Data Freshness: Why It Matters and How to Deliver It
February 23, 2024

Real-time systems such as fraud detection, personalized shopping recommendations, and instant notifications require fresh data to operate effectively.
For example, it’s not useful to flag fraud several hours after it’s occurred. By then, the fraudster has already escaped with someone’s money.
But building the real-time systems our world runs on is difficult. These systems require streaming data — an uninterrupted flow of data, rather than scheduled data updates. However, most traditional databases do not leverage streaming data, but rather batched data that’s updated intermittently.
Furthermore, real-time systems rely on operational data, or up-to-date data that powers time-sensitive business processes. To produce this operational data, queries must run continuously, which drives up compute costs for traditional data warehouses.
As more teams turn to data warehouses for real-time use cases, the need to marry fresh data with cost-effective compute has grown more pressing.
In this blog, we’ll give a full overview of data freshness, including the benefits, solutions, and costs. We’ll also discuss how companies harness operational data warehouses to operationalize fresh data.
What is Data Freshness?
Typically, data freshness measures the time between when data is created in a source system, and when it is used in a data product.
Data freshness can enhance most data products, including analytics and BI dashboards. However, data freshness is more important for real-time use cases, such as fraud detection and live notifications.
Built for operational use cases, Materialize ensures data freshness. In Materialize, data freshness is the time between data origination in upstream sources, and when users gain access to transformed data.
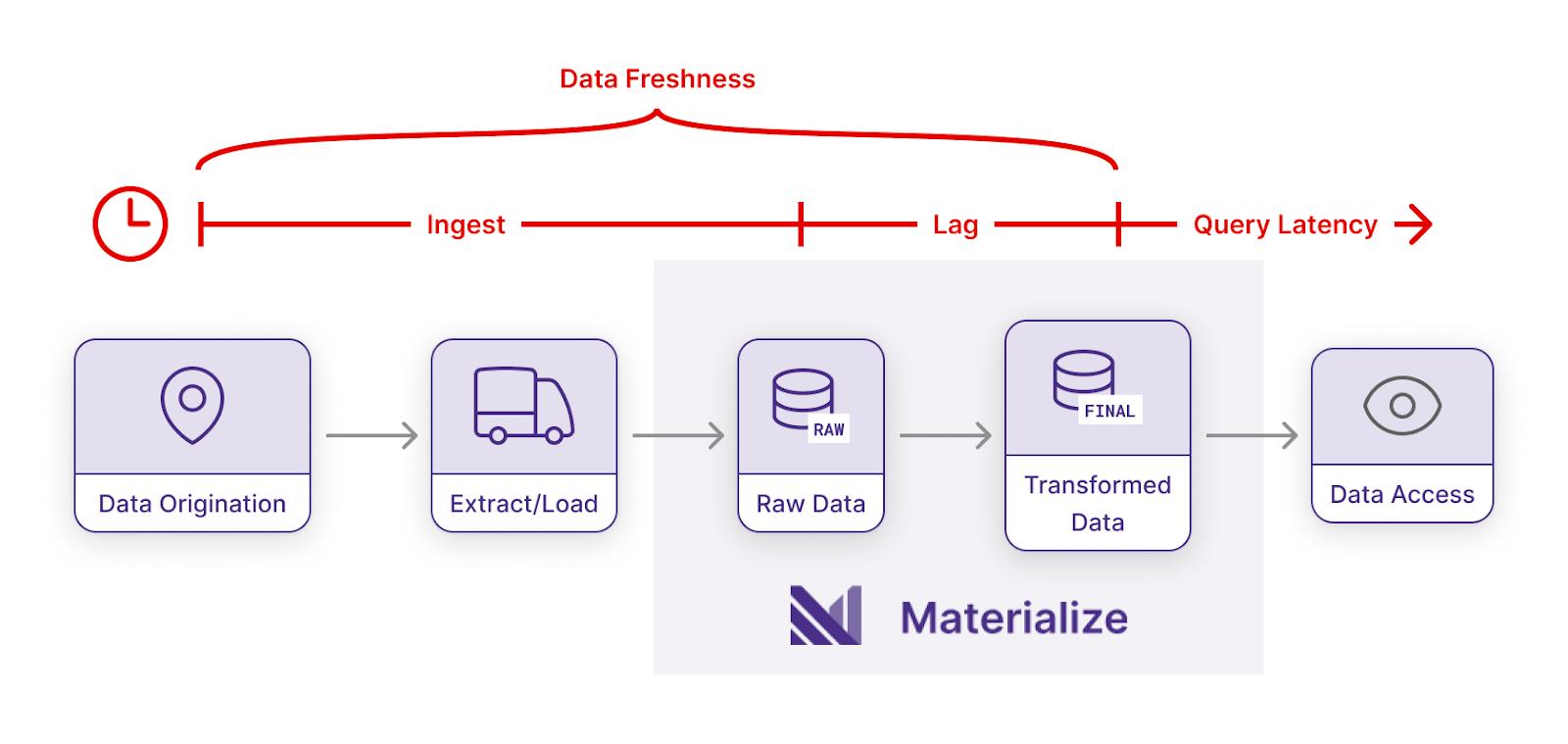
Materialize pairs streaming data with continuous data transformation. This enables Materialize to produce operational data for real-time use cases, such as financial modeling and inventory notifications.
