The Making of Materialize Self-Managed: Flexible Deployments Explained

After years of running and honing our managed cloud service, we recently announced the launch of our new offering: Materialize Self-Managed.
This release marks a new foray for the organization and introduces all sorts of new challenges for our engineering team. Trying to distill down the essence of operating Materialize into something neatly packaged up for self-managed installations has challenged many of the abstraction boundaries we had set for ourselves, and in doing so, has actually improved the architecture of our SaaS offering.
Here’s how the journey to creating the self-managed product has led us to better decisions in our managed cloud service as well, and how Materialize is a better product on both as a result of being flexible about where it is being deployed.
Why: From one deployment model to two
Operating a SaaS-only product is a cozy comfort. With the full knowledge of every Materialize deployment in existence, we’re able to make sweeping changes without worrying about the hard problems of backwards compatibility. We can observe every deployment consistently with an observability stack that is tailored just right for our infrastructure (my favorite feature is our per-second CPU and memory profiles of every Materialize process, courtesy of Polar Signals). We can understand product usage and analytics at a global level, knowing exactly which features are performing best and which ones need attention.
Offering a self-managed option introduces numerous engineering challenges. We no longer have the same kind of window into the performance of every Materialize instance. We do have to consider backwards compatibility, observability, and support across a wider range of cloud environments. We no longer have the same type of visibility into how people are using the product, which means we’ll have to do different types of legwork to figure out where we as engineers should be spending our time.
So in other words, it’s more work for us – but offering this second deployment model also makes Materialize accessible in a much wider range of use cases. And building Materialize Self-Managed actually turned into an interesting exercise not just in the design of a new form factor for our product, but in the new perspective it gave us on our existing managed cloud product.
What: The essence of Materialize
To build out a self-managed product, we first needed to distill the essence of operating Materialize out of its existing managed-cloud-service form.
To do so, we first enumerated all the functions of our managed cloud product that we’ve built. We knew that somewhere within this list would be all of the core functions a self-managed product would need as well.
Our initial list had these core functions:
- Assigning each customer to one of our Kubernetes data plane clusters
- Provisioning blob storage and a metadata database for each customer
- Provisioning Kubernetes namespaces + service accounts for each customer
- Provisioning compute resources for each customer
- Creating endpoints for our zero-trust auth solution
- Collecting usage & billing data
- Managing VPC endpoints for private network connectivity
- Plumbing through our static egress IPs
- Managing internal mTLS certificates
- Creating Kubernetes / Cilium network policies
- Collecting advanced Prometheus metrics via SQL
- Orchestrating version upgrades
As we drew out these responsibilities, we started to see a clear dividing line between (1) the core functions that are required to operate Materialize regardless of where it runs, and (2) the functions that are required for us to operate Materialize as a full-featured, fully-managed SaaS product.
The first category (operating Materialize-the-database) included features like provisioning and deprovisioning Materialize processes, orchestrating version upgrades, managing mTLS certs and network policies. These are essential low-level functions core to any production installation of Materialize. These would have to be part of a self-managed product.
The second category (operating Materialize-the-managed-cloud-service) included everything else: the billing pipeline, the metrics pipeline, all of our private networking options, even the automated provisioning of requirements like blob storage + metadata database fell under features that we need to operate a managed cloud service, but not ones that every customer will need for self-managed installations.
Because we had not built our SaaS product with self-managing in mind initially, the code didn’t reflect this divide, so there was some work to do.
How: Maximum flexibility
We now knew what functionality we needed to package up for self-managed installations. We next needed to answer how to package up that functionality. What form factor are users looking for? And, are there any hard requirements we need to set in place for running and supporting Materialize Self-Managed?
This latter question is deep, and tricky. It’s all about tradeoffs: We know there is value in offering flexibility in deployment models - as evidenced by the number of prospects interested in a self-managed option. But we also knew unbounded flexibility in where Materialize gets deployed would be unreasonable for us to support (e.g. we’re not supporting production clusters on Raspberry Pis, sorry friends!). We need some guardrails to ensure each installation can be successful. So: How could we ensure each Materialize Self-Managed is a success, while still being as flexible as possible?
