The Missing Element in Your Data Architecture
June 26, 2024


When Dmitri Mendeleev published the periodic table in 1869, it was unfinished. It had 63 elements and many holes. The surprising thing wasn’t the gaps themselves, but where they were placed. Their location in the table provided clues as to the characteristics of undiscovered elements. Scientists now knew where to look, and with this table as a guide, discovered new elements and created a fuller picture of our universe.
Like Mendeleev’s table, the modern data stack has similar gaps. Even with the myriad of OLTP and OLAP databases, the logs, the queues, the caches, there are still missing elements. We feel their absence. Rather than waiting for science to advance, engineers found shortcuts. After all, accepting gaps won’t help their organizations keep pace with the never ending increase in customer demands, competitive pressures, or budget scrutiny.
Unfortunately, these engineering substitutions don’t have the properties of the real missing elements. Instead of harmonizing with the ecosystem, workarounds consume massive amounts of compute, labor, and energy, risking their organization’s goals in the process.
For example, slow and cumbersome Hadoop workloads were the norm prior to the discovery of Spark’s Resilient Distributed Datasets (RDDs). Expensive sharding and distributed transactions are still commonplace, as architects are only now starting to incorporate breakthrough techniques for synchronizing work across machines, which enabled Distributed SQL systems like CockroachDB.
Today, there is an element that database developers have known was missing for a long time. They knew what it should look like and even had a name ready for it: materialized view. This is essentially a way to describe the shape of data you want with a single command, and then make it available for others to use quickly and efficiently. However, in practice materialized views forced a tradeoff between freshness and database performance. That is until January 2013, when the missing element was discovered: Differential Dataflow. This solution allows for efficiently performing computations on massive amounts of data and incrementally updating those computations as the data changes.
More than 10 years later, Differential Dataflow is having a profound impact on the modern data stack by enabling materialized views to be both fresh and performant. Below, you’ll learn how replacing the legacy materialized view with this new element – and systems built to harness it – is transformational for your data stack.
Improve Database Performance and Stability with Incrementally Updated Views
SQL is the most widely adopted language for working with data. It allows users to describe what they want, but is not prescriptive on how to produce the answers. Database implementers spend decades building systems that use sophisticated query optimization and execution strategies to make SQL fast and efficient.
The disconnect between SQL the language and SQL the implementation becomes clear when teams want to get an up-to-date view of their operational systems. These are the databases that handle payments, track inventory, and log trades. This often involves complex queries that process large amounts of data, helping to do things like populate UIs and answer questions about what’s happening in the business right now.
There are two problems preventing us from running these queries efficiently:
- The Data Layout: To make transactions fast, databases are optimized for small reads and writes of rows of data at a time. This is essential for tasks like quickly and reliably transferring money from one account to another. However, this layout is the complete opposite of the columnar format needed to support complex queries over large amounts of data.
- When the Work Happens: SQL databases do the majority of the work to process a query when the user issues a command. This is a pull-based model. A more efficient approach would be to perform as much work as possible as soon as new data arrives. This push-based approach means the actual load from a complex query is minimal, as most of the work is already done.
Running complex queries on a database tuned for handling transactions can steal precious resources the database needs to quickly serve mission-critical requests. In some cases, these queries can even take a database—and the systems they support—offline.
The traditional materialized view lets you run a complex query once and then persist it to disk where it can be reused. This is the right idea but the wrong implementation. It does some work up front so reads are cheap, but doesn’t keep doing the work as the underlying data changes. There was clearly a gap in the modern data stack.
The tradeoff is substantial: you no longer have fresh data, UIs won’t match customer actions, and reports will be out of date. Updating the materialized view also creates load on the database. As you recompute views more frequently to get fresher results, you encounter the same problems you started with.
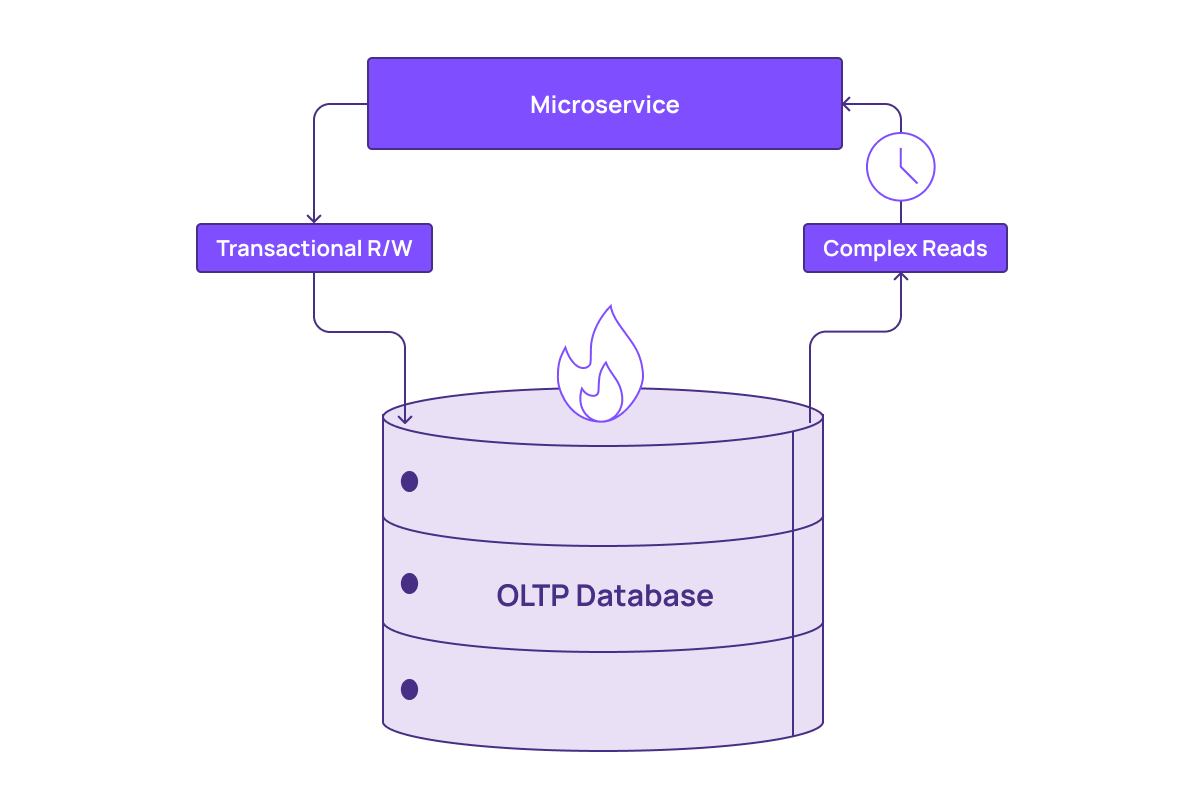
The first thing data teams do is throw money at the problem by scaling up to a bigger machine that may be better suited to handle the load. Depending on the value of the taxing query, the price/performance ratio may not make sense for their business. At some point, teams reach the limit of vertical scaling that a traditional relational database can support.
