Releases
View as Markdownv26.16.0
Released to Materialize Cloud: 2026-03-19
Released to Materialize Self-Managed: 2026-03-20
This release adds support for copying Parquet files from object storage, performance improvements, and bug fixes.
COPY FROM Parquet files in object storage
COPY FROM now supports bulk importing data from Parquet files stored in Amazon
S3 and any S3-compatible object storage service, such as Google Cloud Storage,
Cloudflare R2, or MinIO. You can import Parquet files using an AWS connection or
a presigned URL.
COPY INTO my_table
FROM 's3://my_bucket/my_data.parquet'
(FORMAT PARQUET, AWS CONNECTION = my_aws_conn);
For more information, refer to:
Improvements
- Improved
AS OFerror messages: Error messages forAS OFqueries now use user-facing terminology (e.g., “Indexed input”, “Storage inputs”) instead of internal names. - Streamed WebSocket query results: WebSocket query results are now streamed directly instead of buffered, reducing memory usage for large result sets.
Bug Fixes
- Fixed an RBAC security bypass that allowed a non-superuser with
CREATEROLEprivilege to strip superuser status from any role viaALTER ROLE ... NOSUPERUSER. - Fixed indexes on older versions of altered tables or replaced materialized views being lost during environment bootstrap, which could cause panics.
- Fixed pgwire encoding errors leaving partial messages in the connection buffer, which caused clients to see “lost synchronization” errors instead of proper error messages.
- Fixed unbounded queue growth in storage since-downgrade processing that could lead to out-of-memory conditions in environments with many storage collections.
- Fixed a correctness bug when parsing large Avro fixed-size decimals from Kafka sources, where values were returned as raw bytes instead of decoded decimal numbers.
- Fixed subqueries being incorrectly allowed in the
SETclause ofUPDATEstatements. - Fixed
COPY FROM S3requiring manual column specification for tables withNOT NULLcolumns by removing a redundant non-null check during planning. - Fixed a correctness issue with
COPY FROM STDINwhen using headers. - Fixed column name deduplication bug in
COPY TO/ Parquet writer that could produce duplicate column names. - Fixed
RETAIN HISTORYvalue being ignored for webhook tables. - Fixed
DROP OWNED BYandREASSIGN OWNED BYnot including network policies, which could blockDROP ROLEfor roles that own network policies. - Fixed false positive wallclock lag reporting (showing ~56 years of lag) during replica startup for compute introspection indexes.
v26.15.0
Released to Materialize Cloud: 2026-03-12
Released to Materialize Self-Managed: 2026-03-13
This release includes various improvements and bug fixes.
Improvements
- Improved memory efficiency for joins on
varcharandtextcolumns: Previously, joining on these columns required creating a new arrangement, effectively doubling memory usage. Materialize can now reuse existing arrangements on these columns. We’ve seen memory improvements by as much as 25% in some cases involvingvarcharindexes. - Added support for setting
cpu_requestindependently ofcpu_limitin cluster replica sizes for Self-Managed deployments. - Renamed the Org ID label to Environment ID in the Console Shell to disambiguate organization IDs from environment IDs, which was causing confusion for Self-Managed deployments.
Bug Fixes
- Fixed unmaterializable functions (e.g.,
now()) being allowed inAS OFqueries, which could return incorrect results. - Fixed Kafka sink creation failing with an authorization error when the progress topic already exists, which affected workflows where topics are pre-created by a superuser.
- Fixed a panic when running
COPY FROM STDINconcurrently with table drops. - Fixed unbounded command queue buildup in internal storage writer tasks that could lead to out-of-memory conditions when environments have a large number of indexes.
- Fixed the Role Filters display in dark mode in the Console.
- Fixed an incorrect join condition in the Console cluster list that could cause incorrect cluster information to be displayed.
v26.14.1
Released to Materialize Cloud: 2026-03-05
Released to Materialize Self-Managed: 2026-03-06
This release introduces COPY FROM support for CSVs in object storage, source versioning for SQL Server sources, and performance improvements to DDL.
COPY FROM CSVs in object storage
COPY FROM now supports bulk importing data directly from Amazon S3 and any
S3-compatible object storage service, such as Google Cloud Storage, Cloudflare
R2, or MinIO. You can import CSV files using an AWS connection or a presigned
URL.
COPY INTO my_table
FROM 's3://my_bucket/my_data.csv'
(FORMAT CSV, AWS CONNECTION = my_aws_conn);
For more information, refer to:
SQL Server: Source versioning
To enable this feature in your Materialize region, contact our team.
For SQL Server sources, we’ve introduced new syntax
for CREATE SOURCE and CREATE TABLE. This allows you to better handle schema changes
in your source SQL Server tables.
- Changing column types is currently unsupported.
