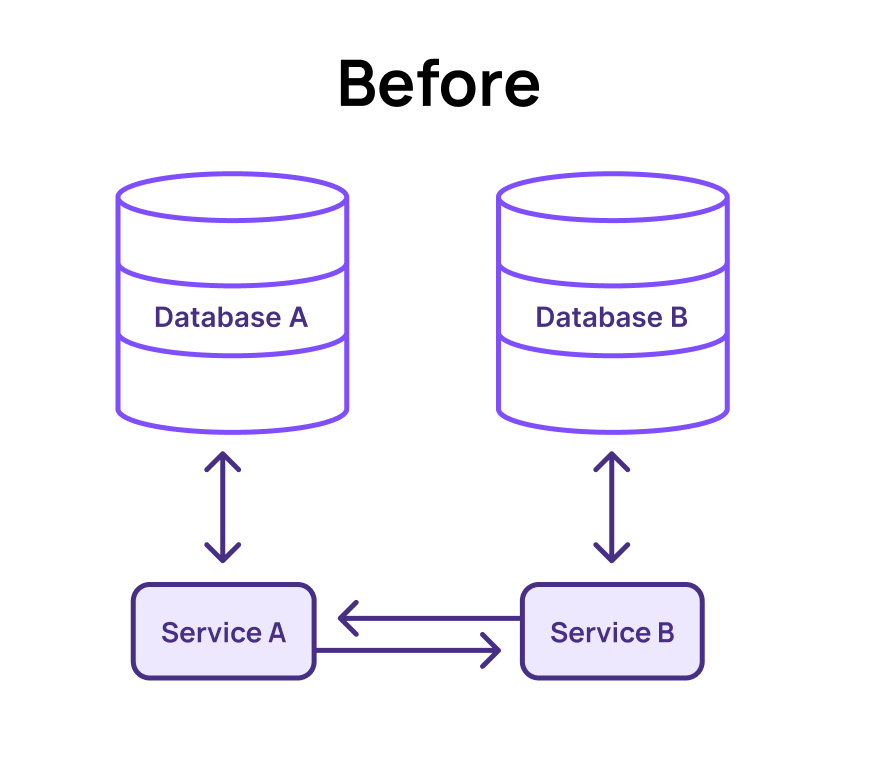
The first limitation is data silos. In a standard microservice architecture, each service manages its own transactional database, keeping the schema internal and inaccessible to other services. This separation allows teams to modify internal schemas without impacting public-facing APIs, but it also forces all data interactions to go through these APIs.
The downside, however, is that each service’s state is locked in its own database, preventing it from participating in joins or transactions with data from other services. This complicates consistent operations, such as managing accounts or inventory. For data-intensive queries and analytics, joining data across services must be done at the application layer, which is slow, complex, and costly.
Consider a delivery service in a typical e-commerce app. This service relies on data from the customer, order, and inventory services. Any aggregated reporting on deliveries would require consistent joins across all those tables. In most architectures, this isn’t feasible in the operational space. Complex ETL jobs are typically needed to extract data from each service’s database and load it into a central reporting database—usually an OLAP system—before running queries. While this optimizes for fast queries, it introduces data staleness, which does not satisfy the real-time data requirements of many operational systems.
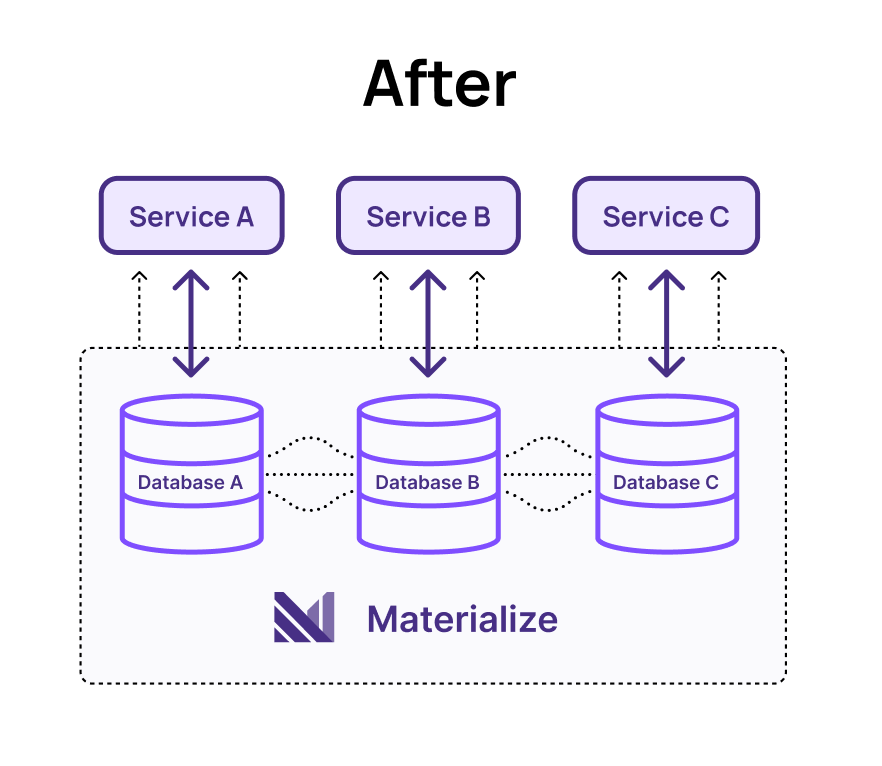
Materialize offers a solution here. Its horizontally scalable architecture allows each microservice team to maintain its own compute cluster and namespace. Access to the underlying data can be secured with role-based access controls, ensuring that internal service details remain protected. Teams can expose a Materialized View as a data product, providing a public interface for the service’s data. These views are stored in a shared storage plane, enabling efficient, strongly consistent data joins and queries across services, regardless of which Materialize cluster performs the work. The Materialized View becomes a data contract, and similar to the logic behind a REST API, the deliveries team is able to change the underlying implementation at will as long as they maintain that view in a backward-compatible manner.
