Improved memory usage during sink restarts
02.28.2025
This week we shipped a significant improvement to the memory requirements needed when restarting a sink.
Previously, when restarting a sink we would rehydrate the in-memory state with memory proportional to the full size of the sinked collection, even if the size of the steady-state changes was small. For users sinking out large collections, this led to a pattern of high memory spikes upon cluster restart, followed by a steep drop-off for the rest of the cluster's uptime. As a result, users needed to size their clusters to support the much larger peak memory usage, that was only used briefly, rather than the lower steady-state memory.
Now, we are able to restart sinks using memory proportional to only the steady-state changes. For some users, the effect of this change has been dramatic!
In one of the more extreme cases, we saw over a 10x reduction in memory:
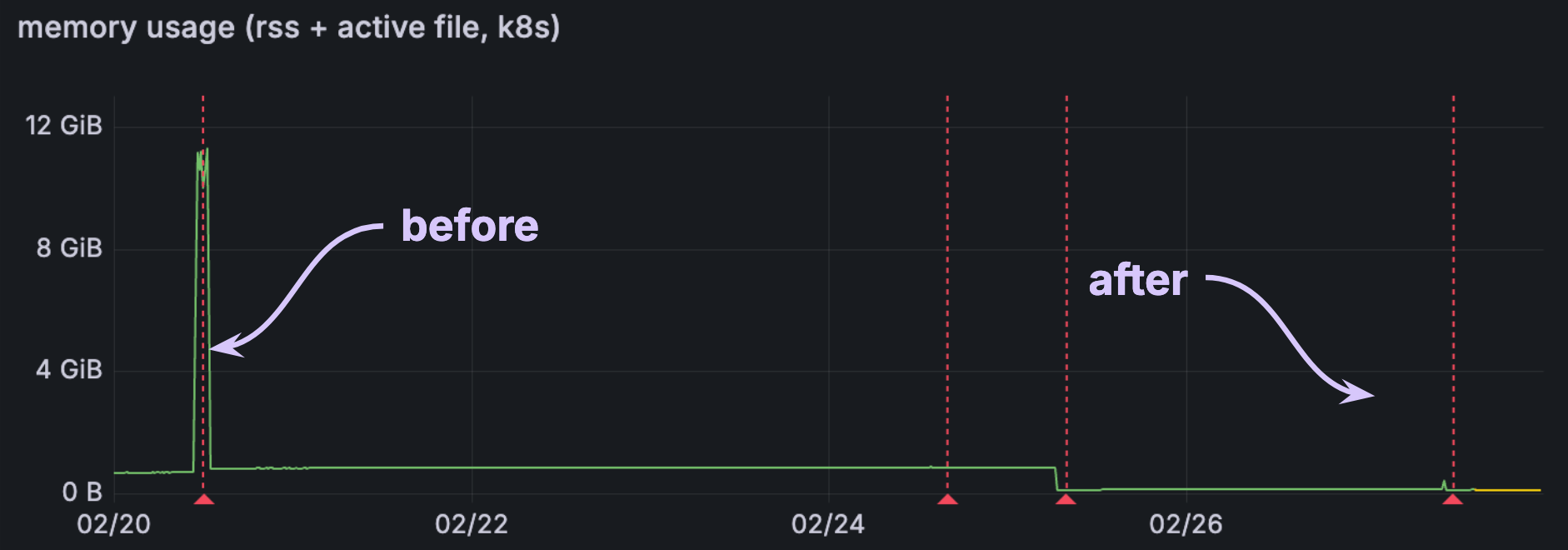
For others, the impact is significant but more modest, with 20-25% reduction to memory:
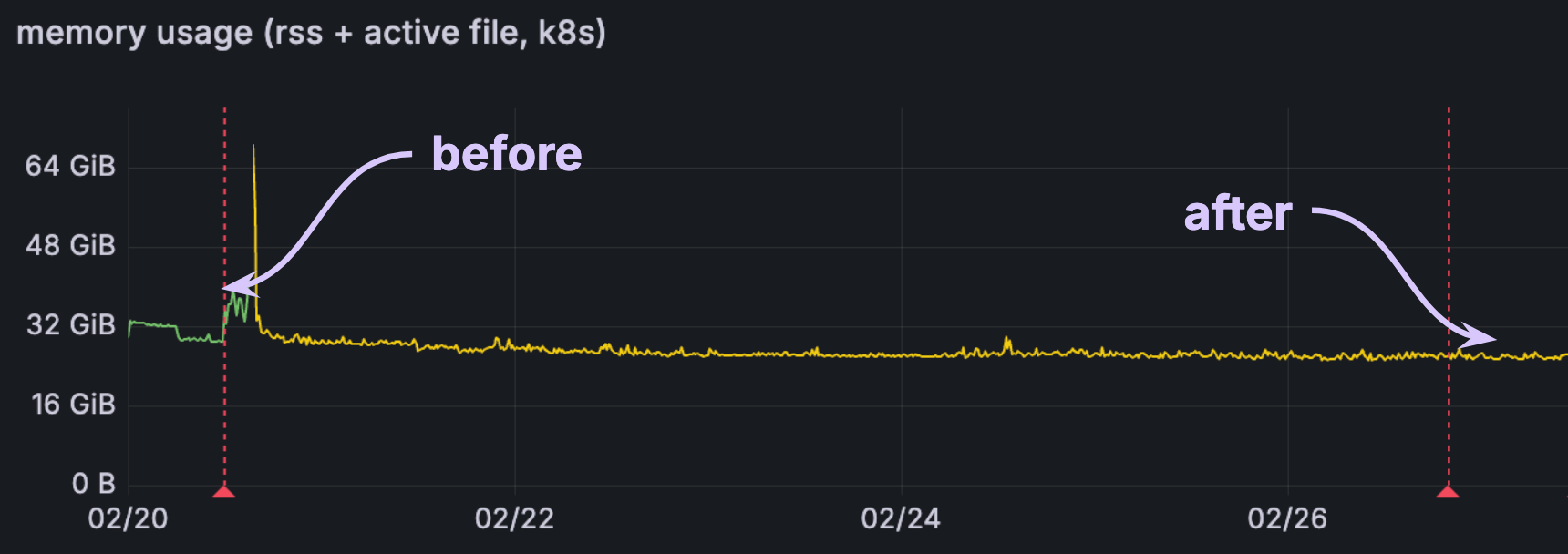
What does this mean to you?
If you use sinks, your memory usage should now be more much consistent across restarts. It may be newly possible to downsize your clusters if they were previously scaled to handle the sink restart memory spike.