For more information, refer to:
- Guide: Handling upstream schema changes with zero downtime
- Syntax:
CREATE SOURCE - Syntax:
CREATE TABLE
Improvements
- Faster DDL at scale: We’ve improved DDL (e.g.,
CREATE VIEW,CREATE INDEX,DROP) latency by 37-55% for environments with many objects by making the internal catalog state a persistent data structure with structural sharing. - Faster Iceberg sink commits: We’ve improved Iceberg sink commit performance by disabling the duplicate check for RowDelta actions, which was causing significant commit time overhead.
- Up to 28x faster
COPY FROM STDIN: We’ve improvedCOPY FROM STDINperformance by parallelizing ingestion and using constant memory.
Bug Fixes
- Fixed the jsonb contains operator (
?) to correctly return NULL when the left operand is NULL, matching PostgreSQL behavior. - Internal optimization that reduces resource usage of the catalog server; this can reduce resource consumption on restart when indexes are added.
- Fixed a panic when using
COPY FROMwith invalid range values (e.g.,[7,3)where lower bound exceeds upper bound), now returning a proper error message. - Fixed incorrect replication lag display in the Console during
PostgreSQL source snapshots, where
offset_committedwas incorrectly reported as zero until the snapshot completed. - Fixed a panic when dropping materialized views that had active subscribes depending on older GlobalIds.
- Fixed dataflows being incorrectly re-planned after an environmentd restart due to missing per-cluster optimizer feature overrides.
- Fixed query formatting for SQL Server and MySQL sources.
v26.13.0
Released to Materialize Cloud: 2026-02-26
Released to Materialize Self-Managed: 2026-02-27
This release includes the release of our Iceberg Sink, performance improvements to SUBSCRIBE, and bugfixes.
Iceberg Sink
CREATE SINK my_iceberg_sink
IN CLUSTER sink_cluster
FROM materialized_view_mv1
INTO ICEBERG CATALOG CONNECTION iceberg_catalog_connection (
NAMESPACE = 'my_iceberg_namespace',
TABLE = 'mv1'
)
USING AWS CONNECTION aws_connection
KEY (row_id)
MODE UPSERT
WITH (COMMIT INTERVAL = '60s');
For more information, refer to:
- Guide: How to export results from Materialize to Apache Iceberg Tables
- Blog: Making Iceberg work for Operational Data
- Syntax: CREATE SINK… INTO ICEBERG
Improvements
- Improved
SUBSCRIBEPerformance: We’ve optimizedSUBSCRIBEto skip initial snapshots in more cases. This can speed upSUBSCRIBEstart times. - Improved compatibility with external tools: We’ve added
strposas a synonym for thepositionfunction, improving compatibility with tools such as PowerBI. - Improved database concurrency: We’ve reduced contention when a single collection experiences a high volume of updates.
Bug Fixes
- Fixed a panic when constructing multi-dimensional arrays with null values, now treating null elements as zero-dimensional arrays consistent with PostgreSQL behavior.
- Fixed a bug where dropping a replacement materialized view (instead of applying the replacement) could seal the target materialized view for all times after an environmentd restart.
- Fixed a bug where
Int2VectortoArraycasting did not correctly handle element type conversions, potentially causing incorrect results or errors. - Fixed the Self-Managed bug in the memory-based calculation of replica size credits, which was incorrectly multiplying by the number of workers instead of using the correct per-process memory limit.
- Fixed an overflow display issue on the roles page in the console.
- Fixed SSO connection configuration pages in the console, which did not load properly due to missing content security policy entries.
v26.12.0
Released to Materialize Cloud: 2026-02-19
Released to Materialize Self-Managed: 2026-02-20
This release introduces our Roles and Users page, performance improvements, and bugfixes.
Role Management
The new Roles and Users page on the Materialize Console allows organization administrators to create roles, grant privileges, and assign roles to users. You can also track the hierarchy of roles using the graph view.
