When to Use Indexes and Materialized Views

tip
Materialize is an operational data store used by teams to serve continually-updated data transformations using the same SQL workflows used with batch processing. To see if it works for your use-case, register for access here.
Understanding how to use materialized views and indexes is important for designing data-intensive applications with any database, including Materialize. In this post, we will see how knowing a bit about Materialize's architecture will help you leverage indexes and materialized views to optimize the performance of your queries.
Broad Definitions
Here are some definitions that roughly capture how the words are used in traditional databases.
View
A view is simply a convenient name for a SQL query that you can reference in other queries. No computation happens when you create a view.
Materialized View
A materialized view precomputes the results of a query and stores those results for fast read access. Computation happens when you create a materialized view.
Index
An index is a data structure that allows the database to find and retrieve specific rows much faster than it could do otherwise. Computation happens when you create an index.
What Happens in Materialize
Here are some key characteristics about Materialize that play into how you should think about indexes and materialized views:
- Updates results eagerly and incrementally as new data streams into the system.
- Shares indexes across queries, which means your use cases can scale according to the number of input collections, not the number of output views
- Scales storage and compute independently -- durable cloud object storage for the persistence layer and clusters for the compute layer.
With these in mind, here is how views, materialized views, and indexes work together:
note
Each ad-hoc SELECT ... FROM my_view query on a view will ingest all the input data, return the result, and then throw the results away. The magic of incremental computation doesn't happen automatically when you create my_view, so don't forget to create an index on it!
A Sample Deployment
Here is a Materialize deployment from a real customer that uses clusters, materialized views, and indexes in a clever way to serve their access patterns.
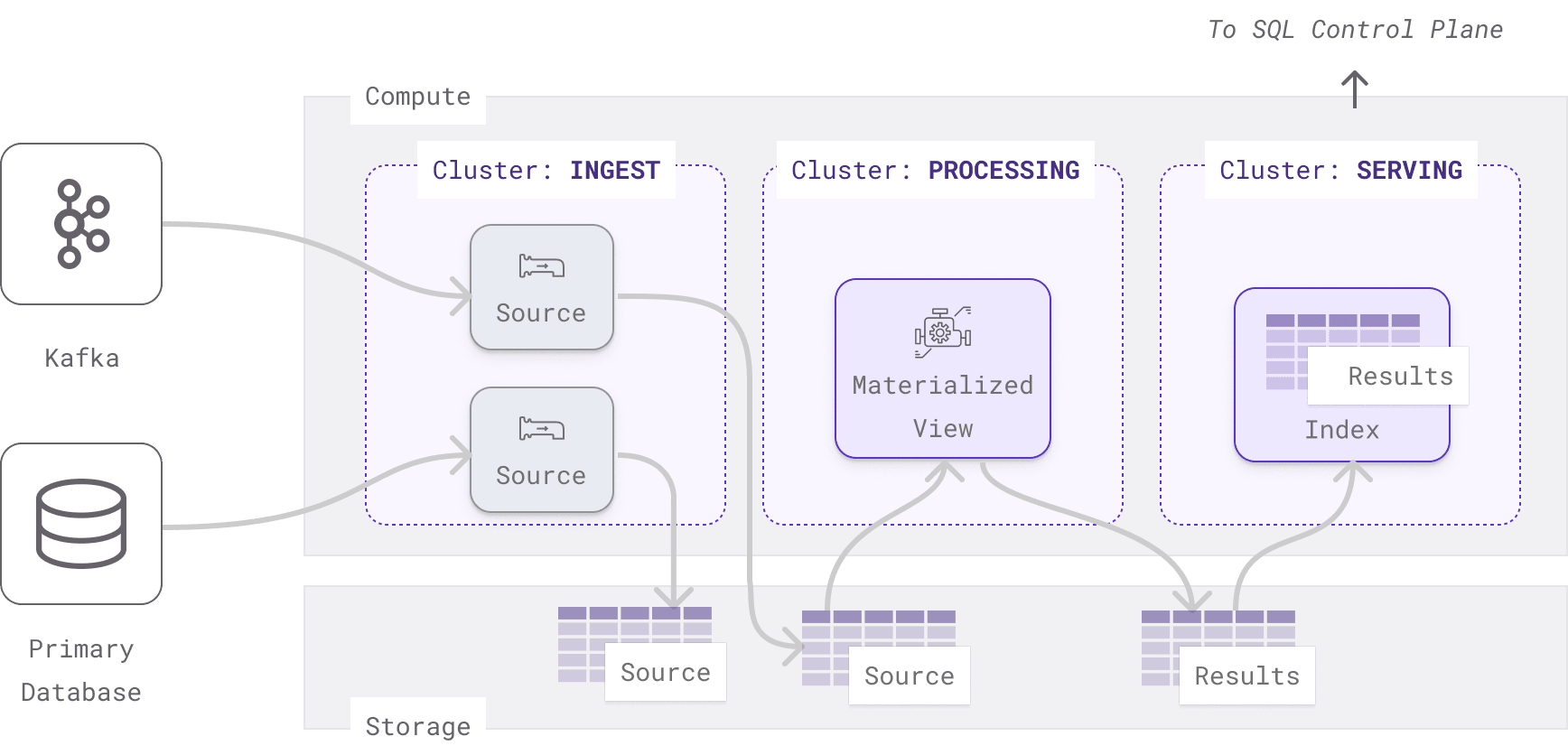
They have three clusters:
- A ingest cluster handles streaming data sources.
- A processing cluster processes incoming data using materialized views so the results are persisted to storage.
- A serving cluster uses indexes to load results from storage into memory to serve point lookups.
Benefits:
- If the processing cluster fails due to hardware malfunction or bad data, the serving cluster can continue to serve (stale) results.
- If the serving cluster fails, it can quickly come back online without having to reprocess the inputs. All the results are already computed in the processing cluster. The indexes just have to load the results into memory from storage again.
Tradeoffs:
It is possible to process the data and serve the results in one cluster rather than two by creating a view along with an index. Doing so would lose the fault tolerant benefits, but result in:
- Less storage cost because results aren't persisted.
- Less compute cost running only one cluster.
- Slightly less latency, since it avoids a round trip to storage.
Conclusion
Materialize uses views, materialized views, and indexes much like other databases, but knowing how the system works with memory and storage can help you optimize your deployment. Here are some quick rules of thumb for indexes and materialized views.
Index:
- Faster sequential access.
- Fast random access for queries selecting individual keys.
- Can be consumed by views and queries executed on the same cluster.
- Reads are served from memory.
- Use this if you are querying Materialize directly from a Postgres client application.
- Use this on columns of collections that frequently appear in equality predicates in your queries.
Materialized View:
- Results persisted to storage.
- Results can be consumed by views and queries executed on any cluster.
- Reads are served from object storage.
For more optimization tips (especially for joins), check out our optimization documentation!
