Four Thoughts from Four Years at Materialize

I run a lot of interviews, and recently I’ve been caught off guard by a regular comment from several candidates of late. I’ll introduce myself, mention my tenure here at Materialize, and hear back from the candidate, “Oh so you’ve been there a long time.”
Wait. Have I? Are you sure you meant to say a long time? It’s only four years!
And while four years isn’t the longest, thinking back on when I joined, the world, and I, were pretty different. I started still during COVID times, when supply chains were all jammed up. My work laptop, despite having over a month of lead time before my start date, had not shipped from the factory, and I put in my first month by borrowing my partner’s laptop with woefully inadequate RAM.
Of course, I too have changed, and learned a lot, in this time. Materialize is a place like no other–a fascinating blend (or perhaps, collision) of deep academic foundations with the fast-paced trial-by-fire realities of a venture-backed startup. I’m lucky to work with and learn from so many unreasonably talented engineers. It’s an impossible task to bottle up all the learnings from my time thus far, but here’s four little vignettes from my first four years at Materialize.
Start Simple. Then Simplify.
I started working at Materialize as an engineer on our storage engine, known as persist. My tech lead, Dan, walked me through its architecture. In typical Dan trailblazing fashion, he had already prototyped out most of what needed to be done after what appeared to be three or four coffees worth of work, and he had kept the heart of the system delightfully simple.
persist was designed around linearizable consistency, removing the vast complexity that is passed on to users from any less strict consistency models. Making the system itself linearizable is hardly straightforward, but Dan constrained down the space to make it so: each shard, the atomic unit of storage in persist, would be updated exclusively through a single distributed CaS (compare-and-set operation) primitive. We would even outsource the really hard parts of the CaS operation–consensus and durability–to an external system, known as our metadata store. There would be no fancy batching, no pipelining, no speculative execution, no homegrown Raft implementations, no self-inflicted fsync durability gotchas to worry about.
This was starting simple.
When I joined, persist was prototyped to perform its CaS operation as a SQL query against Postgres, and we were in the midst of updating persist to work with Cockroach in our soon-to-be-launched managed cloud product.
What surprised me next, was just how much more there was to simplify.
I started working on the Cockroach implementation, and calling upon my past development experience, I started to mentally map out our shard metadata onto relational structures. Okay… each shard has metadata of a sequence number, read and write frontiers, pointers to blobs in object storage… and started to sketch out how they’d look as SQL tables, columns, and column types.
While I was lost in my relational reverie and starting to worry about how to write complicated multi-table transactions and think through possible lock contention, Dan simplified further. We would not be writing this shard state to multiple tables (what?). We would not even be writing to multiple columns (huh??). We would not be updating the state in-place (really!?). We would barely use column types and just write everything as a serialized blob (you’re allowed to do that?!).
In the end, each CaS update to a persist shard would produce a single 3-column row appended into our metadata store. Here was the entire schema for our metadata database.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
Three years of production usage later, this schema remains untouched. The entire foundation of how Materialize commits data is centered on these three columns of data. We use a total of four short DML statements to drive the entire persistence layer.
While I had gotten lost imagining how to leverage the full breadth of a SQL database to model our problem, Dan distilled down the essence of our core problem–a need for durable, distributed consensus–and grabbed the nearest off-the-shelf database that could solve it for us, and voila, a linearizable storage engine was born. (Almost) no schema required.
Dan started simple. Then simplified.
Reuse & Recycle
Coming into Materialize, I was familiar with software design patterns like abstraction and composition, and principles like DRY (don’t repeat yourself, or DRY).
I know now I know so little of these things.
Time and time again, working alongside the team here, I saw the senior engineers constantly finding ways to reinvest in and reuse the underlying layers of the system in ways I had never imagined possible.
Consider for a moment, some of the steps involved with producing the diagnostic data we generate to troubleshoot queries.
When you ingest data into Materialize, we create a storage dataflow that transforms your source’s data into a differential dataflow collection. Then persist writes down that differential dataflow collection to object storage, and keeps track of those writes in its metadata, where the metadata itself is modeled as a differential dataflow collection. Then when you index and query your source’s data in Materialize, we read persist’s differential dataflow collection metadata to then fetch your differential dataflow collection from object storage and feed that into a running dataflow. While that dataflow is running, we produce diagnostics about how it is performing as–you guessed it–more differential dataflow collections!
I’ve started to think of Materialize as something of an Ouroborus–a system that spirals infinitely around the same core ideas (differential dataflow collections!), no matter where you look.
