
We noticed a theme with Materialize users: Many were bringing over workloads that were initially prototyped on cloud data warehouses. So we dove deep on the rationale and the outcomes with a set of data engineers, some of whom created value and reduced cost for their business by moving a workload from warehouse to Materialize, and some of whom ultimately decided that a warehouse was a better fit. What follows is the result: A set of signals that indicate when moving a workload from a warehouse to Materialize is going to unlock new capabilities, add value or reduce cost.
important
If you have a warehouse workload that needs to be faster, cheaper or less resource-intensive, get in touch, and we’d be happy to talk through whether Materialize would fit your specific requirements.
Why does work start in a warehouse?
Over-use is the hallmark of a great technology: When a tool gives you superpowers it’s natural to use it for every new initiative. For Data Teams, warehouses (and the surrounding tooling) deliver superpowers by:
- Making it easy to collect and cheaply store raw data (thanks to commoditized ELT via services like Fivetran and cheap object storage layer)
- Allowing multiple teams to work with the same data independently, all in SQL (thanks to on-demand compute separated from storage.)
- Bringing SDLC workflows to data (with tooling like dbt teams can test and stage changes, version control SQL in git repos, and collaborate on work using the same battle-tested processes established in the software development lifecycle.)
On top of that, the alternative to centralizing on a warehouse looks increasingly like a tangled web of spaghetti code, microservices, and point-and-click integration apps that are a nightmare for quality-control, security and compliance.
All this makes the warehouse a great place to prototype new work: data is available, all that is needed is a new SQL model. But going to production with the new wave of operational workloads on the warehouse can lead to high costs from hammering the compute layer with frequent transformations and queries, even dead ends with hard limits on data freshness.
You can be looking at a table of exactly the data you need in exactly the shape you need it, with no possible path to “wiring it up” to a production-ready solution.
This happens often enough that an ecosystem of tools and techniques now exists to shore up the structural weakness of the warehouse when it comes to serving these new workloads:
- Incremental Models - dbt helps speed up transformations and works around the warehouse’s inability to handle incremental materialization by offloading the work to data engineers, in complex SQL code. More on this below.
- Caching and Serving Layers - A new generation of tools like Cube.dev add advanced caching and serving layers downstream of the warehouse.
- Reverse ETL - Hightouch has done the work to wire up syncs of warehouse data to third-party systems.
But, for new use-cases that need fresh data, the impact of all this innovation is limited by the outmoded engine at the core.
Why move certain work to Materialize?
Materialize takes the same strengths: (1) ELT of streaming data with cheap scalable object storage, (2) On-demand scaling with compute isolation, (3) Compatibility with SDLC workflows, all managed via the same SQL control layer.

But it changes the constraints by swapping in an engine that delivers real materialized views: continuously updated SQL views via incremental computation.
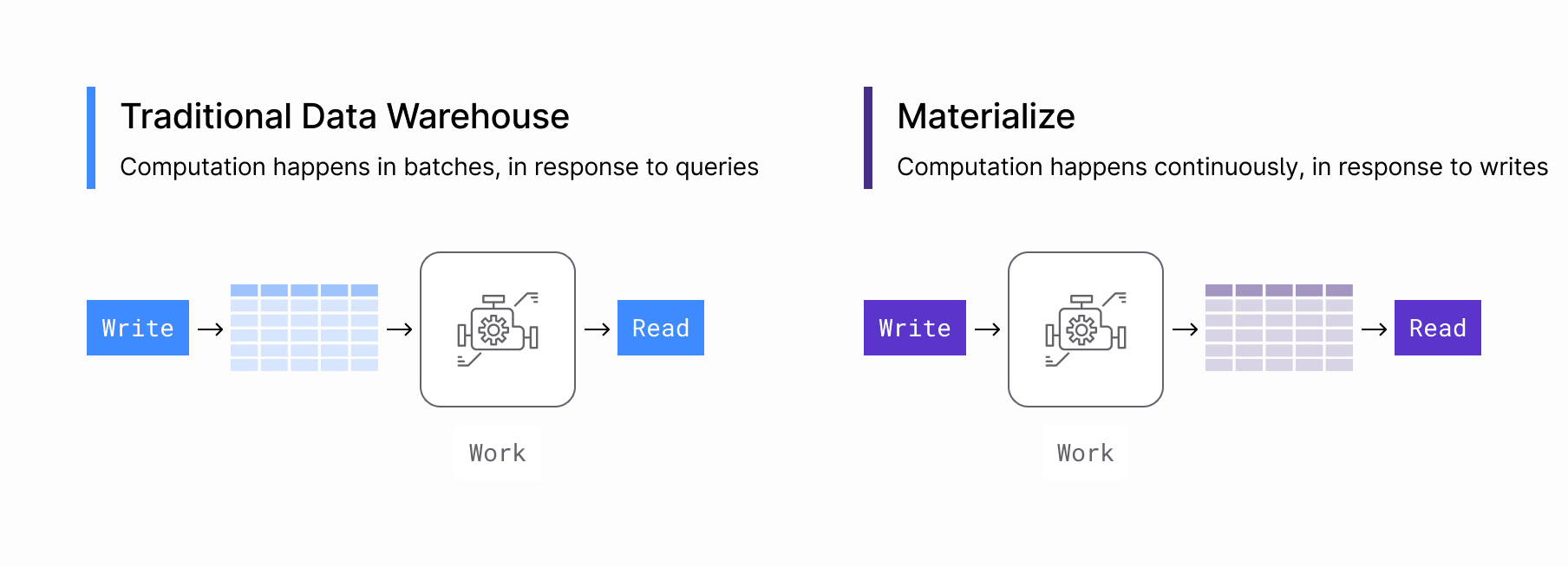