In Materialize, data freshness is also tied to query frequency. Materialize incrementally updates materialized views to reduce query costs significantly, enabling data freshness while reducing compute expenses. You’ll hear more on this in a bit!
Let’s dive deeper into operational data to understand why data freshness is so vital for these use cases.
Why Freshness Matters: Operational Data vs. Analytical Data
Operational data powers time-sensitive business operations. This kind of data is used to enable business processes across an organization. Operational data can notify foreman of machine failures, recommend margin calls, and reveal abnormal account activity in real-time.
Data freshness is essential for operational data, since it fuels crucial business processes. These processes require fresh data to operate effectively, accurately, and safely.
On the other hand, analytical data is used to study historical trends and events, such as sales performance and customer retention over time. Up-to-the-second data isn’t necessary, unlike for operational workflows.
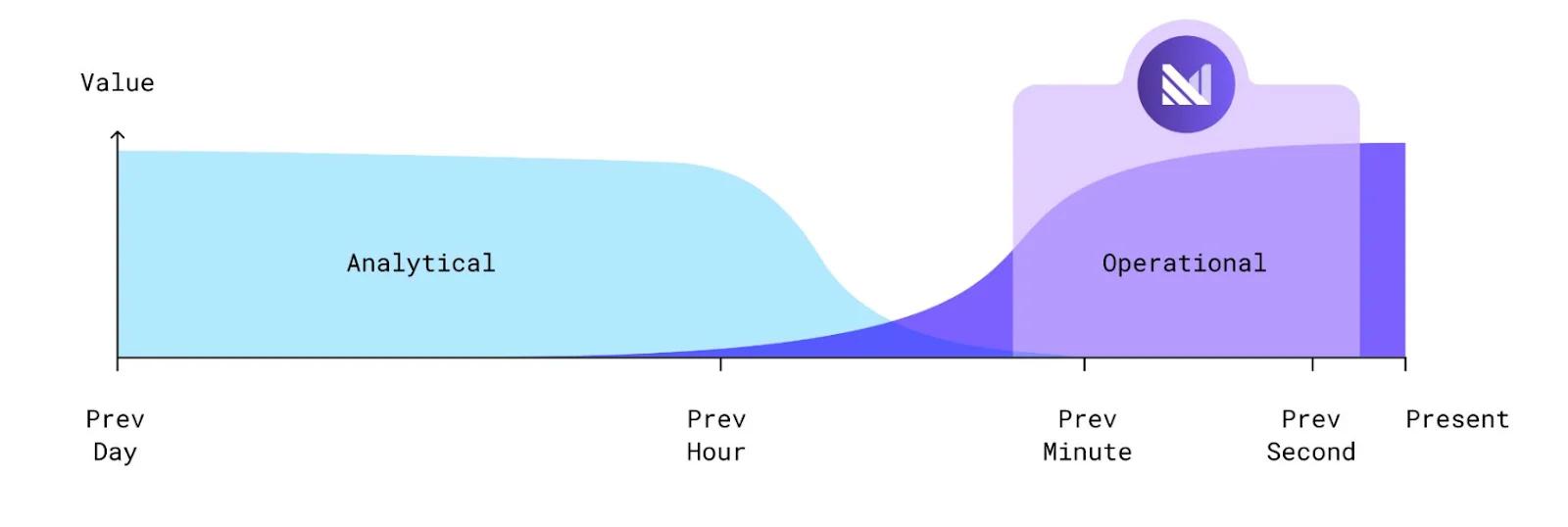
Traditional data warehouses — also known as ‘analytical’ data warehouses — are designed for historical data analysis. Data ingestion and SQL queries run at specific intervals, rather than continuously. This is why analytical data warehouses are undesirable for operational use cases, such as personalization, business automation, and AI/ML feature-serving.
For real-time business processes, an operational data warehouse (ODW) is the solution. With ODWs, you can combine fresh data and continuous data transformation to perform operational use cases.
Operational Data Warehouse: Fresh Data + Continuous Data Transformation
Delivering fresh data is one of the core capabilities of an operational data warehouse. ODWs combine streaming, real-time data with continuous data transformation to power essential business operations.
From dynamic pricing, to financial modeling, to customer-facing apps, operational data warehouses enable the mission-critical workflows that businesses rely on. Here’s how ODWs power these use cases.
Streaming Data
Operational data warehouses leverage streaming data to operationalize vital business workflows. By harnessing real-time data, ODWs process data in a continuous, incremental way, as opposed to in scheduled batches.
With operational data warehouses, data freshness is made possible by mechanisms such as change data capture (CDC). Change data capture tracks and captures data changes in a database and delivers those changes to downstream systems.