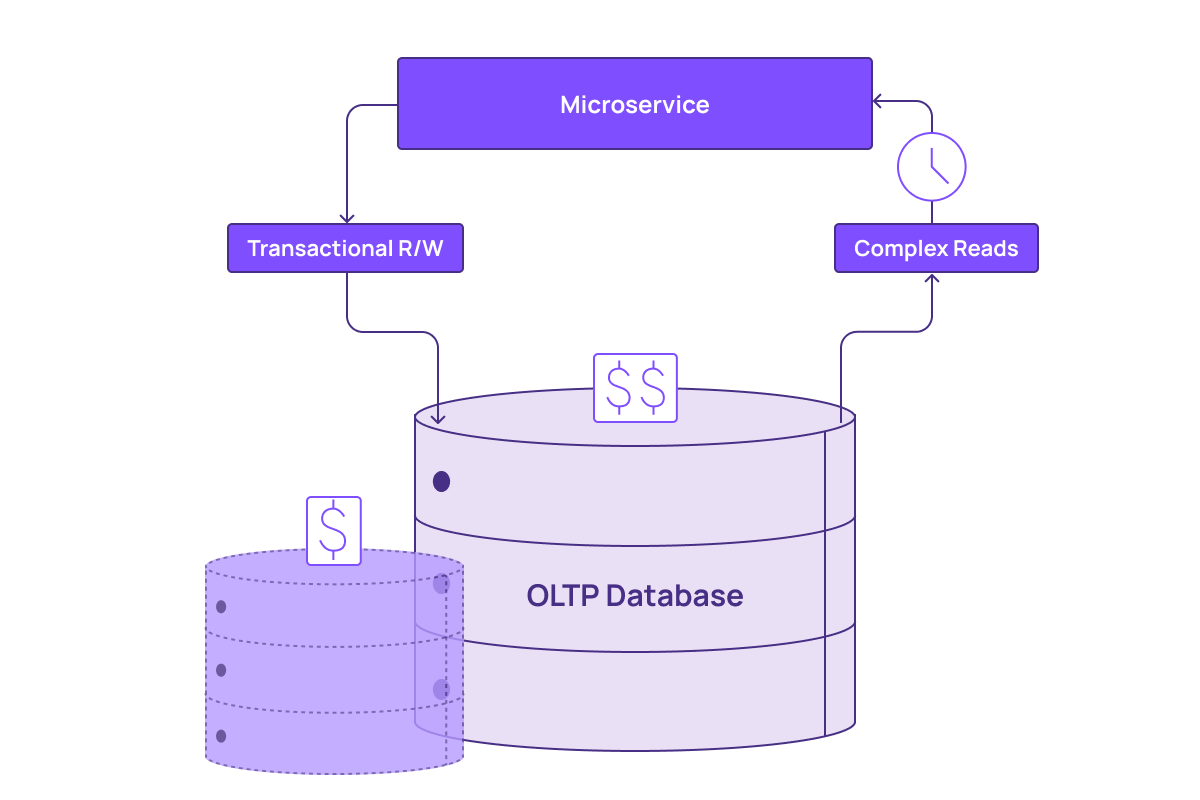
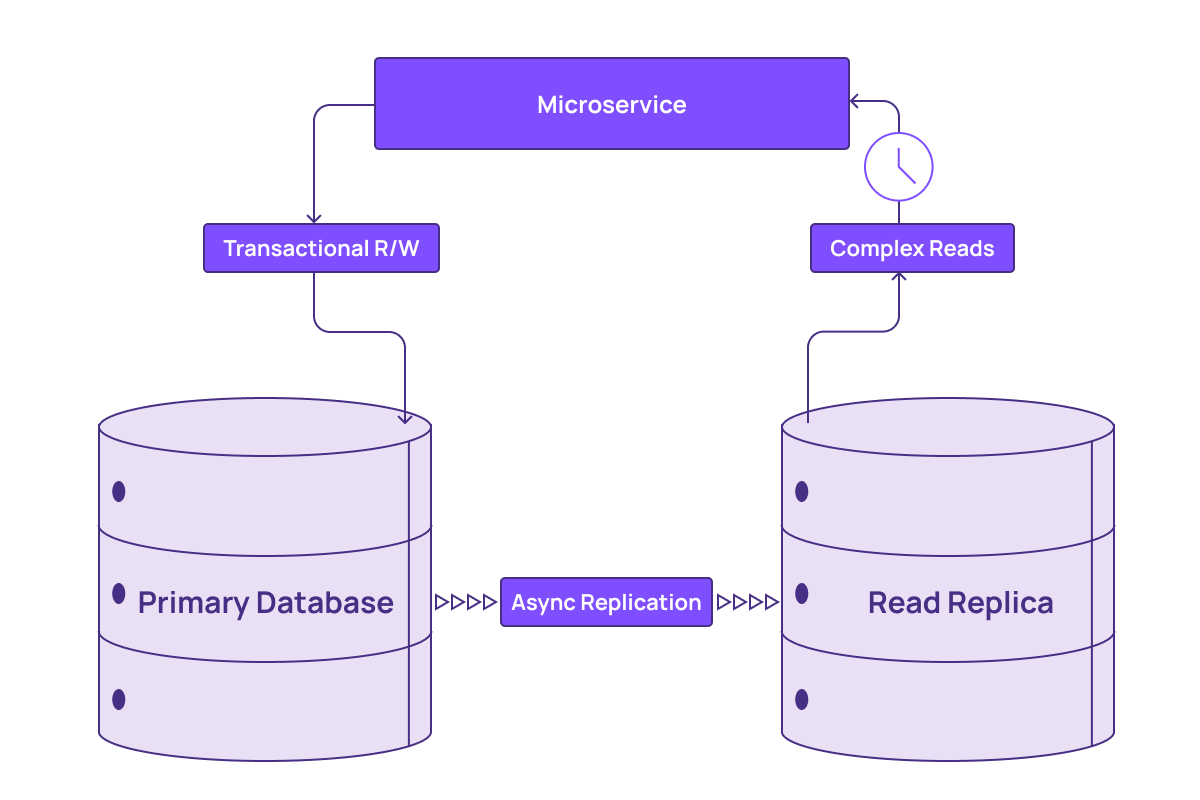
The other common solution is to make a copy, or read replica, of the database. This offloads the work from the original system, but comes at the cost of a small amount of replication lag, causing data staleness. In some cases, read replicas can also sacrifice consistency. Most importantly, read replicas are still not optimized for fast computation of complex queries.