Materialize also adds a serving layer that embraces high-frequency reads and even proactively pushes updates along to downstream systems.
With these architectural changes, moving certain operational workloads from warehouse to Materialize can drive a major improvement in:
- Capabilities - data freshness measured in seconds means use cases that were non-starters on warehouses are now possible.
- Business Value - increasing data acts as a value multiplier on many use cases.
- Cost Efficiency - due to the increase in efficiency of the incremental model.
It bears mention that similar gains could, in theory, be achieved by switching to a stream processor, but at a steep engineering cost of staffing a team and developing what is effectively your own streaming database.
None of the indicators below are absolute, but as a whole they should provide a helpful framework to use when deciding whether a particular workload is better fit for Materialize vs a Traditional Data Warehouse.
Business Requirements
To evaluate whether a warehouse workload is well-suited to Materialize, start with the underlying business requirements: what is the service or capability that it needs to deliver?
🟢 Move to Materialize
1. Does the use case benefit from fresher data?
Fresher data means less time between when the data first originates and when it is incorporated in the results of SQL transformations in the warehouse.
A need for fresher data can manifest in hard latency budgets or thresholds, above which the use case is not feasible:

Example: Transactional emails must be sent within a minute of customer action, a 30-minute delay would cause confusion, frustration.
Or data freshness can act as a value multiplier, where the value of data goes up as lag decreases:

Example: Fraud detection that operates on data 30 minutes out-of-date is possible, but not as valuable as fraud detection that operates on data accurate up to 1 second ago.
Examples of business use cases that benefit from fresher data:
- Operational Dashboards - A decrease in lag on dashboards that internal teams reference to operate the business creates value in the form of shorter time-to-resolution on key processes. For example: Materialize customers run operational dashboards that power order fulfillment, support and success escalations, and monitor key performance metrics where changes may require immediate action.
- Feature-Serving / Personalization / Dynamic Pricing - All of these processes take a package of data and make a customer-facing decision based on it. The key commonality between them is that accuracy, relevancy and value go up exponentially as freshness increases.
tip
Customer Example: Superscript prototyped a feature-serving workload in the warehouse operating on behavioral data, but recognized the value was greatly limited by the up-to 24hr lag in data.

Moving it to Materialize brought the lag down to 2-5 seconds, greatly increasing the accuracy of the models:

Their Head of Data, Tom Cooper, can attribute a measurable increase in revenue to the move: “Every week, we’re closing customers that we wouldn’t even have had the opportunity to contact before using Materialize.” You can read more on their experience here.
- Data Automation and Workflow APIs - If you’re referencing data in the warehouse for automation and workflows elsewhere, how are you ensuring that you aren’t incorrectly acting on out-of-date information?
- Reverse ETL - If you’re syncing data to third party systems, many of them will become more valuable or open up new capabilities if the data is fresher.