Somehow, it all works, and developing the system is in many ways easier as a result. Once you wrap your head around a core concept in one place, it keeps coming back over and over everywhere else. By constantly reframing problems in terms of the ones we've already solved, we build a foundation both in our reasoning and in our tooling that makes each successive problem simpler.
I’ve also heard of this idea as domain engineering, where domain knowledge is systematically reused as the system expands and evolves. It’s a powerful concept, and the team here showed me just how infinitely deep it can go.
Design for the Future, Build for Now
There’s a constant tension in software development that I imagine is familiar to most engineers around the competing time horizons for engineering investment. Put too much emphasis on building the right long-term architecture, and one risks moving too slowly to meet the product demands of today’s users and getting outcompeted by the market. Put too much emphasis on the short-term wins, and one risks compromising the long-term vision and accruing unreasonable amounts of tech debt that stymies all future work.
There is no one-size-fits-all solution to this problem, and coming in, my prior fast-paced SaaS experience wasn’t exactly calibrated to the more time & capital-intensive pacing of building a novel distributed database.
In working with the team here, I’ve seen a consistent, highly-effective pattern that’s used to navigate this trade-off space:
- Spend enough time to sketch out a long-term vision of the system. Don’t worry about how to get there, but establish a reasonable understanding for what the system should be able to do in the future.
- Then, given that long-term vision, back out an understanding of what invariants must be true for it to work.
- Then, to meet today’s needs, make sure that all of the changes we make right now ideally move towards this vision, or at worst, are at least not incompatible with its invariants.
This allows us to monotonically approach our long-term vision, while still giving enough latitude to make pragmatic decisions today. Sometimes monotonicity is a flat line–there are times we make decisions that aren’t actively moving us towards our long-term vision, but we take pains to at least not slide backwards and make decisions that will be difficult to overcome in the future.
Here’s an example that left a big impression on me coming in:
When our Cloud team broke ground on our managed cloud product many moons ago, they knew that in the long-term, they wanted to be operating a multi-region cell-based architecture. They also knew that on Day 1 they’d be operating in just one region, with just one cell, and that it needed to be built ASAP. The team built out this first region quickly, while investing just enough to make sure that the grander vision would still be possible–while getting that singleton prod region & cell up and running, they made sure to run a teeny extra region with a teeny extra cell in staging. Having these extra components in staging made sure the invariants of being capable of multiple regions, and capable of multiple cells per region were always true–lest the deploys and tests break–while only adding a small bit of overhead to development.
Lo and behold, the first prod region got off the ground quickly. And then months later when the time came for us to support our second region in prod, it was up and running within a day.
We actually haven’t yet had a need for running multiple cells within a region in production yet, but having the vision of multiple cells as a design principle early led us directly to better abstractions that made making Self-Managed Materialize straightforward – the self-managed deployment we give to you now is effectively one of the modular cells we’ve been thinking about for years, all thanks to that extra bit of forward thinking early on.
Speed Limits
Every company has their own lingo, and Materialize is no different. Within Eng, the vernacular is filled with expressions of “in the fullness of time”, “morally”, “moments”, and “the speed of light” that trip up all newcomers, myself included.
“The speed of light”? This one I’ve learned to refer to whether we understand the fundamental limits of a part of the system given its current architecture, or sometimes the problem space itself. The “speed of light” may refer to a variety of different measures (throughput, latency, memory usage, on-disk storage, etc.) but the value of grokking that theoretic bound is the same for any.
How we identify the “speed of light” can vary – some parts of Materialize were designed very intentionally around certain properties with a known “speed of light” in mind. Thinking back to persist, by design a shard is updated by one atomic, distributed compare-and-set operation at a time. Therefore the fastest an individual shard can ever evolve is set by how quickly we can perform serial CaS operations–this is the “speed of light”, the upper bound on the design with regard to update rate.
Often though, a piece of the system has organically evolved in ways where we don’t know the “speed of light”, and need to invest time to truly understand what we’ve built and what governs its runtime characteristics.
While understanding a component’s “speed of light” is valuable in and of itself, there’s another important speed limit: how does the system actually perform today? There are various ways to measure this, whether through synthetic benchmarks of individual components, load tests across the whole system, or empirical evidence gathered from real-world usage.
