What's new in Materialize? Volume 1
December 20, 2021

Welcome to our first product update!
To make sure that we ship new features and improvements out as soon as possible, we’ve reduced the duration of our release cycle and are now bringing you a fresh Materialize release every week. Now, we realize this might make it harder to keep up with what’s going on, so: here we are!
This time around, we’ll cover Materialize Core v0.9.1 to v.0.12.0, as well as some new improvements to Materialize Cloud. For further details on a specific version of Materialize (like breaking changes or bug fixes), check out the release notes!
Materialize Core
Sources and Sinks
Kafka source metadata
When using Kafka as a source, you might want to process metadata fields along with record data to e.g. propagate the record offset or use embedded metadata timestamps for time-based operations. From v0.12.0, we expose partition, offset and timestamp metadata in Kafka sources via the INCLUDE PARTITION, INCLUDE OFFSET and INCLUDE TIMESTAMP options (in addition to the already supported INCLUDE KEY option).
Protobuf+schema registry for Redpanda sources
Redpanda recently rolled out support for protobuf schema publication in v21.11.1 🎉, so you can now use Redpanda sources in Materialize with protobuf against a schema registry.
SQL
CSV support in COPY FROM
COPY FROM now also supports the CSV format (v0.9.12), which lets you bulk import data from .csv files into Materialize tables using the Postgres COPY protocol.
Time bucketing with date_bin
The new date_bin function (v0.9.12) allows you to bucket data into arbitrary time intervals, in a similar but less strict way than date_trunc (which uses fixed units of time e.g. second, minute, hour). As an example, imagine we want to keep track of the volume of market orders for a specific symbol in 5 minute intervals, starting at a given point in time:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
Using date_bin creates fixed-size, non-overlapping buckets where each record belongs to exactly one interval (i.e. tumbling windows). Let's take a quick peek at what the output of such a view looks like, using Metabase:
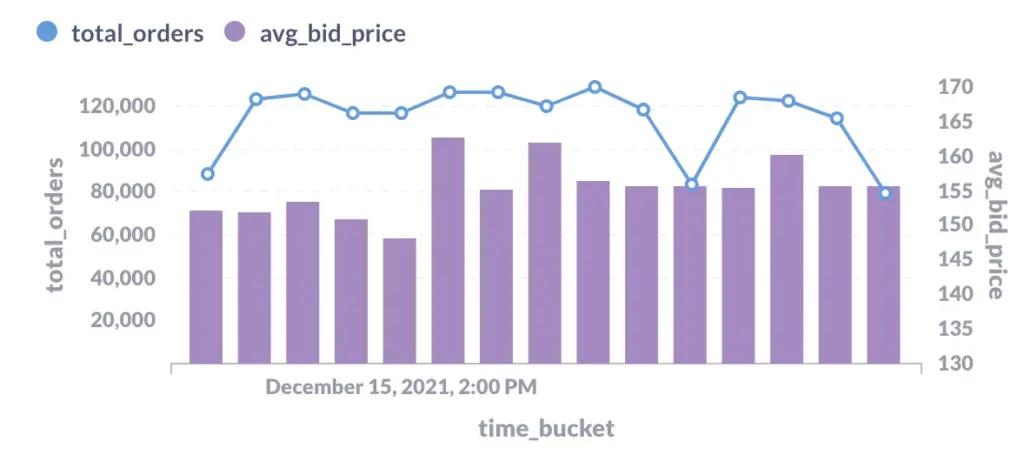
Operations
ARM support
Starting from v0.11.0, we’re providing beta support for Materialize on ARM64 architectures (MacOS and Linux)! We will be running further testing in the coming weeks, and encourage you to report any performance or stability issues you might come across with the new versions!
Memory optimizations
We continuously work to reduce the runtime memory footprint of Materialize and make your queries go vroom. ⚡ In the latest releases, we pushed improvements that significantly reduce idle memory consumption, as well as the resource overhead introduced by logging. For arrangements (i.e. how Materialize stores data in memory), in particular, we’re seeing up to 2x memory savings after some optimizations to dataflow planning!
We’ll be publishing a deep-dive blogpost about these improvements and other planned work around memory optimization soon!
New system catalog tables
The mz_catalog schema contains some important metadata information about the performance of your running materialized instance. From v0.9.12, we’re providing a single table for Kafka source statistics, exposing all librdkafka statistics: mz_kafka_source_statistics.
Ecosystem
Native Metabase integration
From Materialize v0.11.0, you can connect to Metabase (0.41+) using the official Postgres connector instead of the forked metabase-materialize-driver. As we move away from supporting v0.10.0, the driver will eventually be deprecated. If you’re relying on it, we recommend upgrading Materialize and making the switch as soon as possible!
Materialize Cloud
UI
Dark mode
The Materialize Cloud theme now has light and dark mode support! We will automatically match the UI mode to the preferences you have set on your machine.
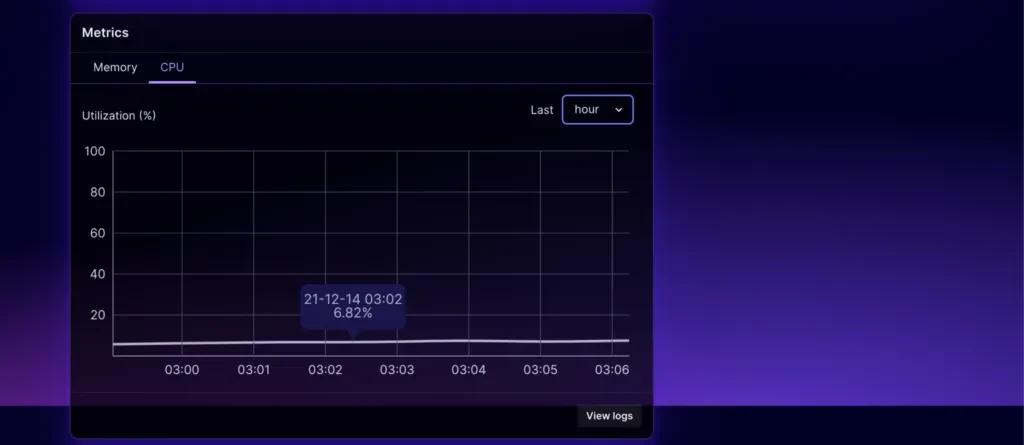
Metrics monitoring
For each deployment, we now provide a metrics card with charts that track historical utilization of memory and CPU usage, which helps you understand when you’re approaching the limits of the current deployment size.
Deployment
New availability region 🎉
In addition to us-east-1, Materialize Cloud is now also available in eu-west-1! What other regions would you like us to support? Let us know!
What’s next?
Some of the biggest ongoing threads for upcoming releases focus on hardening existing features (like exactly-once sinks), and improving Materialize’s robustness for production. On the SQL side, we’ve started exploring how to expand our support for windowing semantics (to include e.g. session windows), and are working to broaden our ecosystem of third-party tools by implementing wider coverage for pg_catalog tables and psql macros!
For Materialize Cloud, we’re focused on strengthening the user experience and more tightly integrating with existing AWS functionality. As a reminder: Materialize Cloud is in open beta, so you can sign up and have a look around!
If you take any of the new features for a spin, or if you’re just getting started with Materialize, we’d love to hear from you in our Slack community!