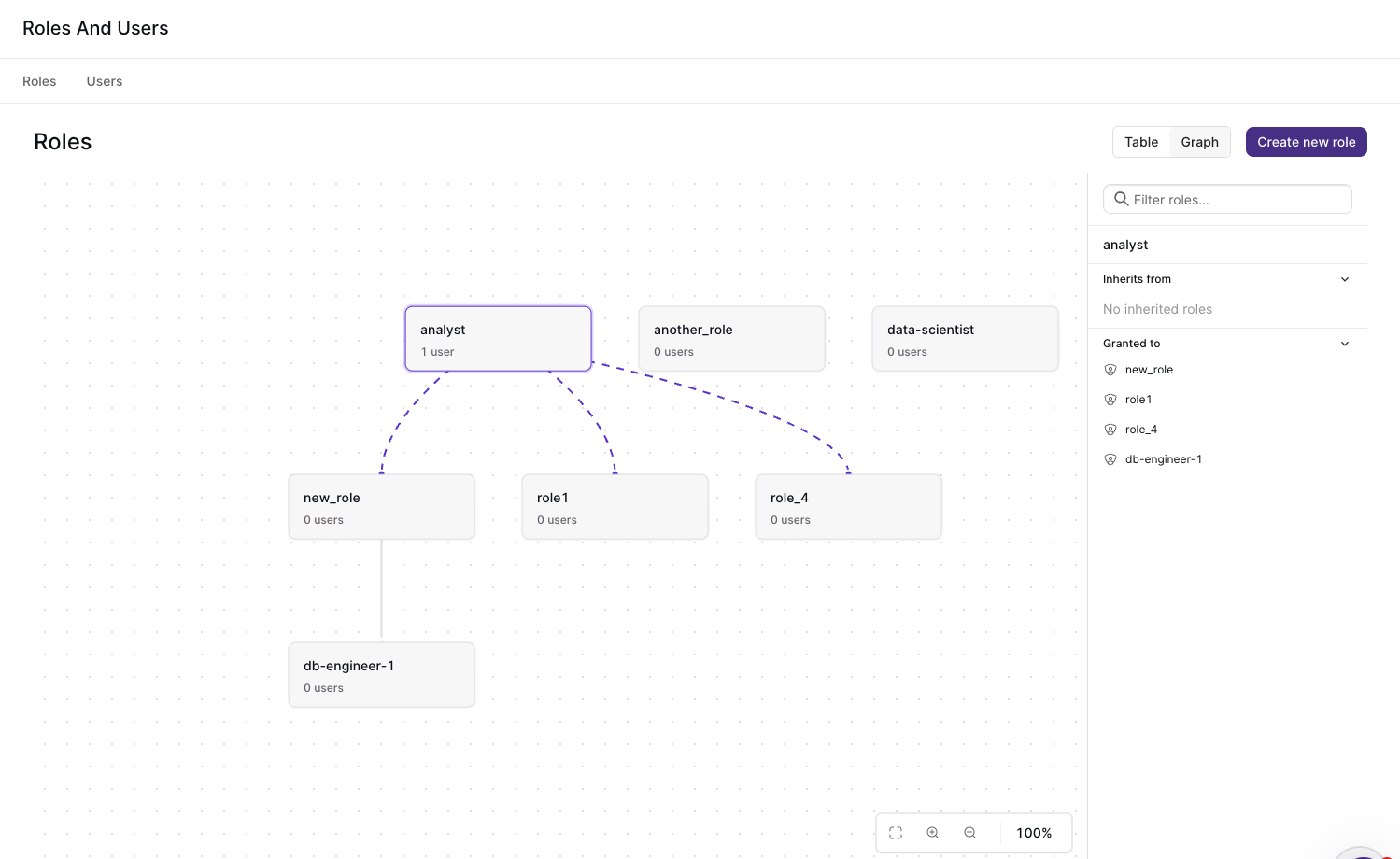
You can navigate to the Roles and Users page directly from the Materialize console. If you’re on Materialize Self-Managed, upgrade to v26.12 first. If you’re on Materialize Cloud, you can go directly to https://console.materialize.com/roles to reach the page.
Improvements
- Updated default resource requirements (
Materialize Self-Managed only ): We’ve updated the Materialize Self-Managed Helm charts to ensure correct operation on Kind clusters - Improved console query history performance: We’ve optimized RBAC queries to use OIDs instead of names, resulting in 2-3x faster page execution.
Bug Fixes
- Fixed a panic when using unsupported types (e.g., float) with range expressions, now returning a proper error message instead of an internal error.
- Fixed a panic when using empty
int2vectorvalues, which could cause internal errors during query optimization or execution. - Fixed internal errors that could occur during query optimization due to type
checking mismatches in
ColumnKnowledgeand related transforms, adding fallback handling to prevent crashes. - Fixed compatibility with older Amazon Aurora PostgreSQL versions when using
parallel snapshots, by using
SELECT current_setting()instead ofSHOWfor version retrieval. - Fixed version comparison in the Materialize Kubernetes operator to correctly follow semver precedence rules, no longer rejecting upgrades that differ only in build metadata.
v26.11.0
Released to Materialize Cloud: 2026-02-19
Released to Materialize Self-Managed: 2026-02-13
This release includes improvements to Avro Schema references, EXPLAIN commands, and bug fixes.
Improvements
- Avro Schema References: Sources can now use avro schemas which reference other schemas when using Confluent Schema Registry.
EXPLAINimprovements:EXPLAINnow allows you to inspect the query plan forSUBSCRIBEstatements. It also fully qualifies index names if there are identically-named indexes across different schemas.- More efficient dbt-adapter: We’ve added indexes on
mz_hydration_statusesandmz_materialization_lag. This should speed up “deployment ready” queries made by our dbt-adapter.
Bug Fixes
- Fixed a bug where
IS DISTINCT FROMcould fail typechecking in certain cases involving different data types, causing query errors. - Improved the error message when
INSERT INTO ... SELECTtransitively references a source.
v26.10.1
Released to Materialize Cloud: 2026-02-05
Released to Materialize Self-Managed: 2026-02-06
This release introduces Replacement Materialized Views, performance improvements, and bugfixes.