Operational data warehouses can enable change data capture by directly replicating data out of an upstream OLTP database. They can also harness messaging systems such as Kafka for CDC. Ideally, the method used for CDC does not alter your data architecture or require you to adopt new tech.
With this up-to-the-second data, you can transform fresh data into business inputs for your operational workflows.
Continuous Data Transformation
To power real-time use cases, operational data warehouses must continuously transform streams of raw data into actionable inputs. But most streaming data services do not offer SQL support. On the other hand, traditional data warehouses do support SQL, but are optimized for querying historical data.
With Materialize, you can harness SQL support to interact with streaming data. Materialize’s SQL support addresses the shortcomings of previous streaming solutions. Materialize offers the best of both worlds: SQL plus streaming data. You can execute SQL queries on fresh data continuously. Now you can constantly feed actionable data into your business processes, so you can power real-time, customer-facing applications and services.
Incrementally Maintained Views
For analytical data warehouses, executing SQL queries this often will drive up compute costs considerably. Besides the technical limitations, cost is one of the key reasons teams do not pursue operational use cases.
Materialize is designed to avoid this kind of constant query recomputation. Instead, Materialize leverages incrementally maintained views to decouple the cost of compute and data freshness. Materialize uses materialized views and indexes to provide up-to-date query outputs at a fraction of the cost.
Materialized views refresh and store the results of a query, so you don’t need to recompute the query constantly. See the example below.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
This stores the result of the query (the code after SELECT), so the query isn’t constantly re-computed. Other code statements can reference user_purchase_summary to harness the query’s output. The materialized view saves compute resources, and ultimately, money.
However, if the query’s underlying data is updated, the materialized view becomes outdated. The materialized view offers a query output, but it is based on outdated data. This is a problem of data freshness.
Materialize solves this data freshness conundrum by incrementally updating materialized views and indexes.
Instead of re-running the query, Materialize only updates the data that has changed. This ensures the query output is correct, while keeping costs down considerably, by requiring less compute resources.
The Cost of Data Freshness
Traditional data warehouses use pay-per-query pricing. This is fine for analytical and historical analysis, but not so much for operational use cases that require constant query execution. Minimizing costs becomes a complex engineering task.
But an operational data warehouse like Materialize maintains constant compute resources. In this pricing model, you rent time on an active computer rather than paying per computation.
For operational use cases that require constant query execution, this leads to significant savings. However, always-on compute resources don’t make sense for jobs that are run infrequently, such as daily analytical workflows.
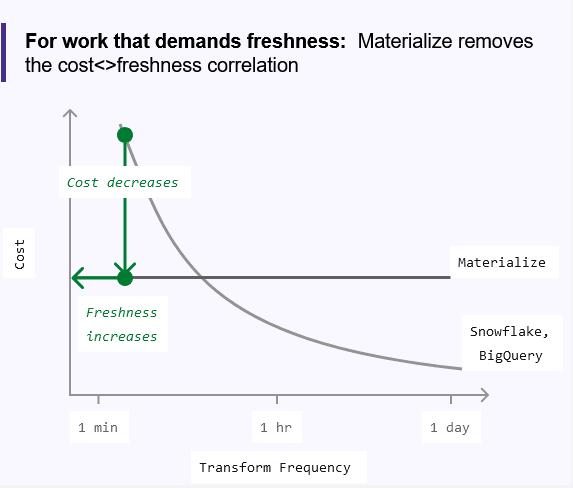
Therefore, traditional data warehouses offer pricing models that link cost to data freshness. More specifically, cost is tied to transformation frequency, or how often you execute queries. When analytical workflows are updated daily, this model makes sense.
But with the rise of operational use cases, the cost of maintaining data freshness on analytical data warehouses is cost-prohibitive. Queries in operational use cases are executed continuously, in a matter of seconds. This creates enormous compute costs for traditional data warehouses.
For an operational data warehouse such as Materialize, the cost of compute is constant, since a set amount of computational resources are always running. This allows Materialize to incrementally update data as it arrives, and negates the need for sudden spikes in computation (and associated costs).
By incrementally updating source data, Materialize enables materialized views and indexes to update without requiring the same computational cost as re-running a query. For example, when a single row of input data changes in a large transformation, Materialize only does a small amount of work to update the results.
Materialize decouples cost from data freshness (query frequency), and allows you to perform a wide array of operational use cases.
Data Freshness: New Possibilities & Use Cases
Data freshness is a critical factor for all data products, from BI dashboards to alerting systems. However, for operational use cases that power business processes, data freshness is critical.
Fresh data is needed to power real-time business workflows, such as fraud detection and user-facing analytics. But batch processing and query costs make analytical data warehouses unsuitable for such use cases.
With streaming data, SQL support, and an optimized compute engine, operational data warehouses such as Materialize allow you to perform continuous data transformation inexpensively.
Is an operational data warehouse the right fit for your use case? Read our new whitepaper to find out.
