Compile Times and Code Graphs

This is a Materialize engineering post originally published on Dan's blog at https://blog.danhhz.com/compile-times-and-code-graphs
At Materialize, Rust compile times are a frequent complaint. On one hand, I'm forever anchored by the Scala compile times from my days at Foursquare; a clean build without cache hits took over an hour. On the other, Go at Cockroach Labs was great. Rust is in between, but much closer to Go than to Scala.
So far, I've mostly insulated myself from this here by carving out an isolated corner where unit tests catch almost all the bugs and so iteration is fast. But recently, I've been pitching in on some cross-cutting projects, felt the pain that everyone else is feeling, and so was motived to improve them a bit. Here's how I did it.
First, a note that there are lots of other ways to improve compile times1, but today we're going to talk about dependency graphs in code.
In general, the following will be talking about the smallest compilation unit that doesn't allow cyclic dependencies. In Rust, modules do but crates don't and indeed today we're talking about crates. For simplicity, I'll just use "crate" below, but go ahead and mentally substitute whatever the equivalent is in your language of choice.
Ideal Code Dependency Structure
This is going to sound obvious when written up, but bear with me.
Large software projects that involve lots of business logic will typically be broken up internally into crates (or crate equivalent). Day-to-day work will then involve typing up and iterating on some change until a good structure is worked out, the bugs are fixed, new tests are passing, old tests are passing, etc. In practice, the majority of these iterations of the edit-compile-run loop will only touch one crate (or a few). For this to be fast, you want as few crates as possible to depend on the one you're changing, and for the dependents that do exist to be as small as possible.
Secondarily, when you pull in new code to your branch, or switch branches, you want your crate's dependencies to be as small as possible. However, note that a dependency that doesn't change often isn't as bad because your compiler will get cache hits for it.
At some point, you'll be happy with your change and will move on to integration testing, which requires compiling all binaries that transitively depend on it. This means you want your crate to only be in the binaries where it "belongs" (it's surprisingly easy to end up with "incidental" dependencies if it's not something you're looking out for).
The logical conclusion of the above is a shape where a small number of infrequently changing foundational crates are at the "bottom" of the graph, then a lot of fanning out to business logic crates, which fan in to some number of binaries (production binaries, test binaries, etc) at the "top" of the graph. This shape also is particularly friendly for hermetic build systems (a la bazel, buck2, pants) that can reuse compilation artifacts generated by machines (e.g. CI).
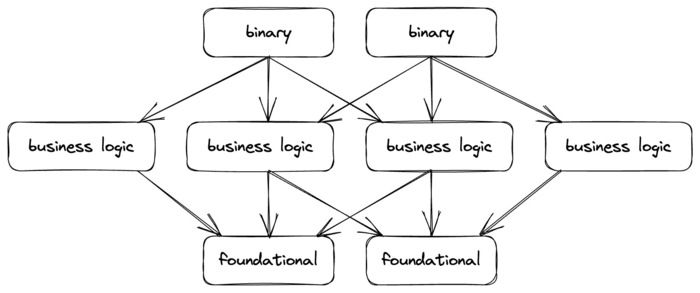
A Pattern Emerges
The above image describes an ideal, but what does that look like concretely? Both Foursquare and Materialize have ended up with a similar manifestation.
For each unit of business logic foo, separate crates for:
- Types: for Plain Old Data, protobuf, traits that users of
fooimplement, etc. - Interface: for the public API without an implementation. Foursquare called this
FooService. Materialize calls itfoo-client. - Implementation: for the implementation of the public API. Foursquare called this
FooConcrete. Materialize calls itfoo. - Note that not every
foowill have all three of these, and some will be more complicated, but I've found these three to be a reasonable default.
Foursquare leaned heavily into microservices and, as a result, broke things up into lots of fine-grained business logic units. The cost of manually maintaining the transitive interface/implementation graph for each of these microservice binaries was high enough that they eventually ended up writing bespoke tooling to do it. It all felt a little silly, but the compile time benefits were absolutely worth it.
On the other end of the spectrum, as Arjun and Frank as well as Brennan have described, materialize has three high-level architectural concepts: adaptor (control plane), storage (data in and out), and compute (efficient incremental computation, the heart of Materialize). There are additionally a small handful of internal utilities, one of which you'll see below (stash).
Case Study: Materialize Storage
I recently started doing a bit of work within the implementation of our "storage" layer and found myself surprised with some of the crates that got invalidated while I was iterating. This resulted in a PR to tease out some *-types crates that had previously been in the *-client ones.
Interestingly, the times for building binaries (necessary to run integration tests) while iterating was essentially unchanged: 1m40s -> 1m39s. This is likely because our link times are high and tend to dominate. However, the time it took to check that I had no compile errors was cut in half: 45s -> 23s. This is largely because the heavyweight mz-sql and mz-transform no longer get invalidated (i.e notice that they dissappear from the graph below).
Deps above mz-storage-client (before)2
Deps above mz-storage-client (after)
Case Study: Materialize Stash
Shortly after, a co-worker mentioned in a weekly team sync that he was spending quite a bit of his time compiling while iterating on our internal stash utility. This was particularly interesting to me because each time he changed it, both of our environmentd and clusterd binaries would be invalidated and recompiled. But conceptually, the stash is only used by the former and it shouldn't be in the dependency graph of the latter at all. The fix turned out (yet again) to be a new -types crate.
This result was more dramatic. The full-binary integration test iteration time went from 2m12s to 53s.
Deps above mz-stash (before)
Deps above mz-stash (after)
Difficulties
As always, things in software are never black and white, nor are they easy. Here is a non-exhaustive list of a few things I've seen come up when working on code dependencies:
- Dependency spaghetti! Foursquare started as a single compilation unit and everything depended on everything else. We had to gradually tease it apart over the course of years. Materialize has the dual benefits of starting with early engineers that understood the importance of internal dependency hygiene as well as a recent rework from local, single-binary deployment to cloud-only (abstraction boundaries are still in good shape from this).
- This sort of work often forces bits of code to be public when they'd rather not be public. The stash example above had a number of these tradeoffs involved. Just this morning I investigated another possible separation where the balance went the other way and I aborted.
- Regressions. It's easy to accidentally re-introduce a dependency that you've taken care to remove, even when you're looking out for it. It's even easier when co-workers are not yet sold on the benefits. I wrote a tool for Rust called cargo-deplint that we run in CI to prevent backsliding.
Footnotes
- For example, one of my co-workers has been using Rust's excellent introspection tools on our codebase and had some results that point at monomorphization. This work is still ongoing. ↩ ↩
- Generated with cargo-depgraph ↩ ↩