Replacement Materialized Views
For more information, refer to:
- Guide: Replace Materialized Views
- Syntax: CREATE REPLACEMENT MATERIALIZED VIEW
- Syntax: ALTER MATERIALIZED VIEW
Improvements
- Improved hydration times for PostgreSQL sources: PostgreSQL sources now perform parallel snapshots. This should improve initial hydration times, especially for large tables.
Bug Fixes
- Fixed an issue where floating-point values like
-0.0and+0.0could be treated as different values in equality comparisons but the same in ordering, causing incorrect results in operations likeDISTINCT. - Fixed an issue where certain SQL keywords required incorrect quoting in expressions.
- Fixed the
ORDER BYclause inEXPLAIN ANALYZE MEMORYto correctly sort by memory usage instead of by the text representation. - Fixed a bug where the optimizer could mishandle nullability inside record types.
- Fixed an issue where the
mz_rolessystem table could produce invalid retractions when certain system variables were changed. - Console: Fixed SQL injection vulnerability in identifier quoting where only the first quote character was being escaped.
v26.9.0
Released to Materialize Cloud: 2026-01-29
Released to Materialize Self-Managed: 2026-01-30
v26.9 includes significant performance improvements to QPS & query latency.
Improvements
- Up to 2.5x increased QPS: We’ve significantly optimized how
SELECTstatements are processed; they are now processed outside the main thread. In our tests, this change increased QPS by as much as 2.5x.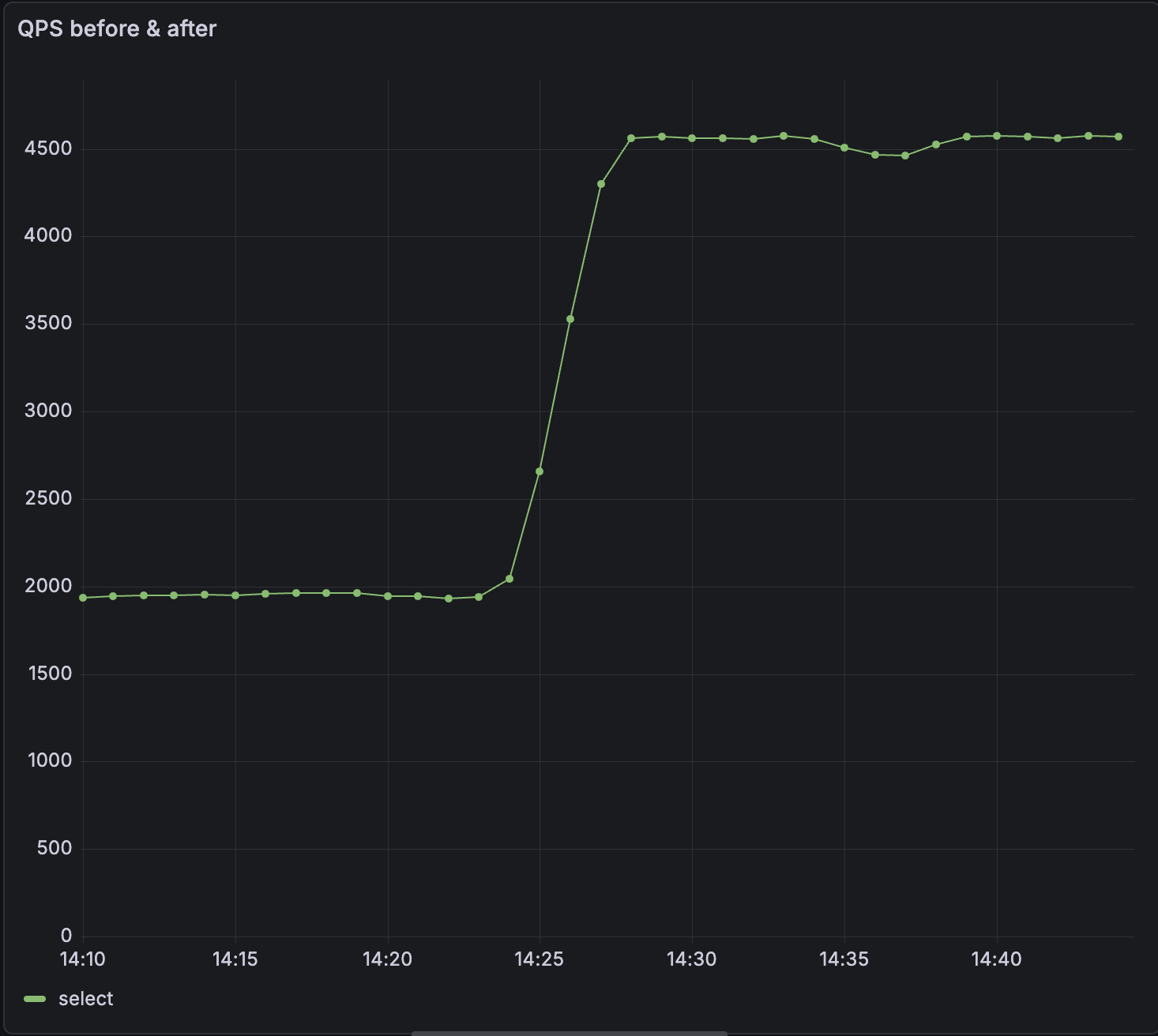