A trick I’ve learned here is how this pair of speed limits helps one navigate tricky engineering & product decisions. I like to think of them in pictures:
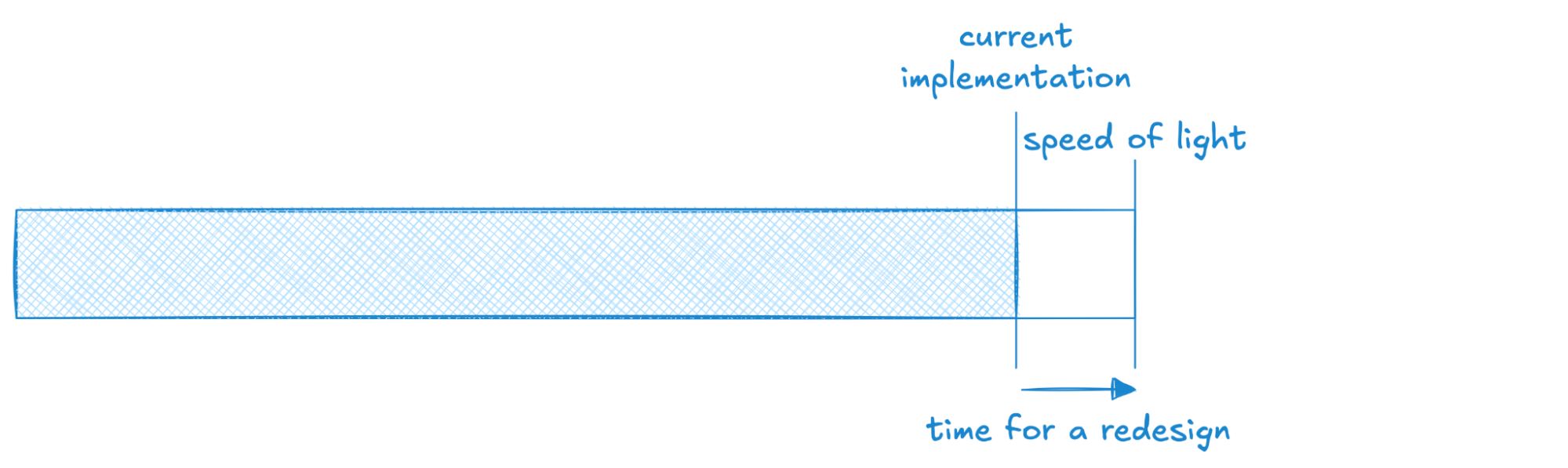
In this scenario, we’re looking at a system whose implementation is approaching the “speed of light” for its design–there’s a bit more juice to squeeze, but not much left. If this is an essential runtime characteristic for users, this means we need to be sketching out what the next architecture will look like! Often the types of redesigns that allow us to 10x or 100x some dimension of performance take substantial time to develop, and we don’t want to be caught flatfooted by users who need the next level of performance sooner than we expect. We also wouldn’t want to commit to a new customer workload that pushes us above our “speed of light” without confidence that a new, improved design is well on its way.
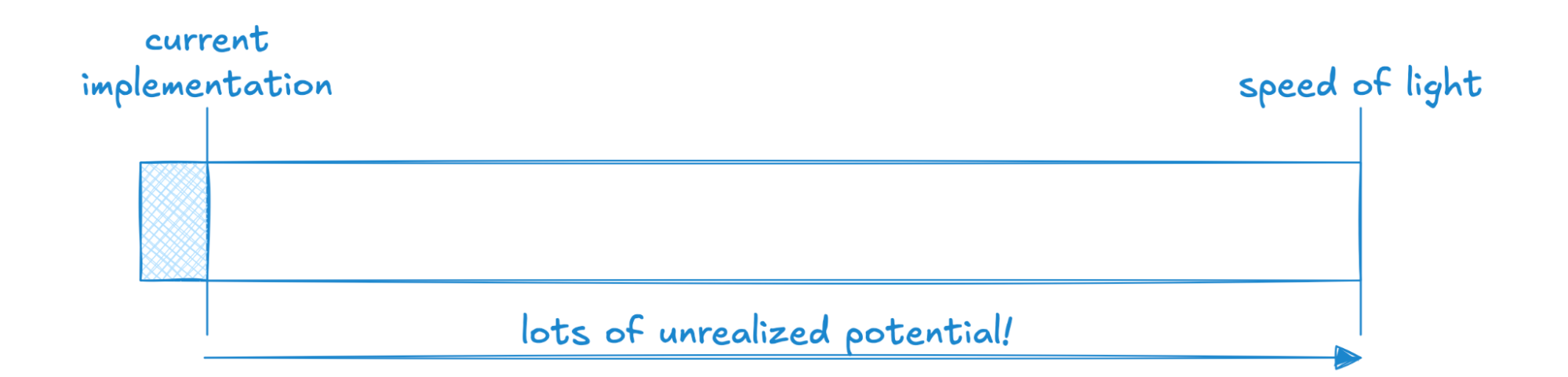
Here we have a system that has a much higher “speed of light” than what we’re capable of today. This generally means there’s a lot of known, or known-unknown, engineering work needed to pull the system closer to its theoretic limit.
