Loan Underwriting Process: The Move to Big Data & SQL

In today’s competitive market, loan underwriting is a space where shaving a few seconds off a funding decision can lead to millions of dollars in profit.
But eliminating those few seconds isn’t so easy. To make that happen, many lenders invest in expensive data architectures.
In order to remain competitive with rivals, lenders need to serve and analyze data as fast as possible. That’s why so many lenders strive to incorporate real-time data into their loan underwriting process.
Real-time data allows underwriters to access borrower information and make loan determinations almost instantly. This enables lenders to fund more loans and generate higher profit margins.
But how do lenders achieve real-time data? What technologies do they use? And how do they do it cost-effectively?
In the following blog series, we’ll answer all of these questions and more. Download our new white paper — Loan Underwriting with Real-Time Data — for a full overview of real-time data in the loan underwriting process.
To start, let’s examine the loan underwriting process, including the current landscape, credit modeling, and the move toward big data and SQL.
Loan Underwriting: The Current Landscape
In the past three decades, loan underwriting has experienced a dramatic transformation. Underwriting methods, along with the data sources used by underwriters, changed significantly.
In the past, banks and financial institutions set standard underwriting practices. These underwriting models relied heavily on proprietary credit scores such as FICO. Credit scores are derived from credit reports produced by consumer reporting agencies (CRAs), such as Equifax. CRAs utilize a variety of credit products to assess creditworthiness, including mortgages, credit cards, auto loans, and student loans.
Credit reports contain data such as payment history, accounts in collections, number of credit applications, and more. This data helps predict whether a borrower will be able to repay a loan on time. Lenders entered this historical credit data into their risk models to make loan decisions.
Up until the early 2000s, this credit-based underwriting model dominated the lending space. That’s when fintech lenders first emerged. In order to outmaneuver the banks, fintechs adopted digitally-native infrastructures, and targeted a new kind of borrower: those with thin or bad credit.
This untapped pool of borrowers has enormous potential. Today, over 62 million Americans possess thin or non-existent credit files. Before fintechs, factors that might indicate successful repayment, such as income, bank account balance, or utility bills, were not weighed heavily by lenders.
To serve more borrowers, fintechs created a new kind of underwriting model called cash flow analysis. Cash flow analysis did not measure credit, but rather the flow of money into and out of a borrower’s bank account. This can be a more accurate assessment of a borrower’s ability to pay a loan. Borrowers burdened with bad FICO scores can now access loans because their cash flow is viable for repayment.
With this new pool of applicants, and digital-first infrastructures, fintech lenders were quickly able to scale up successful lending operations. Now it’s the banks who are playing catch-up in terms of technology — and copying some of the tactics of their digital-first rivals.
Today, loans are available from thousands of lenders — banks, fintechs, and more — in an online market saturated with options. Borrowers demand a seamless customer experience, with no friction, and rapid loan decisions. Unhappy borrowers can easily switch over to other options in a few seconds.
In this realm of cutthroat competition, lenders must make loan decisions as fast as possible. And to do this, they must maximize their data operations, the backbone of the loan underwriting process.
Data in Loan Underwriting
Historically, underwriters manually gathered data from credit scores, identification documents, and other paperwork. This process was mostly conducted by hand. Risk models were centered around credit metrics: payment history, number of open accounts, delinquent accounts, and more. Underwriters captured this data and made loan determinations with pen-and-paper, or old computer systems.
In the 1990s, the advent of online banking and crediting digitized some of this data, and made it available to underwriters. Lenders began to produce more sophisticated software for credit modeling. More lenders started to store and analyze data in on-premise databases, including MySQL and Oracle.
In the early 2000s, fintech lending and new database technologies emerged. This increased both the type and kind of data collected in the underwriting process. Fintech lenders developed cash flow analysis, and derived cash flow analytics from bank account data to power this new underwriting process.
Cash flow analytics include income/revenue, expenses, transaction categories, ratios, trends, overdrafts in the last ninety days, and more. These cash flow analytics can help fintech lenders understand the seasonality of cash flow, track non-traditional income, assess debt capacity, and identify recurring transactions.
On the backend, the emergence of Spark, Hadoop, AWS, and other technologies enabled lenders to apply SQL-based risk models to large data sets. In the 2010s, the rise of cloud data warehouses expanded this capability, and enabled fintechs to avoid expensive on-premise databases.

More recently, the introduction of machine learning models and data enrichment have enhanced the loan underwriting process. Data enrichment supplements, refines, and improves raw data to prepare it for usage. In the case of cash-flow based underwriting, data enrichment involves using ML models to augment raw borrower financial data.
Before data enrichment solutions, there were many unused data points in the underwriting process. For instance, a financial transaction on a borrower’s bank account retains metadata such as merchant details, amount, currency code, MCC code, and more. But this raw transaction data is too messy for humans and language models to understand.
However, data enrichment solutions automatically transform this raw transaction data into structured data for underwriting. With this enriched data, underwriters and credit models can process more borrower data, and assess risk more accurately. They can also develop advanced analytics around borrowers to improve loan decisioning.