We wrote down every assumption we have today about where and how Materialize runs, and reasoned through which ones were hard requirements, which ones were nice-to-haves, and which ones didn’t particularly matter.
We sifted through a lot of questions: Should we require specific cloud providers? Do we require Kubernetes at all? Or in the complete opposite direction, do we require a very specific Kubernetes distribution and version? Or maybe it needs to be an empty Kubernetes cluster? Or just a dedicated namespace? Hmm, do we require fast local NVMe for spilling memory to disk, as we have in our managed cloud service? If so, do we require the same CSI as we use? How about needing S3 as the blob storage backend? Do we require certain instance types? The questions went on and on.
In the end, we landed on only three hard requirements.
- We need a Kubernetes cluster to run in.
- We need a Postgres database for metadata storage.
- We need blob storage.
Kubernetes: While at a technical level, nothing about operating Materialize fundamentally needs Kubernetes over any other orchestration framework, we have years of experience operating in Kubernetes in our managed cloud service. We’ve learned a lot on the way. We do not think, at this point in time, we could offer an appropriately excellent level of service to a non-Kubernetes installation. We aren’t picky – we aren’t asking for a specific distribution or only the latest version – but we need Kubernetes.
Postgres: Similarly for metadata storage, we have thousands of hours testing and using Materialize with Postgres as its metadata store. Perhaps in the future we’ll support other databases, or go wild and implement a metadata storage layer specialized to Materialize’s workload, but those possibilities are long off. Operating Materialize with Postgres as its metadata store is tried and true.
Blob storage: Materialize writes most of its persistent data to blob storage. We’re less opinionated about exactly which blob storage system we’re writing to. We’ve heavily vetted S3 and MinIO, but our access patterns are simple and predictable, and we believe we can make most production-level blob stores work – especially if they’re S3 compatible. Let us know if you need something else and we’ll look into it.
We also felt pretty good about the accessibility of these requirements. Many of our prospects and customers already have all three of these services within their existing infrastructure, and/or are running in cloud providers that can provision managed Kubernetes, Postgres, and blob storage with the click of a button.
Identifying these requirements then neatly clarified what we’d need to build for packaging up our self-managed product. If we know there’s a Kubernetes cluster available, then we can package up our code into a Helm chart, which has become the de facto package format for Kubernetes.
With the deployment requirements in hand, along with the functions of our cloud product we had identified to distill down, it was time to get to work building the self-managed product!
And as it turns out, there actually wasn’t too much to do. We already had almost all the code we needed somewhere for a self-managed product – after all, we needed it ourselves for our managed cloud service. Most of our work was chiseling away at our existing codebase: We removed the functions that were only necessary for our managed cloud product and moved them elsewhere, isolated the functions that are essential for operating Materialize into a single operator process, and did some light refactoring while we were at it.
Building the Helm chart was net-new, but because all of the complex logic about operating Materialize lives in the operator process, the Helm chart itself is pretty lean. Mostly, it just needs to get the operator up and running, and the operator does all the heavy lifting of provisioning / upgrading / deprovisioning Materialize.
And that’s part of why we are so confident in this recent release: While Materialize Self-Managed is technically a new offering, it’s really the same product that we’ve honed for years – just packaged up for you to run, too.
1 + 1 = 1 (?!)
We had been anticipating that supporting two deployment models would be at least twice as difficult as supporting one – that we’d be maintaining two separate code bases with separate concerns – but we managed to unify much of the code and the process of building Materialize Self-Managed has actually improved and simplified our managed cloud service architecture. To understand why, let’s peer into the innards of our cloud architecture.
Our infrastructure is composed of two layers: A regional control plane (its own small, dedicated Kubernetes cluster) for each cloud provider region we operate in, and N data plane clusters (also Kubernetes) that house customer workloads within that region. It looks like this:

Prior to the push for a self-managed product, the regional control plane would assign a new customer account to a data plane cluster, provision its backing blob storage + metadata database, and then let the data plane cluster create things like Kubernetes namespaces and the magical compute resources that make Materialize go. Within the data plane cluster, we ran a number of background jobs to complete the offerings of our managed cloud – responsibilities around billing, metrics, zero trust access controls, VPC endpoint management, mTLS, network policies and more.