This approach preserves the independence central to microservice architecture. Each team can version, deploy, and evolve its data services independently while the Materialized View remains the shared, stable interface for exposing data. This allows any team to perform consistent joins and aggregations across all services' data products without disrupting the underlying implementations.
2. Network Fan-Out
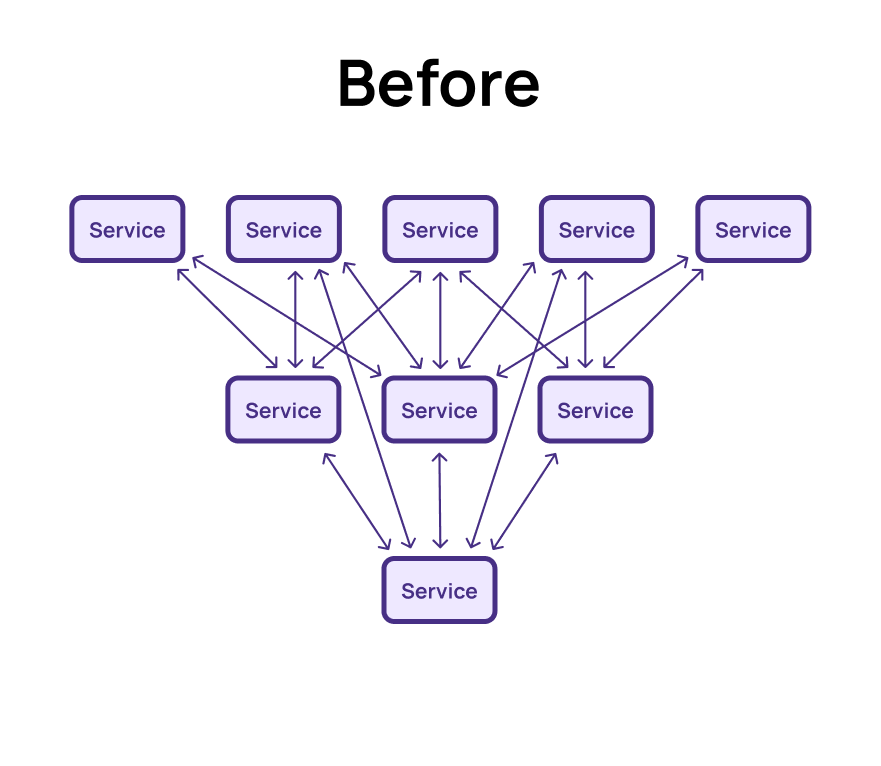
The second challenge with microservices is network fan-out, which is closely tied to the problem of data silos. Returning to our delivery service example, completing a delivery may require data from several other services, such as customer, billing, and inventory. In a microservice architecture, function calls are replaced with network calls—usually via REST APIs—decoupling the system but introducing overhead from slower serialization, deserialization, and TCP connections for each data request. In fact, on average we can estimate that a function call within a process might take 10 nanoseconds, and a REST request using JSON in the same AWS region might take 10 milliseconds - one million times slower.
When each call to our delivery service requires reaching out to multiple services, the overhead can grow exponentially as the system scales. Perhaps every call to the delivery service requires reaching out several times to the inventory service, and each call to the inventory service requires reaching out to the orders service multiple times. A 2x slowdown in response times to the orders service could result in an 8x slowdown in response times to the delivery service. In large systems processing many orders, this can result in a surge of network traffic and serialization/deserialization overhead, significantly slowing the system and increasing costs.
