Sync your data into Materialize with Fivetran

Materialize currently provides native connectors for sources like Kafka, PostgreSQL CDC events, or webhooks to deliver fresh, fast-changing data exactly when you need it with incrementally maintained SQL views.
Now, in collaboration with Fivetran, we're thrilled to introduce the new Materialize Fivetran Destination (available in Private Preview). This new capability further expands our reach in the data ecosystem by providing an easy way to sync your slower moving data, including data from SaaS applications, to enrich your real-time use cases.
Building the destination
Fivetran automates the process of extracting and moving data from all kinds of different applications, into data warehouses. Their superpower is the hundreds of connectors they’ve built to efficiently load data from SaaS applications like Salesforce, Google Ads, and Shopify, as well as traditional data stores like Amazon’s S3, Mongo DB, or BigQuery.
Fivetran has the concept of “connectors” - places you sync data from, and “destinations” - places you sync data into. Using their new Partner SDK, we built a Fivetran “destination” so you can sync your data from nearly any SaaS application into Materialize.
Working with our partners from Fivetran, we built a small service that implements their Partner SDK’s gRPC interface, which translates requests from Fivetran into Materialize compatible SQL. So when a user creates this Destination the service gets spun up in Fivetran’s infrastructure, it connects to your instance of Materialize, and updates from your SaaS applications immediately start flowing into tables within Materialize.
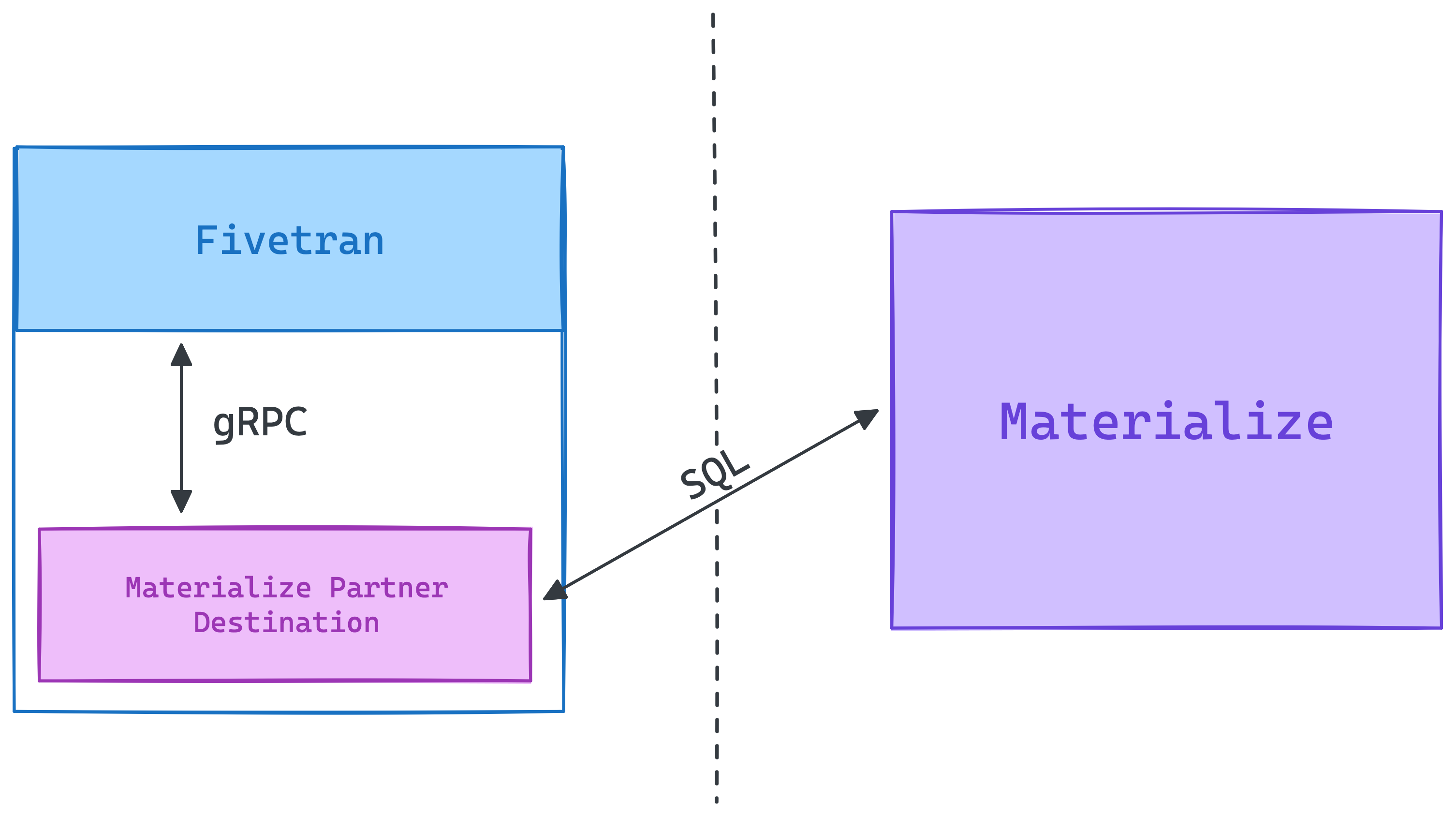
Under the hood, these updates get provided to the running service as an encrypted CSV file. Entirely within memory, we decrypt and stream the updates into a temporary table within Materialize, so your data is always encrypted at rest! Once all of the updates have made it into the temporary table, we merge them with the desired table, so the updates are reflected transactionally. From there, you can configure your SaaS applications to sync every few minutes to every few days, and start working with your data!
Using the data within Materialize
Once your data exists in a normal table, it can be joined with any other source you might have!
Crucial to streaming systems, and Materialize, are timestamps, which indicate when an event was ingested. Data from Fivetran does not sync in real-time, which creates the possibility of data from a native Materialize Source being joined with stale data from your SaaS applications. This problem is nearly unavoidable, but is addressed with the fivetran_synced column. Every Materialize table created by Fivetran will include this column, and every update will include the timestamp at which it was synced. Using this information you can get an accurate idea of how up-to-date your data is.
Upstream schema changes
When setting up a Materialize Destination in Fivetran you will need to “Block all” schema changes. In the event that new fields in your upstream data are created, they will not get synced into Materialize, unless a Destination is recreated. For well established, stable sources of data this won't be an issue. But for applications that are still evolving, you'll need to pay attention to how the schema is changing recreate the destination appropriately. We'll continue to improve on this experience as we iterate on our capabilities.
Conclusion
Fivetran is a fantastic tool for syncing a wide variety of data into Materialize in support of your use cases. Of course, if your data source is already supported in Materialize, we recommend using a native Materialize Source. Our native sources are optimized to handle large, constantly changing data sets, and ingest updates into Materialize at the lowest latency possible, and with strong transactional consistency. If you would like to learn more about our new Materialize Fivetran Destination, we encourage you to get in touch and provide feedback! Feel free to reach out to us on our Slack community and let us know what you think!