Today, lenders employ both automated and manual methods for collecting data. Financial aggregators such as Plaid automatically collect bank account data from borrower bank accounts. Underwriters also manually enter data into the front end user interfaces of their proprietary underwriting systems.
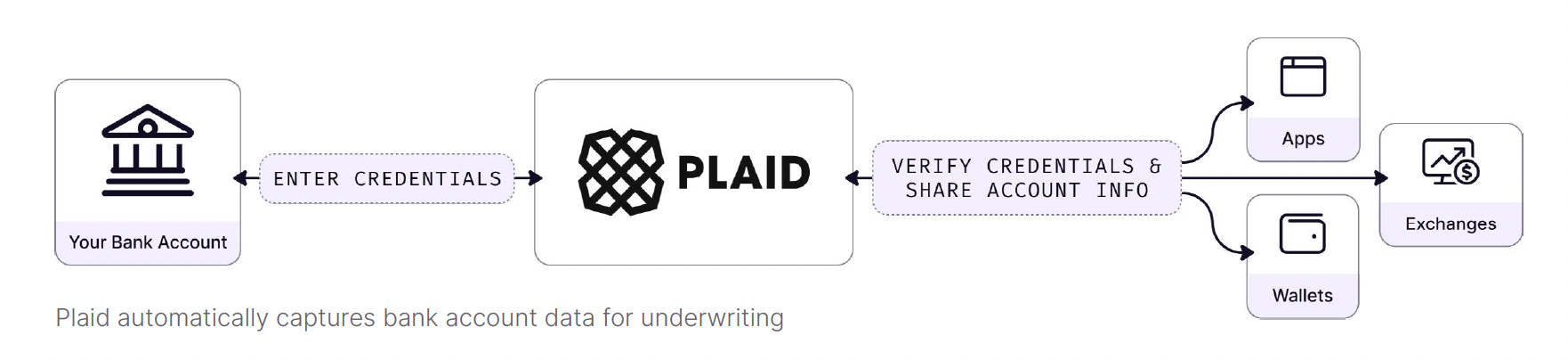
From the front end system, the data is combined into database tables, and sent to the backend data infrastructure. This backend data infrastructure might include streaming databases, microservices, operational data warehouses, and more. We’ll cover these technologies at length in a later section.
When an underwriter requests a determination from the front end system, the database tables are queried with SQL logic that represent the lender’s underwriting rules. SQL is a versatile language for loan underwriting. Let’s take a closer look at why SQL is compatible with underwriting.
SQL: Business Logic for Loan Underwriting
There are a number of reasons SQL is ideal for loan underwriting. First, there is a basic compatibility with the mechanics of loan underwriting and SQL.
When lenders develop their underwriting models, they are essentially defining a set of rules. These rules include or exclude a borrower from loan funding. The underwriting rules serve as a kind of logic. Borrower data is inputted into the logic, and the logic outputs loan determinations.
It makes sense to code this logic in SQL. SQL’s ability to manipulate data, apply instructions, and return determinations is an agreeable format for underwriting logic. With SQL, lenders can easily harness borrower data in backend databases and code their underwriting rules in straightforward commands.
SQL is a flexible language that allows lenders to handle large datasets quickly, analyze data more accurately, join data from multiple sources, and manage data more efficiently. SQL supports the complex calculations and data transformations essential to loan underwriting. The language also effortlessly integrates with popular financial tools for enhanced data analysis.
Benefits of SQL in the underwriting process
Amenable to underwriting logic
Accessible by data analysts and capable finance professionals
Portability across databases and data warehouses
Join borrower data from multiple sources easily
Support complex calculations and transformations for underwriting
Add new SQL underwriting rules rapidly
SQL is portable between the various databases and data warehouses lenders employ. And as underwriters add more underwriting rules, the lender can layer on additional SQL logic with ease. This is especially beneficial for fintechs with rapidly changing loan underwriting models.
SQL is also attractive to lenders because of its broad accessibility. Some streaming databases require knowledge of Scala and other obscure languages, making them inaccessible to analysts. With 7 million users worldwide, SQL allows data analysts and capable finance professionals to create loan underwriting models with ease. This enables faster iteration and more robust underwriting models.
However, employing SQL in loan underwriting is not always a simple feat. To beat the competition, loan underwriting decisions need to occur in seconds. This requires near real-time data in the underwriting process. Until recently, a unified solution that combines real-time data with SQL support remained elusive.
As a result, lenders have resorted to a number of different methods to achieve real-time data flows for effective loan underwriting. In the following section, we’ll examine the various data solutions lenders have employed to implement rapid loan decisioning, including options for SQL support.
Next Up: Data Architectures for Real-Time Data
Now that you’re familiar with the current state of loan underwriting, download our new white paper to learn more. The white paper — Loan Underwriting with Real-Time Data — is free to download.
And stay tuned for the next entry in our loan underwriting blog series. In the next post, we’ll examine the different data architectures lenders use to power real-time data in their decisioning processes.