But for a long while now, we had been wrestling with the split responsibilities of the regional control plane vs data plane clusters. Over time as the complexity and features needed in our managed cloud service grew, where to put each function had become blurry. This led to many debates, and it led to slower development. We couldn’t quite put our finger on the right dividing line, but we knew we were missing some insight in how to better organize our cloud architecture.
As we thought more and more about what was needed for the self-managed product, the boundary we needed for our own managed cloud service became clear:
- The regional control plane should own every function unique to our managed cloud service. This control plane is a feature of our managed cloud service, not of every Materialize installation, and therefore it should own every function that makes the managed cloud service special.
- A data plane cluster should look exactly like a self-managed installation. In fact, it should install the very same Helm chart that we give to you, because it owns the essential operations every Materialize installation requires.
This gives a new picture, similar to the previous, but with much clearer and tighter dividing lines:
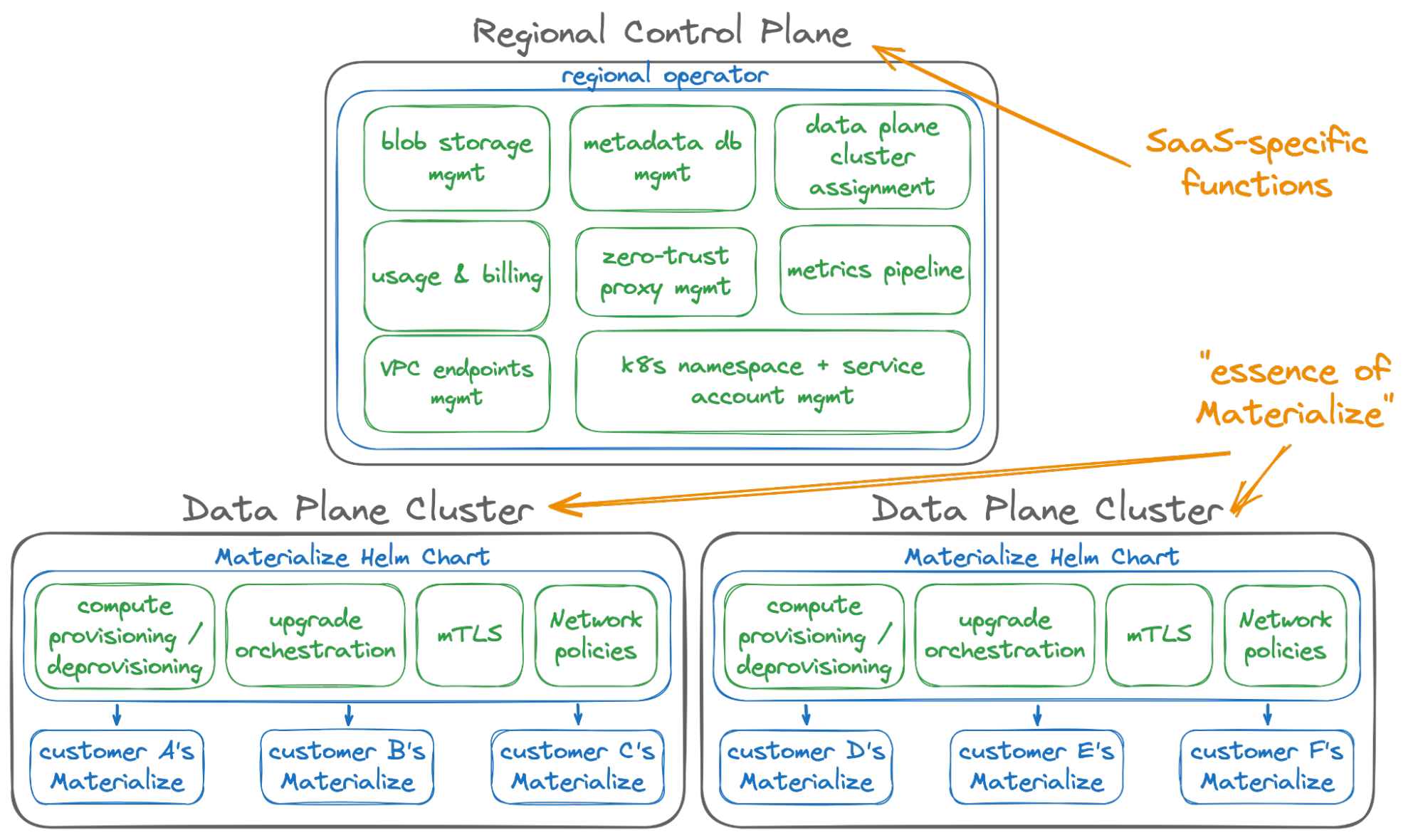
While it might seem small, clarifying this boundary has made developing our managed cloud service smoother, and it’s a better product as a result. It’s easy now to figure out where each bit of functionality goes – does it benefit every Materialize install? If yes, Helm chart. If no, regional control plane. This has led to some shuffling of our codebase, mostly us hoisting responsibilities out of the data plane clusters into the regional control plane, and each transition completed has made us increasingly confident this is the right direction for our infrastructure.
The new design comes with some great perks, too. Running the same Helm chart we give to you both means that we get to really put it through its paces, and that we get to minimize our own engineering overhead of maintaining multiple deployment models. While there are some elements that are different between self-managed installs and our managed cloud service – ingress and load balancing in particular – the differences are small, and the essence of operating Materialize is the same.
The future is flexible
Today’s infrastructure is as varied as ever, from in-house on-prem deployments, to cloud-only deployments, to everything in between; there is no one size fits all. Our prospects have made it clear that Materialize solves their real-world problems of making fresh, transformed data available throughout their organization no matter the shape of their infrastructure, and that underscores how we at Materialize need to meet them where their data is.