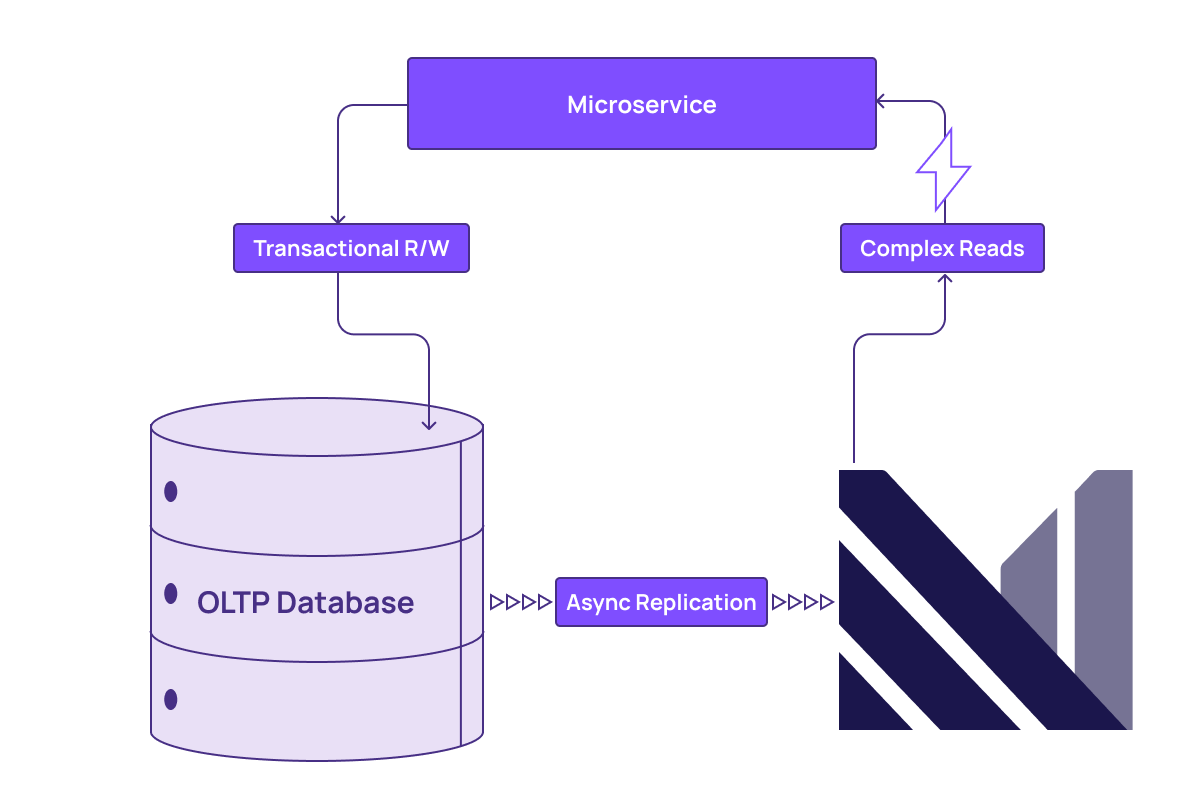
If performance (or price/performance) is still not suitable, other systems and processes outside of the database are introduced to offload, transform, and query the data. Each of these steps introduces overhead and increases the chance of trust-destroying bugs. This puts budgets, project timelines, and application stability at risk.
There is now a new way forward, unlocked by the discovery of Differential Dataflow. This building block enables teams to take in streams of data, process it using data flows created via standard SQL, and keep the results up to date as the inputs change. This process, called Incremental View Maintenance (IVM), ensures that materialized views are always up to date.
With Differential Dataflow, queries to incrementally maintained views return with fresh data almost instantly. This is because the computational cost now happens at write time rather than read time. Here’s the push-based model to SQL rather than the pull-based one. The effect is like having a cache that never has to be invalidated and can respond to queries using SQL. This minimizes the impact on the core database, enabling fast, fresh results without sacrificing performance.
Remove Data Silos by Joining Databases in Real Time with SQL
Relational databases provide important guarantees around indexes, queries, and transactions, all of which require that the data is managed by a single engine. Unfortunately, the reality in large organizations is messy. They can have hundreds or even thousands of databases that collectively power their business. In this section, we’ll see below how Differential Dataflow can help.
Database proliferation happens for a variety of reasons, including minimizing the blast radius of a database failure, delivering different performance characteristics for different workloads, and accommodating team preferences. Source data may also come from other systems of record like CRMs or even external web services. This means teams frequently face the challenge of joining multiple data sources stored in multiple silos to produce common views needed to run their business and take operational actions.