- User-Facing Analytics - Drive engagement and value for users with instant gratification in the form of analytics that respond to action in real-time.
tip
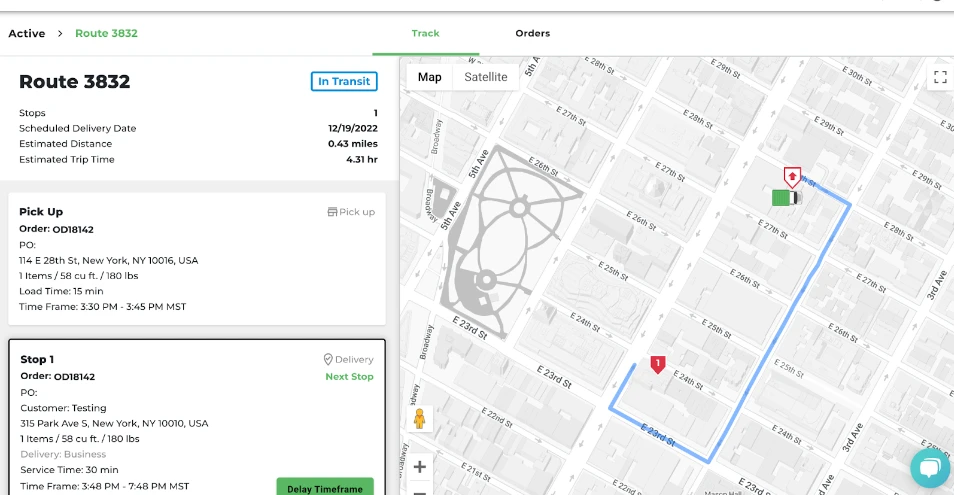
Customer Example: White-glove delivery marketplace Onward uses Materialize to power their real-time delivery tracking UI.
- Warehouse-centric SaaS - A new wave of cloud SaaS, including Product Analytics, CRMs, Security tools, all become more capable and valuable as the warehouse data they reference gets fresher.
- Internal Data Alerting - If you’re using tools or your own SQL to alert on data in your warehouse, switching to a push-based system like Materialize can drive increased efficiency and lower time-to-discovery and resolution. See Real-time data quality tests as an example.
2. Is the use case well-served by a push-based system?
This is a new capability in Materialize with no analog in warehouses, so it needs some explanation:
Because it uses dataflows to update results for each individual change to source data, Materialize is the only warehouse that can efficiently push updates out (via SINKs). This means it can be wired up to take action on behalf of the user exactly when it needs to.
If you take a step back and look at your larger business use case and you are doing something like polling a view in your warehouse, or running an evaluation at a set interval, you might actually be better-served switching to a push based model, like this:
- Stream data in continuously via SOURCEs
- Define your “alert” or “trigger” criteria in the form of a SQL view.
- Materialize runs the source data (and all future changes to it) through dataflows to incrementally update results of your view.
- As the results of your view change, Materialize writes the change out immediately to a downstream system.
Today, changes can be written to Kafka, but we are also evaluating support for writing changes to other destinations like Datadog and general HTTP endpoints, opening up an even broader and simpler set of push use-cases.
🛑 Keep in the Warehouse
The warehouse remains a great fit for the many use-cases that don’t benefit from fresher data. Also, use cases that demand access to the entire history of a dataset and cases where the questions asked of the data are exploratory in nature are better-suited for the warehouse.
Examples of Business Use cases that are better-suited for Warehouse:
- Month-End Close Reporting - There is no benefit to real-time data in monthly reports!
- Ad-Hoc/Exploratory Analysis - The kinds of work that analytics engineers and data scientists do via iterative unique SQL queries across a deep history of data often benefit from using a static, unchanging dataset, which will always be better-served by a warehouse. Materialize can serve ad-hoc queries, but it will be slower than a system built for this purpose.
Technical Requirements
Keep in mind that the signals below should be evaluated in tandem with the business requirements above.
🟢 Move to Materialize
1. Warehouse compute is always on, running a predictable workload
Predictable workloads are orchestrated or scheduled work like loading data in and running SQL transformation (the kind of work that’s often handled by dbt run or airflow, vs the kind initiated by end-users). Constantly running a traditional data warehouse for scheduled jobs is like paying an Uber driver for 8 hours a day, when you really just need a rental car. Often this happens when you’re running a batch load and transformation workload hourly or more in a traditional data warehouse.