- Significant reduction in query latency: Moving
SELECTstatements off the main thread has significantly reduced latency. p99 has reduced by up to 50% for some workloads.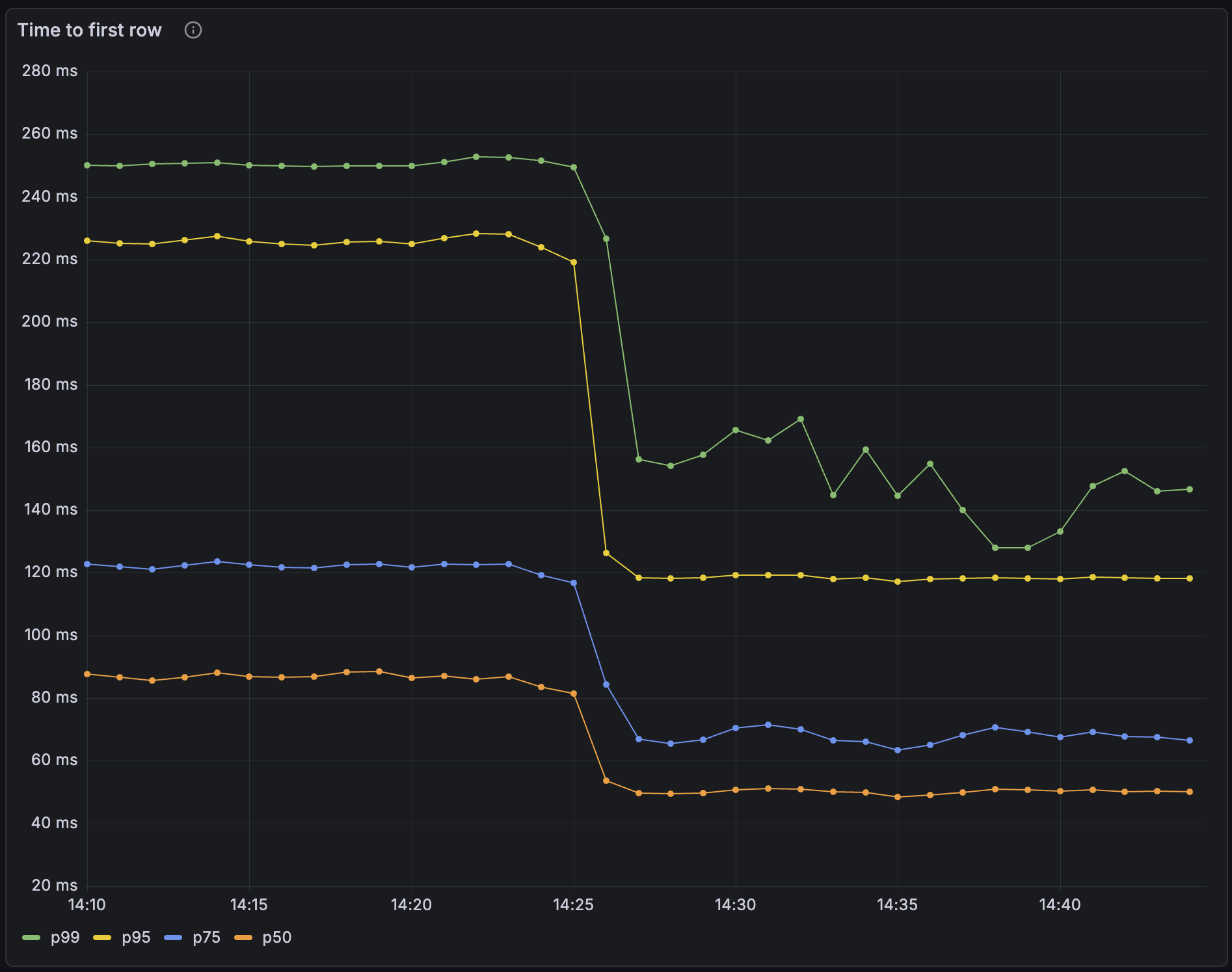
- Dynamically configure system parameters using a ConfigMap (
Materialize Self-Managed only ): You can now use a ConfigMap to dynamically update system parameters at runtime. In many cases, this means you don’t need to restart Materialize for new system parameters to take effect. You can also specify system parameters which survive restarts and upgrades. Refer to our documentation on configuring system parameters. - Added
ABORTas a PostgreSQL-compatible alias for theROLLBACKtransaction command, to improve compatibility with GraphQL engines like Hasura
Bug Fixes
- Fixed an issue causing new generations to be promoted prematurely when using the
WaitUntilReadyupgrade strategy (Materialize Self-Managed only ) - Fixed a race condition in source reclock that could cause panics when the
as_oftimestamp was newer than the cached upper bound. - Improved error messages when the load balancer cannot connect to the upstream environment server
v26.8.0
Released to Materialize Cloud: 2026-01-22
Released to Materialize Self-Managed: 2026-01-23
v26.8 includes a new notice in the Console to help catch common SQL mistakes, Protobuf compatibility improvements, and performance optimizations for view creation.