A standard approach here is to introduce a data lake and data warehouse to bring everything together into one place and make the useful parts queryable. However, any views created from this consolidated data set are primarily historical. Anything else would be cost prohibitive due to the computational power required to update these pipelines. This makes real-time analytics across data sets out of reach for most organizations.
Common scenarios involving multiple data sources include loan underwriting, fraud detection, and supply chain optimization. Some teams can’t accept the stale data that traditional pipelines push into a data warehouse.
To support these use cases without sacrificing the freshness requirements that make them valuable, data teams have historically faced a dilemma. They can either avoid joining data, resulting in incomplete results, or undertake the labor-intensive and error-prone process of joining the data they need. The latter approach means abandoning some of the expressiveness of SQL in favor of custom logic or stream processors, which require specialized expertise and introduce operational complexity.
When services need to query data further, the processed data is sent to a separate database designed for fast queries on joined and transformed data. This database is typically called an Operational Data Store (ODS). While using an ODS is much faster than waiting for the data to be available in a data warehouse, you are still dealing with time-consuming custom development work to get the data into the right shape to support operational queries across silos. Depending on your team's capabilities and environment, incorporating new data often means building new pipelines, which can take weeks or months to get into production.
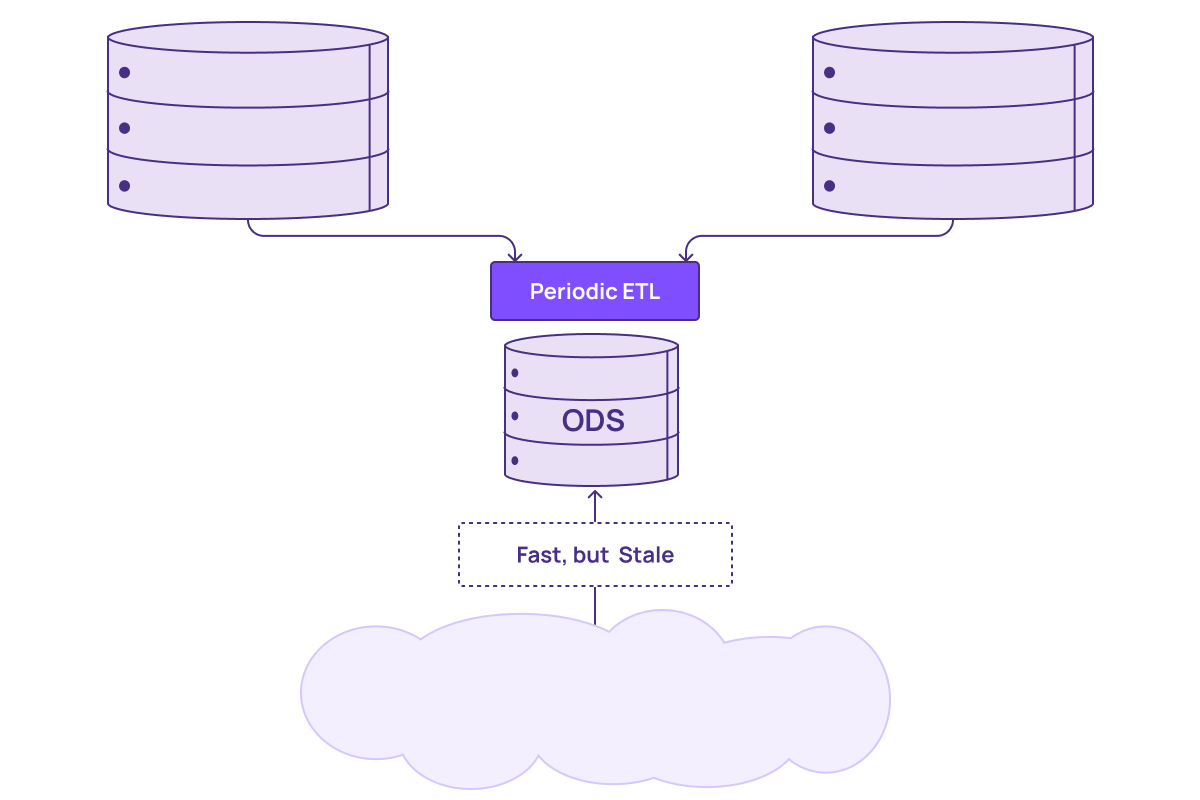
Incremental view maintenance enabled by the newly discovered element of Differential Dataflow creates a path to a radically better solution.
If you rebuild an operational data store from the ground up with Differential Dataflow at its core, you would now simply stream your data sources into the ODS, where each source would appear as a table. You could now create always up-to-date views of any combination of formerly siloed data sources in your architecture by just writing standard SQL. This can include joins, complex aggregations, and even recursive queries.