Why move? Presumably, you’re running something often because there is value in fresher data. Unless you are using very advanced dbt incremental models, you are probably doing a significant amount of inefficient recomputation of data that hasn’t changed since you last ran the query. Materialize can deliver efficiency and cost savings by maintaining the same query incrementally. Materialize only needs to compute the data that changes.
2. Running into limits or complexity with dbt incremental materializations
Related to the point above, one optimization path that heavy warehouse users take is to convert their table materializations to incremental materializations. On first glance, this may seem like a good long-term solution, but experienced users, and even dbt themselves, have a lot to say about the limitations of incremental models. If you’re unfamiliar, the issue is that incremental models offload to the user the responsibility of tracking which data can possibly change, and which data is truly append-only. This not only applies at time of creation, but it continues to be a responsibility going forward, as schema evolves.
Why move? Not all incremental materializations will magically work better in Materialize. If the scale of the dataset is very large, Materialize may run into limits of its own. But porting an incremental model in a traditional warehouse to a regular materialized view in Materialize equates to handing responsibility for tracking what inputs might change back to the database, saving a data team lots of time in debugging and maintenance.
3. Data is slowed down before the Warehouse
Look at the sources of data you are using in the warehouse. Are you using a service to queue up a stream of continuous updates into a batch of changes that is better suited to load into the warehouse? This is a good signal that Materialize can deliver a drop-in capability upgrade by processing the data as it arrives and serving transformed results that are always up-to-date.
Examples:
Kafka / Snowpipe - If you are using a service like Snowpipe to consume a stream of data in Kafka, stage it on S3, and load it into Snowflake,
 you may be able to gain performance (fresher data), decrease costs (no separate loading service, less repetitive computation work in the compute layer) and simplify your architecture (Materialize directly consumes from Kafka) by switching the workload to Materialize.
you may be able to gain performance (fresher data), decrease costs (no separate loading service, less repetitive computation work in the compute layer) and simplify your architecture (Materialize directly consumes from Kafka) by switching the workload to Materialize. 
CDC Streams - If you’re taking a change data capture stream from your primary transactional database and routing it to your warehouse, you’re likely either managing it yourself in Kafka (see above) or paying someone else to manage Kafka and slow down the changes to batch load into the warehouse. Either way, change data capture is worth calling out because it is ideally-suited to Materialize: CDC data is highly relational and Materialize excels at handling complex SQL joins in real-time.
Analytics Events - Analytics events coming from web, mobile and server-side sources via services like Segment, Snowplow, and Rudderstack are real-time and streaming by design, but these services have added architecture to build up a cache of events and batch load them into warehouses, typically at a one to twelve hour frequency. Materialize can be wired up to process these events in real-time.

Here is an example demonstrating how to send Segment events to Materialize in real-time. Customers like Superscript are successfully using this approach to deliver valuable data automation in production.
🛑 Keep in the Warehouse
- Slow/Batch Data - If the data you are working with is only available in batch, or not available at a high frequency, the benefits of a continuous incremental compute engine are negated. For Example: A company that processes billing records from infrastructure providers like AWS/Azure/GCP to generate dashboards and insights is better served by a traditional OLAP database, because new data is only generated and made available by the upstream providers every 24hrs.
- Very Large Datasets - The most common types of very large dataset we see that are better-suited to warehouses are (1) Long history of SCD Type 2 data (i.e. tracking the change history of a users table over multiple years) and (2) High-volume append-only clickstream data where the entire history is used in queries. There are no magic beans in databases. Materialize is purpose-built to provide the “current state” with as low latency as possible. To do this, it trades off the ability to quickly answer queries that need to scan billions of rows of static data.
note
Many users work with append-only data like clickstream events in Materialize, the key to their success is setting bounded time windows (e.g. “Last 90 days”) for analysis.
Wrap-Up
Materialize is purpose-built to handle a new class of workload that is often initially prototyped on a cloud data warehouse. The same properties that make it so convenient to start in a warehouse also apply to Materialize: separation of storage and compute, the ubiquity and usability of the ELT approach, and the ability to leverage SDLC workflows to manage everything. The key difference is the incremental engine in the compute layer in Materialize.
This architectural difference changes the capabilities of the system, making Materialize ideally-suited to new use cases that rely on fresher data, increased automation, and more operational workloads.