Improvements
- Added a Console notice when users write
= NULL,!= NULL, or<> NULLin SQL expressions instead ofIS NULLorIS NOT NULL. Comparisons using=,!=, or<>withNULLalways evaluate toNULL. - Protobuf schemas that import well-known types (such as
google.protobuf.Timestamporgoogle.protobuf.Duration) now work automatically when using a Confluent Schema Registry connection. - Improved performance of view creation by caching optimized expressions, resulting in approximately 2x faster view creation in some scenarios.
v26.7.0
Released to Materialize Self-Managed: 2026-01-16
Released to Materialize Cloud: 2026-01-17
v26.7 improves compatibility with go-jet and includes bug fixes.
Improvements
- Improved compatibility with go-jet: We’ve added the
attndimscolumn topg_attribute. We’ve also fixedpg_type.typelemto correctly report element types for named list types. - Pretty print SQL in the console: We’ve made it easier to read the definitions for views and materialized views in the console.
Bug Fixes
- Fixed an issue where type error messages could inadvertently expose constant values from queries.
- The console reconnects more gracefully if the connection to the backend is interrupted
v26.6.0
Released to Materialize Cloud: 2026-01-08
Released to Materialize Self-Managed: 2026-01-09
v26.6.0 includes bug fixes for Kafka sinks and Self-Managed deployments.
Bug Fixes
- Fixed an issue where console and balancer deployments could fail to upgrade to the correct version during Self-Managed environment upgrades.
- Fixed an issue where
ALTER SINK ... SET FROMon Kafka sinks could incorrectly restart in snapshot mode even when the sink had already made progress, causing unnecessary resource consumption and potential out-of-memory errors.
v26.5.1
Released to Materialize Self-Managed: 2025-12-23
Released to Materialize Cloud: 2026-01-08
v26.5.1 enhances our SQL Server source, improves performance, and strengthens Materialize Self-Managed reliability.
Improvements
- VARCHAR(MAX) and NVARCHAR(MAX) support for SQL Server: The Materialize SQL Server source now supports
varchar(max)andnvarchar(max)data types. - Faster authentication for connection poolers: We’ve added an index to the
pg_authidsystem catalog. This should significantly improve the performance of default authentication queries made by connection poolers like pgbouncer. - Faster Kafka sink startup: We’ve updated the default Kafka progress topic configuration to reduce the amount of progress data processed when creating new Kafka sinks.
- dbt strict mode: We’ve introduced
strict_modeto dbt-materialize, our dbt adapter.strict_modeenforces production-ready isolation rules and improves cluster health monitoring. It does so by validating source idempotency, schema isolation, cluster isolation and index restrictions. - SQL Server Always On HA failover support (
Materialize Self-Managed only ): Materialize Self-Managed now offers better support for handling failovers, without downtime, in SQL Server Always On sources. Contact our support team to enable this in your environment. - Auto-repair accidental changes (
Materialize Self-Managed only ): Improvements to the controller logic allow Materialize to auto-repair changes such as deleting a StatefulSet. This means that your production setups should be more robust in the face of accidental changes. - Track deployment status after upgrades (
Materialize Self-Managed only ): The Materialize custom resource now displays both active and desiredenvironmentdversions. This makes it easier to track deployment status after upgrades.
Bug fixes
- Added additional checks to string functions (
replace,translate, etc.) to help prevent out-of-memory errors from inflationary string operations. - Fixed an issue which could cause panics during connection drops; this means improved stability when clients disconnect.
- Fixed an issue where disabling console or balancers would fail if they were already running.
- Fixed an issue where balancerd failed to upgrade and remained stuck on its pre-upgrade version.
v26.4.0
Released to Materialize Self-Managed: 2025-12-17
Released to Materialize Cloud: 2025-12-18
v26.4.0 introduces several performance improvements and bugfixes.
Improvements
- Over 2x higher connections per second (CPS): We’ve optimized how Materialize handles inbound connection requests. In our tests, we’ve observed 2x - 4x improvements to the rate at which new client connections can be established. This is especially beneficial when spinning up new environments, warming up connection pools, or scaling client instances.
- Up to 3x faster hydration times for large PostgreSQL tables: We’ve reduced the overhead incurred by communication between multiple workers on a large cluster. We’ve observed up to 3x throughput improvement when ingesting 1 TB PostgreSQL tables on large clusters.
- More efficient source ingestion batching: Sources now batch writes more effectively. This can result in improved freshness and lower resource utilization, especially when a source is doing a large number of writes.