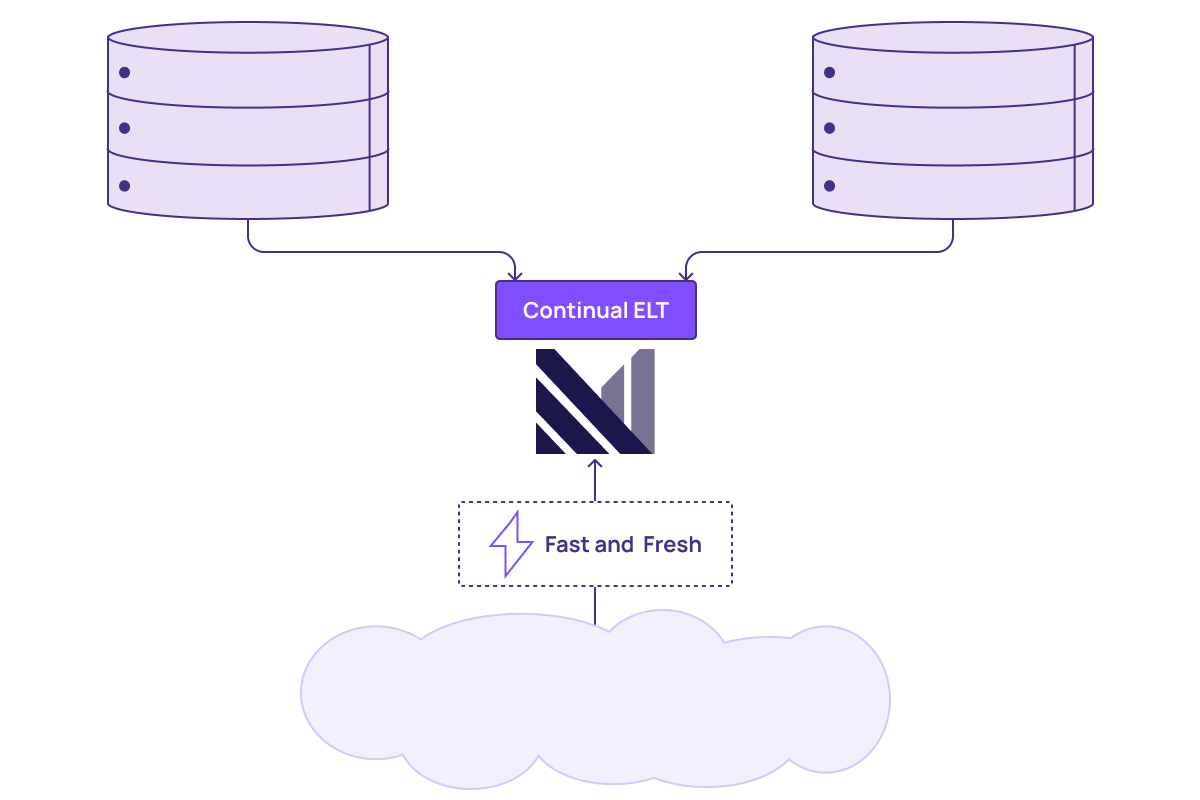
As the cloud brings down the cost of storage, this has started to shift the traditional extract-transform-load (ETL) paradigm into extract-load-transform (ELT). In this new world, to support the maintainability and flexibility of data, data teams can now directly import the raw data and define the transformations as intermediate tables that can be composed and defined in code. This is extremely powerful when applied to the ODS pattern. Now, the multiple steps data takes to go from the raw sources to the final tables exposed in the ODS can be defined in SQL, and every intermediate model or step would be always up to date.
For systems that combine Differential Dataflow with virtual time (another element discovered much earlier, in the 80s), this creates the powerful effect of ensuring any view composed from these sources would tie out with any other at all times. The entire pipeline, from source to intermediate views to final tables, “ticks” from consistent state to consistent state, preserving the transactions of upstream systems.
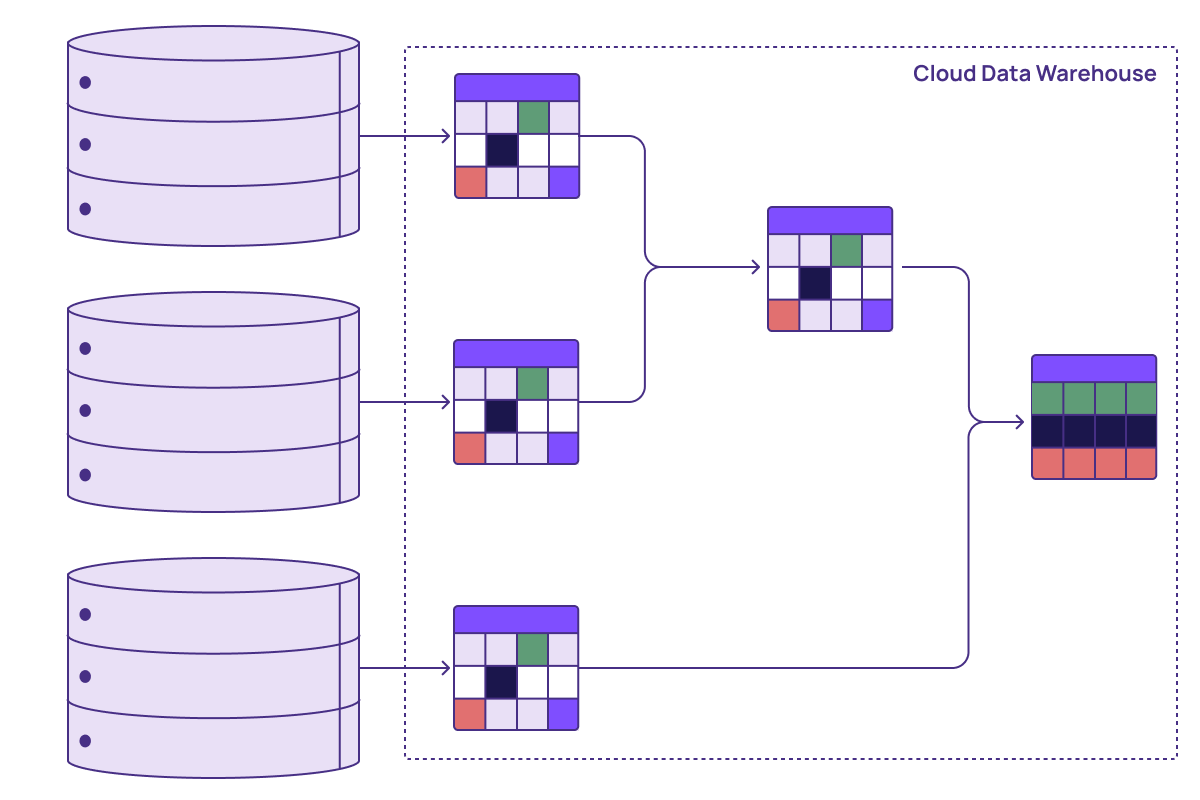
Before Differential Dataflow
After Differential Dataflow
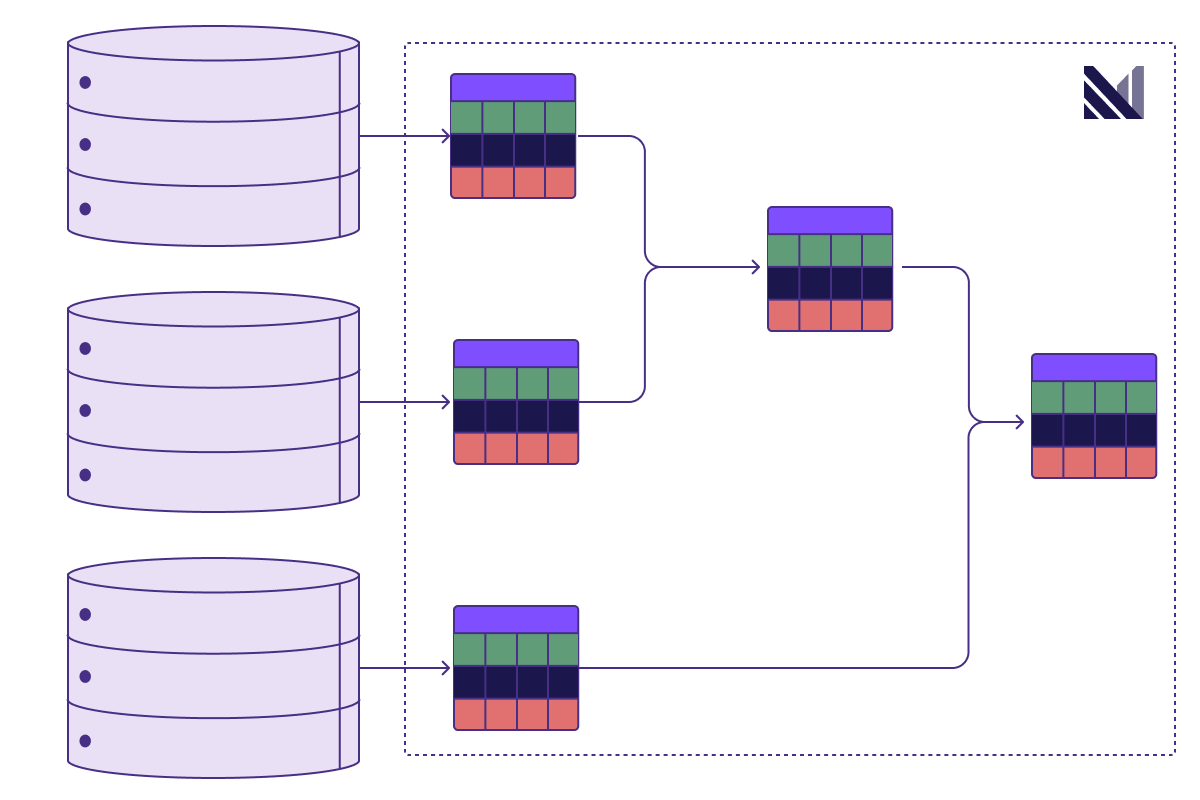