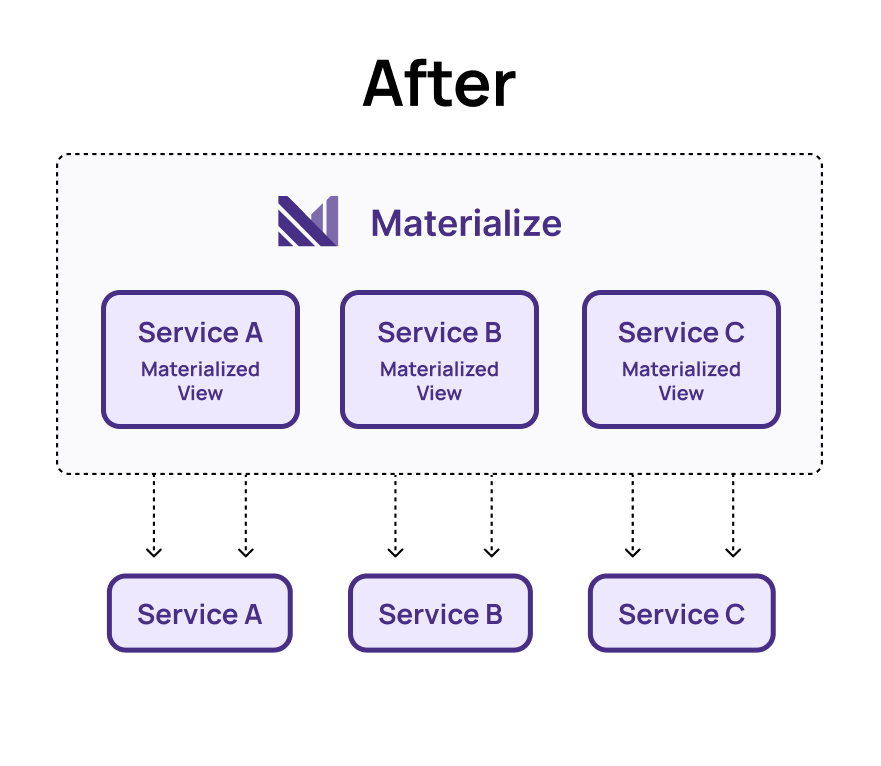
Materialize offers a different approach. Instead of requiring the delivery service to repeatedly fetch data from multiple services, Materialize can create materialized views that are incrementally maintained. These views consolidate and pre-join the necessary data, eliminating the need for repeated network calls. . Powered by a robust incremental computation, Materialize ensures that only the data that changes is pushed through the system, significantly reducing network traffic. By default, Materialize updates once per second, so during especially busy periods, things will batch rather than back up waiting for single requests over the network.
Additionally, with Materialize’s 'subscribe' feature, the delivery service can consume updates to its data view in real time as changes occur. This eliminates the need for more complex infrastructure like message queues, allowing the service to use a simple database client to receive updates.The arrival of new records in the delivery view can trigger the service to run, enabling an event-based architecture. Extending this approach across all services reduces unnecessary network calls, as the required data is already pre-aggregated in Materialize when the service needs it.
3. Reconvergence
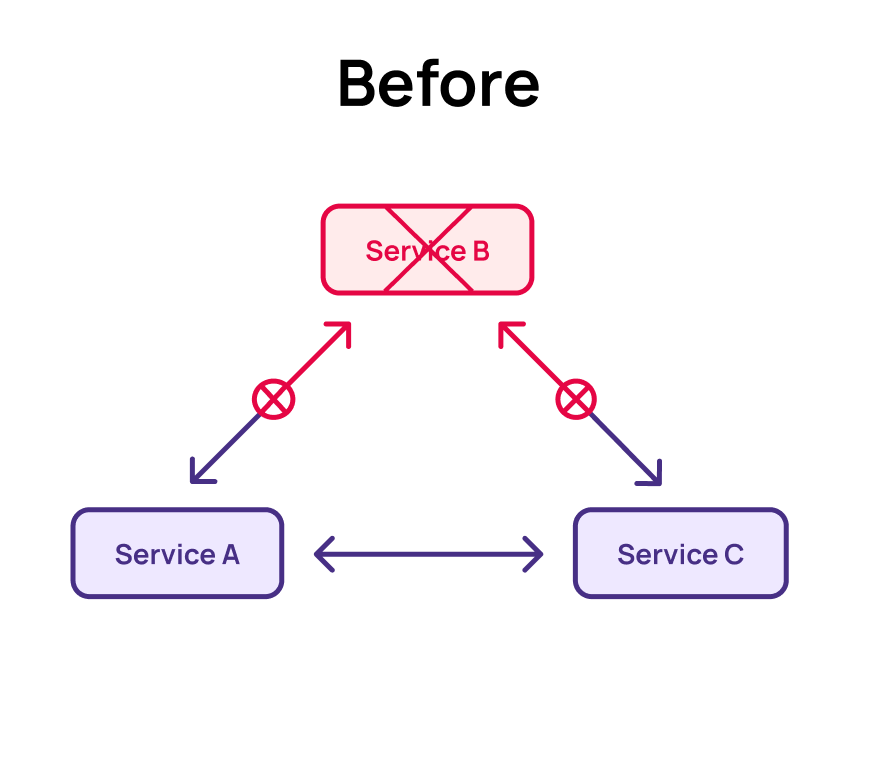
The third challenge we’ll examine is reconvergence after a service failure. Imagine our architecture experiences an outage in the customer service, causing the delivery service requests to hang. This leads to a backlog of delivery requests that are incomplete or in an unknown state. Even after the customer service is restored, it may be unclear which records require reprocessing.