- CloudSQL HA failover support (
Materialize Self-Managed only ): Materialize Self-Managed now offers better support for handling failovers in CloudSQL HA sources, without downtime. Contact our support team to enable this in your environment. - Manual Promotion (
Materialize Self-Managed only ): Rollout strategies allow you control how Materialize transitions from the current generation to a new generation during an upgrade. We’ve added a new rollout strategy calledManuallyPromotewhich allows you to choose when to promote the new generation. This means that you can minimize the impact of potential downtime.
Bug Fixes
- Fixed timestamp determination logic to handle empty read holds correctly.
- Fixed lazy creation of temporary schemas to prevent schema-related errors.
- Reduced SCRAM iterations in scalability framework and fixed fallback image configuration.
v26.3.0
Released to Materialize Cloud & Materialize Self-Managed: 2025-12-12
Improvements
- For Self-Managed: added version upgrade window validation, to prevent skipping required intermediate versions during upgrades.
- Improved activity log throttling to apply across all statement executions, not just initial prepared statement execution, providing more consistent logging behavior.
Bug Fixes
- Fixed validation for replica sizes to prevent configurations with zero scale or workers, which previously caused division-by-zero errors and panics.
- Fixed frontend
SELECTsequencing to gracefully handle collections that are dropped during real-time recent timestamp determination.
v26.2.0
Released Cloud: 2025-12-05
Released Self-Managed: 2025-12-09
This release focuses primarily on bug fixes.
Bug fixes
-
Catalog updates: Fixed a bug where catalog item version updates were incorrectly ignored when the
create_sqldidn’t change, which could cause version updates to not be applied properly. -
Console division by zero: Fixed a division by zero error in the console, specifically when viewing
mz_console_cluster_utilization_overview. -
ALTER SINK improvements: Fixed
ALTER SINK ... SET FROMto prevent panics in certain situations. -
Improved rollout handling: Fixed an issue where rollouts could leave a pod at their previous configuration.
-
Dependency drop handling: Fixed panics that could occur when dependencies are dropped during a SELECT or COPY TO. These operations now gracefully return a
ConcurrentDependencyDroperror.
v26.1.0
Released Self-Managed: 2025-11-26
v26.1.0 introduces EXPLAIN ANALYZE CLUSTER, console bugfixes, and improvements for SQL Server support, including the ability to create a SQL Server Source via the Console.
EXPLAIN ANALYZE CLUSTER
The EXPLAIN ANALYZE statement helps analyze how objects, namely indexes or materialized views, are running. We’ve introduced a variation of this statement, EXPLAIN ANALYZE CLUSTER, which presents a summary of every object running on your current cluster.
You can use this statement to understand the CPU time spent and memory consumed per object on a given cluster. You can also reveal whether an object has skewed operators, where work isn’t evenly distributed among workers.
For example, to get a report on memory, you can run EXPLAIN ANALYZE CLUSTER MEMORY, and you’ll receive an output similar to the table below:
| object | global_id | total_memory | total_records |
|---|---|---|---|
| materialize.public.idx_top_buyers | u85496 | 2086 bytes | 25 |
| materialize.public.idx_sales_by_product | u85492 | 1909 kB | 148607 |
| materialize.public.idx_top_buyers | u85495 | 1332 kB | 77133 |
To understand worker skew, you can run EXPLAIN ANALYZE CLUSTER CPU WITH SKEW, and you’ll receive an output similar the table below:
| object | global_id | worker_id | max_operator_cpu_ratio | worker_elapsed | avg_elapsed | total_elapsed |
|---|---|---|---|---|---|---|
| materialize.public.idx_sales_by_product | u85492 | 0 | 1.18 | 00:00:00.094447 | 00:00:00.079829 | 00:00:00.159659 |
| materialize.public.idx_top_buyers | u85495 | 0 | 1.15 | 00:00:01.371221 | 00:00:01.363659 | 00:00:02.727319 |
| materialize.public.idx_top_buyers | u85495 | 1 | 1.03 | 00:00:01.356098 | 00:00:01.363659 | 00:00:02.727319 |
| materialize.public.idx_top_buyers | u85496 | 1 | 1.01 | 00:00:00.021163 | 00:00:00.021048 | 00:00:00.042096 |
| materialize.public.idx_top_buyers | u85496 | 0 | 0.99 | 00:00:00.020932 | 00:00:00.021048 | 00:00:00.042096 |
| materialize.public.idx_sales_by_product | u85492 | 1 | 0.82 | 00:00:00.065211 | 00:00:00.079829 | 00:00:00.159659 |
Improved SQL Server support
Materialize v26.1.0 includes improved support for SQLServer, including the ability to create a SQLServer Source via the console.
Upgrade notes for v26.1.0
- To upgrade to
v26.1or future versions, you must first upgrade tov26.0
Self-Managed v26.0.0
Released: 2025-11-18
Swap support
Starting in v26.0.0, Self-Managed Materialize enables swap by default. Swap allows for infrequently accessed data to be moved from memory to disk. Enabling swap reduces the memory required to operate Materialize and improves cost efficiency.