This scenario is how I think of our persist example from before–our ability to update an individual shard is capped by serial CaS operations, which today is ~8ms per CaS, so our “speed of light” on update rate is on the order of 125Hz. In practice, we operate at 1Hz today, sometimes 2Hz. That’s a ton of headroom in the design! That alone doesn’t mean making progress will be easy, but we’re well aware of many hard problems we could solve, before having to redesign persist from the bottom up, to go faster than we currently do. And in having a reasonable understanding of our speed limits, we’re able to make informed decisions on whether to take on prospective users / workloads that might push us on this dimension.
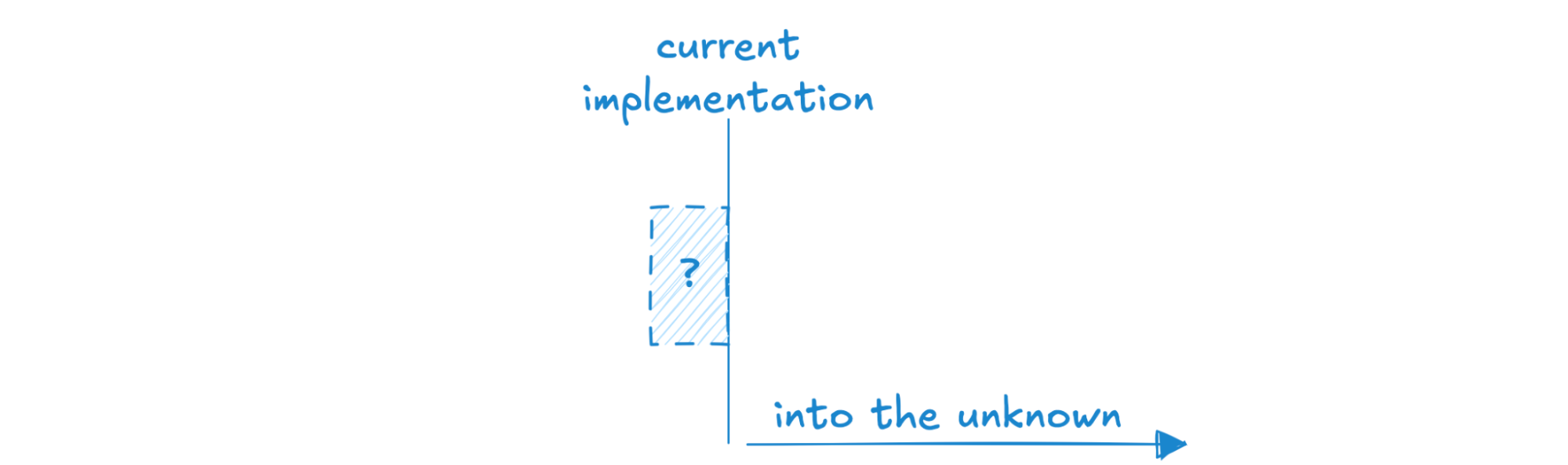
One more picture – I’d argue a great number of systems out in the wild look like this, where the “speed of light” is wholly unknown, and the current implementation is loosely understood as “whatever is currently happening on prod.” There are many systems out there for which this works fine, and the speed limits are determined as-needed, or maybe never. I’ll be not-so-bold and say this is a less effective strategy for building an operational database where earning and sustaining trust is paramount, and where we want to be able to confidently understand the performance characteristics of workloads over time as best we can.
The last big idea that I’ve picked up that I’ll share here is that, while knowing the speed limits of an individual component is valuable, speed limits become extra powerful when put together. By building a catalog of all known speed limits across the system, we give ourselves a high-level perspective of the entire product surface area, with benefits spanning the org. For Engineers, having a catalog of speed limits is helpful to know where the low-hanging fruits lie, identifying which parts of the system require re-architecting, and how those improvements might fit into short & long-term plans. For Product, it’s valuable to understand what we are capable of today, where our blind spots are, and to see the menu of options available to improve the product. For GTM, knowing these speed limits allows them to qualify which customer use cases fit well within our wheelhouse, which ones are clearly out-of-bounds, and which ones push up against a speed limit in ways that are worth discussion.
I won’t say we’ve mastered the art of this cataloging yet, but it’s where we’re headed, and what we have today has already been highly impactful.
And there you have it. Four little vignettes from four years time. It’s been an amazing ride so far, a wonderful team to work with, and I can’t wait to see what gets built next. And of course, if any of the work here sounds exciting, I’d be remiss to omit plugging our Careers page :D
Until next time!