In a microservice architecture, when one service goes down, it’s often unpredictable how other services will degrade and reconverge. Coordinating the recovery process can be complex. For instance, during the downtime, multiple address change requests or order cancellations might be received. Ensuring that all services are aware of which orders are in a failed state and reconverge on the correct state is a difficult challenge.
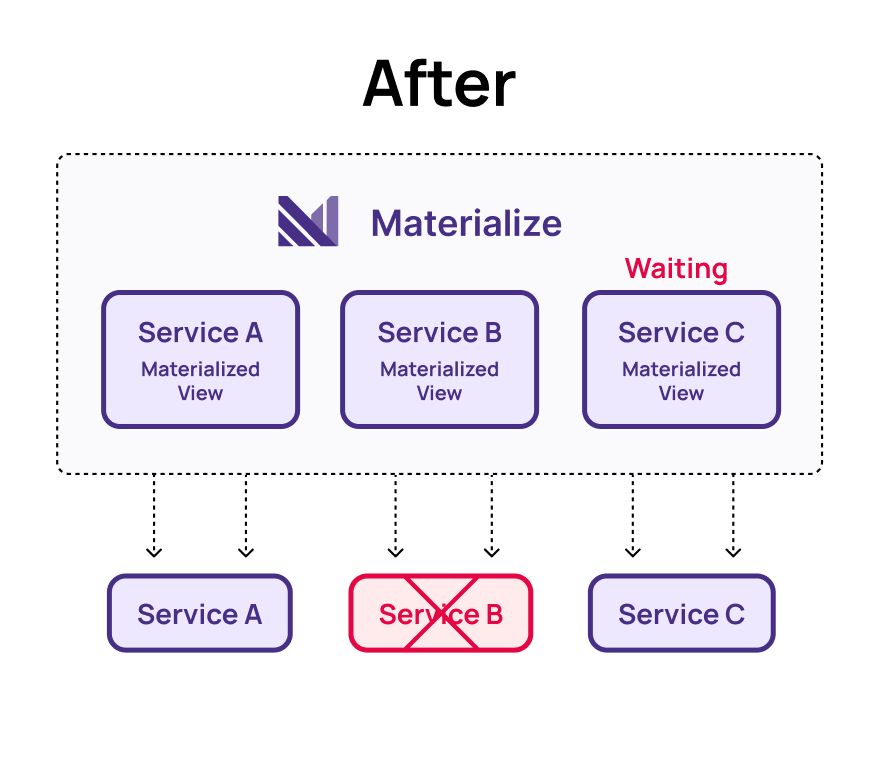
In an event-based Materialize architecture, where services gather all necessary data in a materialized view, this problem becomes simpler. If the customer service goes down, the delivery service simply stops receiving new records until the customer service is back online. Once restored, the system resumes processing the data, handling requests as they appear in real time.
This approach avoids reconvergence issues because the data pipeline itself acts as the execution trigger. Because there is a shared data plane, the state of the system is not siloed in multiple databases that need to be brought into agreement. It also makes troubleshooting easier, as the pipeline clearly shows where the failure occurs, since services downstream of the failure will simply not run. Additionally, this prevents other services from generating numerous failed requests or clogging the logs with connection errors. An event-driven architecture simplifies development by eliminating the need for complex retry logic during recovery.
Conclusion
By treating materialized views as data products—public APIs that maintain strong consistency while insulating services from internal changes—Materialize preserves the core benefits of microservices while unlocking the power of database-level transformations and queries. Teams can focus on building great applications, confident that the database layer is handling data complexity, consistency, and performance efficiently.