The result is fresh and consistent data. If a small number of rows are updated by any upstream system as part of a transaction, the resulting materialized views that are downstream of that transaction update as well. They do so without giving up consistency. Services running queries against this system can make decisions in the moment. Whether it is to take some corrective action in a manufacturing plant process, or reliably identify and mitigate fraud the moment it happens, the system responds in real-time.
Enable Team Autonomy and Scalability with an Operational Data Mesh
Finally, one more surprising benefit of our newly discovered element: Differential Dataflow can have a big impact on team design and coordination.
A common pattern in large or scaling organizations is to build teams that are loosely coupled but have shared context. This allows them to collectively align around and execute against organizational goals. The complementary architecture pattern for facilitating this is often the microservice. Microservices break applications down into smaller services that can be built, scaled, and improved independently by autonomous teams.
The problem with this pattern comes down to the data. Imagine a retailer that has a service for inventory management and a separate one for fulfillment. The fulfillment service needs to understand and modify the state of inventory. If this was in the same database, it would be trivial for the fulfillment team. They could just join in any data they needed.
However, if both services use the same database, they are no longer loosely coupled. Changes to the inventory database could break the fulfillment service, for example, by changing the table structure in a way that was incompatible with the fulfillment logic. This is why the best practice for microservices is for each team to have its own database.
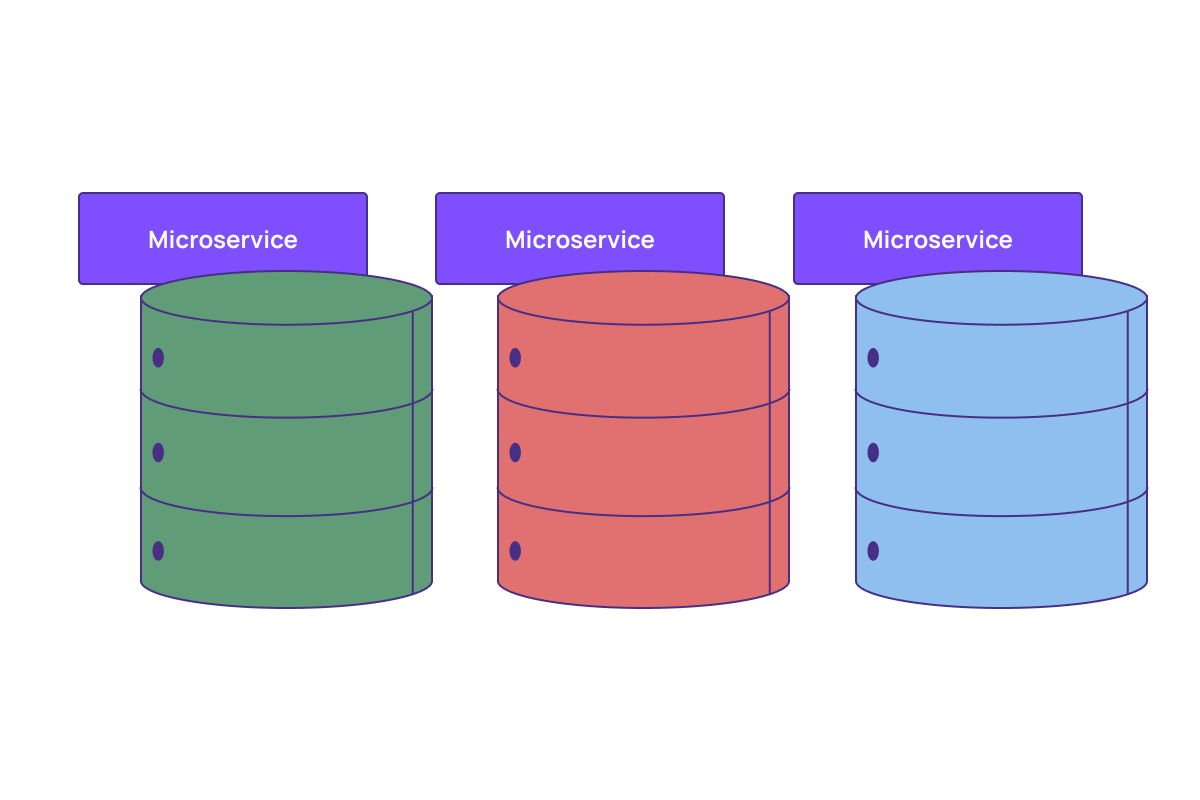
This principle of data ownership avoids tight dependencies but comes at the cost of creating data silos. We still need to figure out how to give teams access to each other's data. So, microservice teams produce stable interfaces outside of the database that other teams can rely on. This is often done via event-driven architectures where they publish changes that interested services can subscribe to and keep track of what they need to operate. This creates a pattern that looks like the following:
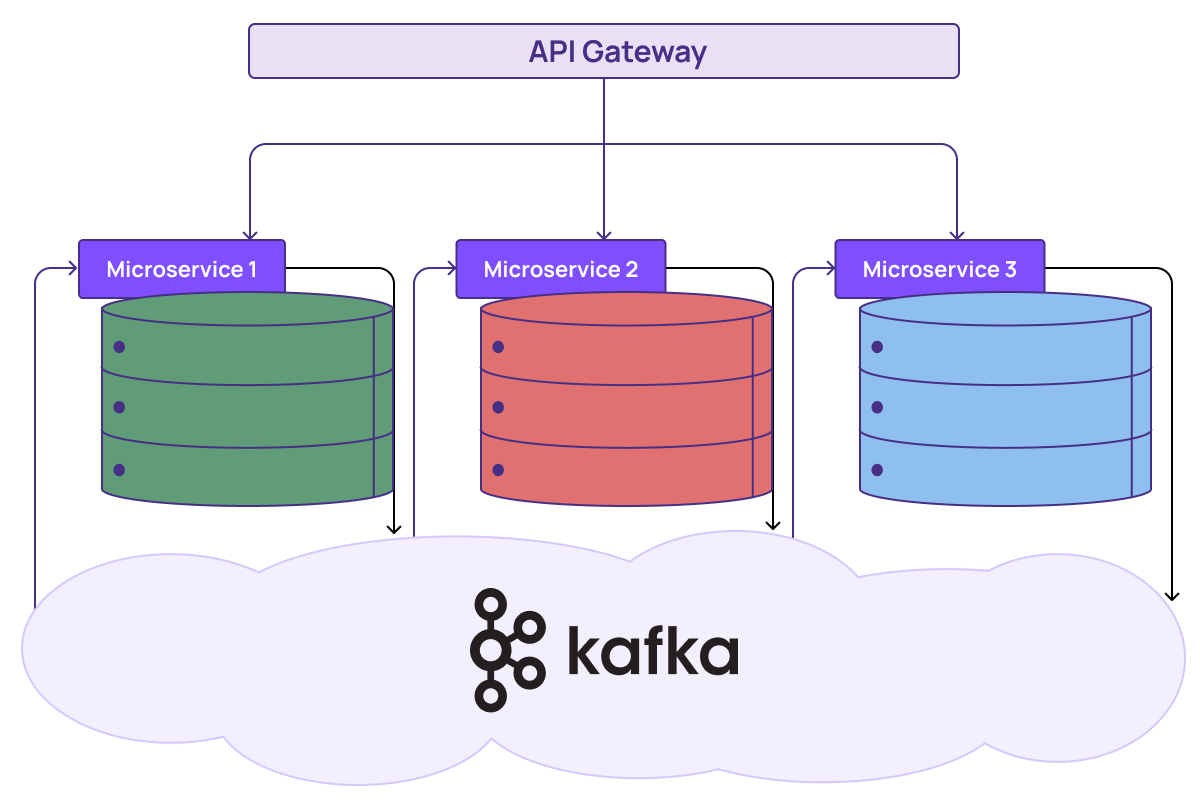
Now, each team listens for changes across services and reconstructs or materializes them into a view that represents the data that they care about. Each team also has to figure out how to keep their views up to date. The work required to pull data into a service and organize it in a way that supports the client's business logic can be labor-intensive, error-prone, and inflexible.
This is yet another example of time, energy, and labor being wasted due to the missing element of Differential Dataflow in the modern data stack. Let’s rethink how teams can operate now that they have the right primitive.