To facilitate upgrades from v25.2, Self-Managed Materialize added new labels to
the node selectors for clusterd pods:
-
To upgrade using Materialize-provided Terraforms, upgrade your Terraform version to
v0.6.1: -
To upgrade if
not using a Materialize-provided Terraforms, you must prepare your nodes by adding the required labels. For detailed instructions, see Prepare for swap and upgrade to v26.0.
SASL/SCRAM-SHA-256 support
Starting in v26.0.0, Self-Managed Materialize supports SASL/SCRAM-SHA-256 authentication for PostgreSQL wire protocol connections. For more information, see Authentication.
When SASL authentication is enabled:
- PostgreSQL connections (e.g.,
psql, client libraries, connection poolers) use SCRAM-SHA-256 authentication - HTTP/Web Console connections use standard password authentication
This hybrid approach provides maximum security for SQL connections while maintaining compatibility with web-based tools.
License Key
Starting in v26.0.0, Self-Managed Materialize requires a license key.
| License key type | Deployment type | Action |
|---|---|---|
| Community | New deployments |
To get a license key:
|
| Community | Existing deployments | Contact Materialize support. |
| Enterprise | New deployments | Visit https://materialize.com/self-managed/enterprise-license/ to purchase an Enterprise license. |
| Enterprise | Existing deployments | Contact Materialize support. |
For new deployments, you configure your license key in the Kubernetes Secret resource during the installation process. For details, see the installation guides. For existing deployments, you can configure your license key via:
kubectl -n materialize-environment patch secret materialize-backend -p '{"stringData":{"license_key":"<your license key goes here>"}}' --type=merge
PostgreSQL: Source versioning
To enable this feature in your Materialize region, contact our team.
For PostgreSQL sources, starting in v26.0.0, Materialize introduces new syntax
for CREATE SOURCE and CREATE TABLE to allow better handle DDL changes to the upstream
PostgreSQL tables.
-
This feature is currently supported for PostgreSQL sources, with additional source types coming soon.
-
Changing column types is currently unsupported.
For more information, see:
Deprecation
The inPlaceRollout setting has been deprecated and will be ignored. Instead,
use the new setting rolloutStrategy to specify either:
WaitUntilReady(Default)ImmediatelyPromoteCausingDowntime
For more information, see rolloutStrategy.
Terraform helpers
Corresponding to the v26.0.0 release, the following versions of the sample Terraform modules have been released:
| Module | Description |
|---|---|
| Amazon Web Services (AWS) | An example Terraform module for deploying Materialize on AWS. See Install on AWS for detailed instructions usage. |
| Azure | An example Terraform module for deploying Materialize on Azure. See Install on Azure for detailed instructions usage. |
| Google Cloud Platform (GCP) | An example Terraform module for deploying Materialize on GCP. See Install on GCP for detailed instructions usage. |
| Terraform version | Notable changes |
|---|---|
| v0.6.4 |
|
If upgrading from a deployment that was set up using an earlier version of the Terraform modules, additional considerations may apply when using an updated Terraform modules to your existing deployments.
Click on the Terraform version link to go to the release-specific Upgrade Notes.
| Terraform version | Notable changes |
|---|---|
| v0.6.4 |
|
If upgrading from a deployment that was set up using an earlier version of the Terraform modules, additional considerations may apply when using an updated Terraform modules to your existing deployments.
See also Upgrade Notes for release specific notes.
| Terraform version | Notable changes |
|---|---|
| v0.6.4 |
|
If upgrading from a deployment that was set up using an earlier version of the Terraform modules, additional considerations may apply when using an updated Terraform modules to your existing deployments.
See also Upgrade Notes for release specific notes.
| terraform-helm-materialize | Notes | Release date |
|---|---|---|
| v0.1.35 |
|
2025-11-18 |
Upgrade notes for v26.0.0
-
Upgrading to
v26.0.0is a major version upgrade. To upgrade tov26.0fromv25.2.Xorv25.1, you must first upgrade tov25.2.16and then upgrade tov26.0.0. -
For upgrades, the
inPlaceRolloutsetting has been deprecated and will be ignored. Instead, use the new settingrolloutStrategyto specify either:WaitUntilReady(Default)ImmediatelyPromoteCausingDowntime
For more information, see
rolloutStrategy. -
New requirements were introduced for license keys. To upgrade, you will first need to add a license key to the
backendSecretused in the spec for your Materialize resource.See License key for details on getting your license key.
-
Swap is now enabled by default. Swap reduces the memory required to operate Materialize and improves cost efficiency. Upgrading to
v26.0requires some preparation to ensure Kubernetes nodes are labeled and configured correctly. As such:-
If you are using the Materialize-provided Terraforms, upgrade to version
v0.6.1of the Terraform. -
If you are
not using a Materialize-provided Terraform, refer to Prepare for swap and upgrade to v26.0.
-
See also Version specific upgrade notes.