For this, we needed Materialize to become flexible in where it is deployed – and so we built out our self-managed product and teased apart that crucial dividing line between our control plane and data plane.
While this work has given us the flexibility our customers need today, we’re also very excited about how it gives us flexibility going forward. Our new control vs data plane dividing line challenges us to consider each new architectural change under the lens of how it impacts each deployment model. It makes us set good boundaries.
We now test self-managed installations in multiple cloud providers every night in our CI suite, and we are working on more. We are actively building out support for more blob storage backends. We are working with our Early Access users and improving the experience every day.
All of this work turns into a rising tide – by focusing on flexibility, we were able to improve our managed cloud service, deliver a self-managed product, and open up doors to hybrid models like bring-your-own-cloud in the future.
info
A note from the author
As an engineer, I feel lucky to work at Materialize. I find the underlying technology incredibly cool, and it really feels like a hitherto missing element of the data infrastructure landscape.
A huge part of my motivation in building Materialize is having seen and experienced this missing element firsthand. In a past life, I worked on customer data segmentation, which when you zoom out, looks very much like maintaining a lot of domain-specific real-time materialized views. It’s a really, really hard problem. We had access to transactional databases, message brokers, caches, search indices, and data warehouses, but none of them could directly solve our problem. Instead, we staffed a large, expensive team and did our best to glue these data stores together with reams of complex application logic, all while wishing we had a database that could just do it for us.
Materialize fills that gap. And it’s fun getting to work on a database that challenges assumptions about what is possible in a database – wait, can I really write and index arbitrary SQL to transform and join over all my data? Even if the data came from different databases? And if my logic needs lots of joins? With strong consistency? And the results are always fresh and up-to-date? Yes, yes, yes, yes, yes.
It’s been an interesting puzzle to build Materialize Self-Managed in and of itself, but what I’m really excited about is how this opens up the technology to a wider range of users. Now, the vast majority of users who could benefit from Materialize - regardless of their strict GRC requirements, or specific cloud provider and region needs - can experience this powerful technology however works best for them: in our managed cloud service, or in our self-managed product. The choice, and the real-time data transformation, is yours.