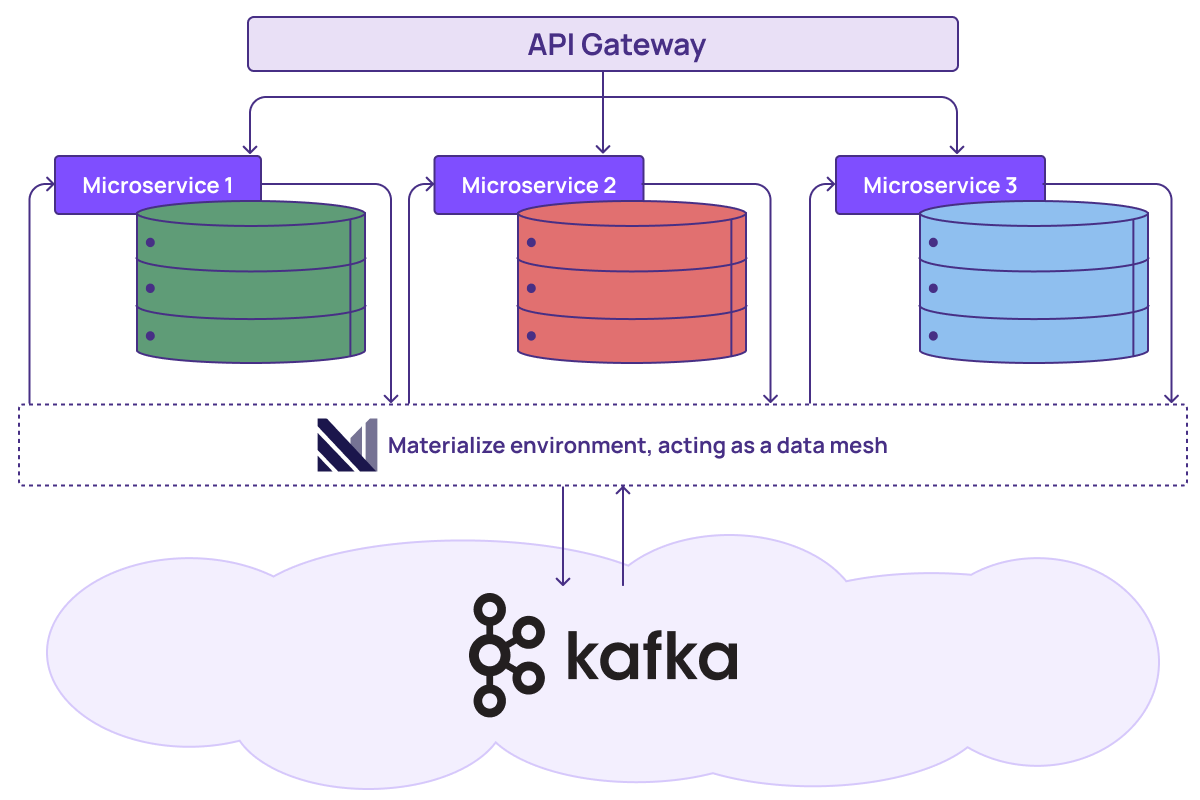
Now, each microservice can create incrementally maintained materialized views to not only pull in the data they need from any other service but join that data in real-time. This can be done consistently, thanks to virtual time (described earlier), by just using SQL. From the point of view of the service team, they have access to the exact database they need, and with fresh data. This experience is the same regardless of the way the data is originally represented across different services.
In this world, there is no need to spin up custom pipelines, build new data manipulation logic, or hire specialized talent with expertise in streaming infrastructure. Teams are now decoupled, agile, and can be highly productive, achieving the original promise of microservice architectures.
Finally, we can use incrementally maintained materialized views to support publishing data products rather than just consuming them. The last piece of the puzzle is the data API that data owners make available to their broader organization.
To support this, we will add a storage layer decoupled from compute, creating an architecture common in cloud data warehouses. Each team can now have one or more independently scalable clusters for publishing and incrementally updating materialized views. These views are themselves the data products. However, instead of posting changes to an event log like Kafka, these views are stored and updated economically in a shared cloud persistence layer, where they can be accessed by other teams.
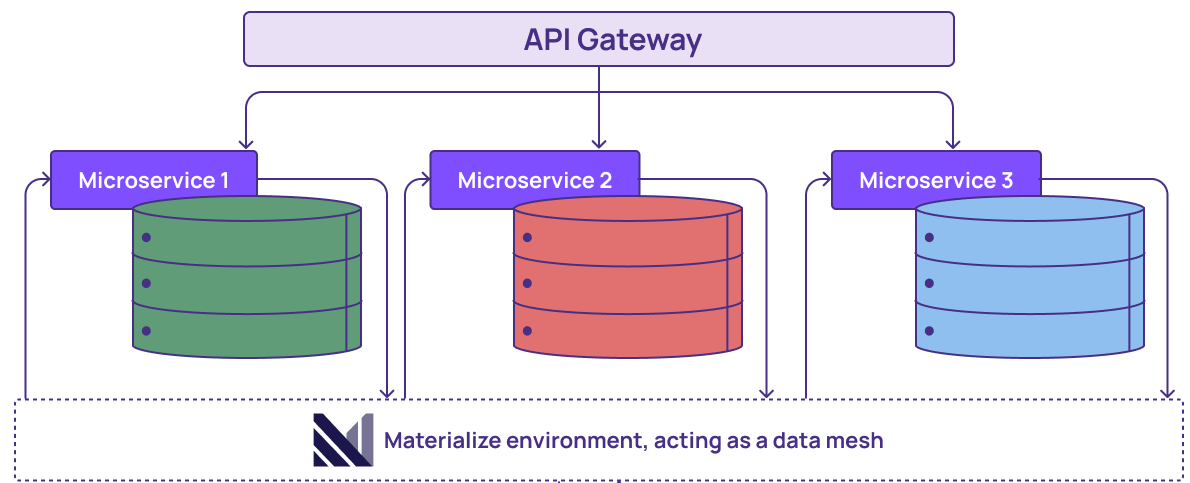
As we saw earlier, by using SQL to define their data products, teams can create views that can be composed, collectively describing the transformation steps from their internal database to the final product. As their core database changes, their final products will be kept up to date. They could even write tests in SQL that are evaluated continually. ELT becomes a powerful pattern for producing data products.
Now, teams can publish and access fresh data efficiently. This approach maintains autonomy while removing silos, providing a broader view of the business. These views can be accessed directly or composed into higher-level ones. In either case, every query ties out exactly with the source databases, no matter how many transforms were required to create the published data products or incorporate them into downstream services.
The result is an operational data mesh. In this setup, teams and the services they build can act on fast-changing data anywhere within their organization with minimal cost and maximum flexibility.
The Operational Data Store
The modern data stack, like Mendeleev’s table, improves as science advances and fills in the gaps. The new, but foundational building block, of Differential Dataflow enables fresh materialized views, silo-traversing cross database joins via a modern ODS, and an operational data mesh that helps teams coordinate without coupling.
You can now meet increasing customer demands, improve agility, and keep up with huge volumes of data, all with the team and the budgets you already have, enabling you to reach the full potential of your data strategy.
At Materialize, we are making all of this possible by harnessing Differential Dataflow to its fullest extent. We call our solution the Operational Data Store. You can learn more at https://materialize.com/.
