Materialize For Everyone: Introducing Self-Managed and our Free Community Edition

What happens when you give an engineering team a building block for integrating transactional data and incrementally transforming it into real-time data products and APIs? First, queries that once melted operational databases now return promptly and correctly. Then sprawling services begin to collapse into individual SQL queries. A data pipeline that ran hourly batch jobs now operates in real-time with minimal effort. An SRE has their first full night’s sleep in weeks.
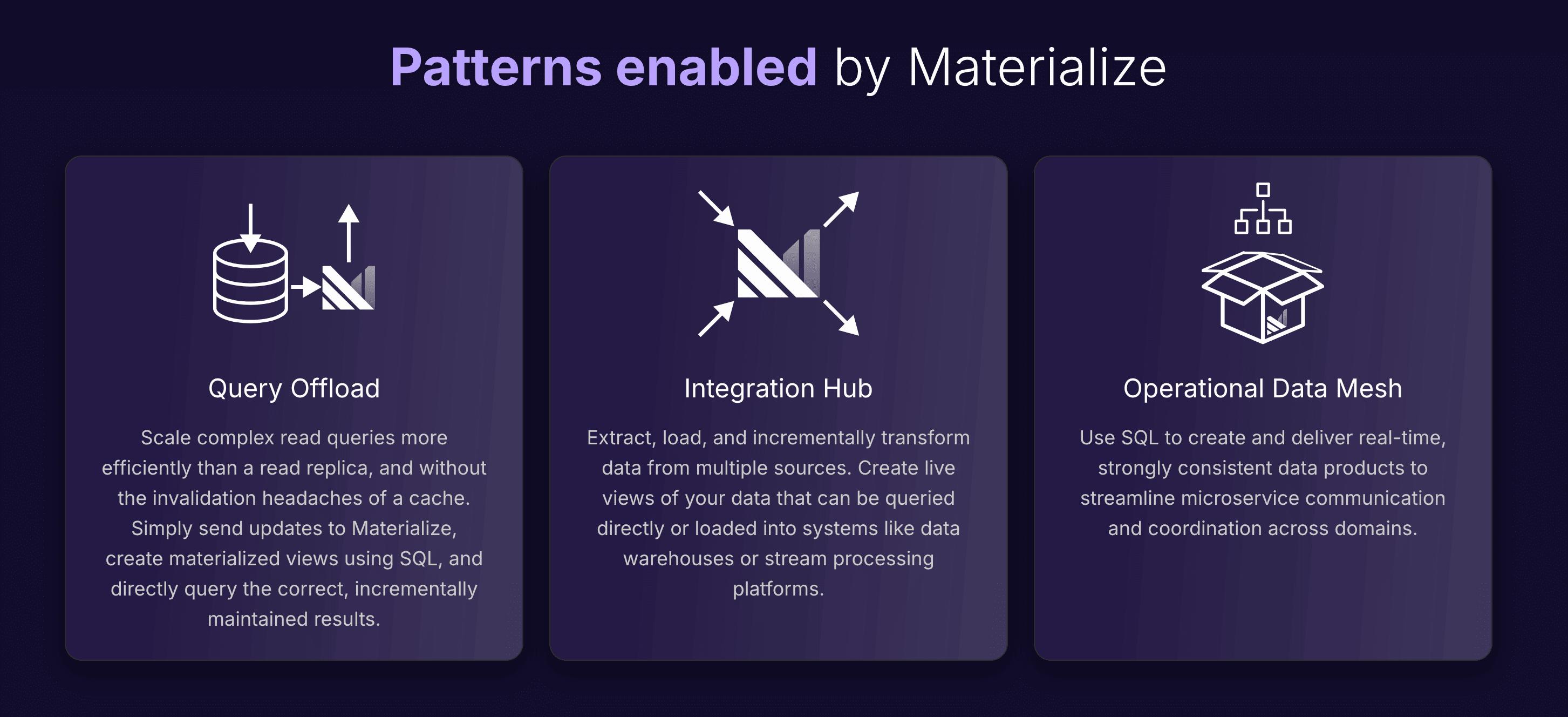
Materialize isn’t just about raw performance, it’s about happier developers and more ambitious projects. When you aren’t spending months writing boiler plate transformation code —it frees up time for real innovation, letting teams focus on building the next big thing instead of debugging cache invalidation code and writing data processing logic. The comfort of knowing your data is always correct and fresh, comes with the confidence to say "yes" to bold ideas: live personalization based on 360-views of customers; integrating real-time data into AI experiences; creating a consistent data fabric to support autonomous agent coordination.
Materialize Self-Managed
Despite the excitement around the core technology, we wrestled with one truth this year: Not every team can—or wants to—use a fully managed operational system in the cloud. Some need to deploy Materialize in their own cloud for security, compliance, or regulatory reasons. Others want full control over performance tuning, resource allocation, and infrastructure choices. And some need to run in regions or environments we don’t yet support—including air-gapped networks.
success
That’s why we’re excited to launch Materialize Self-Managed.
Many infrastructure products first reach critical mass as self-managed projects, and then add on a managed SaaS offering. We took the opposite path and went all in on SaaS. Our operational expertise was born in the cloud, running Materialize at scale for the largest and fastest growing companies from General Mills, to Fubo.tv, to Crane Worldwide Logistics. We’ve optimized deployments, automated recovery, and fine-tuned performance in high-stakes production environments.
Now, we’re applying our experience to self-managed deployments. With Materialize Self-Managed, you get the same powerful, incremental compute engine that has been battle-tested in our cloud service—now with the flexibility to run it your way, backed by the best practices we’ve refined in production. All you need is access to Kubernetes, a metadata store (Postgres), and an object store (for example S3 or Minio). Once you have those, you just need to choose what version you’ll manage: either our Enterprise Edition with an unrestricted license or our new Community Edition (CE).
Introducing the Community Edition
Incrementally and continually updating materialized views is the missing element in most data architectures. We want to fill in that hole by making Materialize accessible to as many developers as possible. We’re thrilled to introduce Materialize Community Edition—which gives you access to the full power of Materialize to power real production workloads.
Materialize has always been a source available product, but our Business Source License (BSL) was designed to support the shape of Materialize in 2019: a single process for doing stream transformation. For this release, we needed to evolve the license to unlock the benefit of our R&D over the last 6 years. What this means:
- Run production workloads for free. Materialice CE supports creating installations of Materialize to support everything from crunching through complex data transformations, performing blue-green deployments, and serving data products. The most popular Materialize patterns are now available to everyone.
- Usage Limits: Materialize CE is capped at 24GiB memory limit and a 48GiB disk limit per installation. If you need to support deployments outside of the community limits, contact us for a paid Self-Managed license or sign up for our Cloud offering.
- Getting Support: The Community Edition is supported via our community slack channel.
Materialize CE supports serious production workloads. The workload performance tests we published last year – which compared Materialize to an AWS Aurora Postgres read replica – fit comfortably into something you can now run for free. Below is a reproduction of the results from Materialize Cloud (note that a “50cc” cluster has a memory limit of ~8GiB and a disk limit of ~16GiB). While Community Edition users will still need to pay for the hardware, of course, the software cost is $0.

The Community Edition provides an accessible on-ramp to Materialize so more engineering and data teams can:
- Reduce infrastructure costs by spinning down expensive read replicas and transformation services.
- Optimize throughput and end-to-end latency when running complex queries on live, operational data.
- Improve developer velocity by making strongly consistent and composable real-time data pipelines declarative and accessible to anyone that can produce SQL.
Next Steps
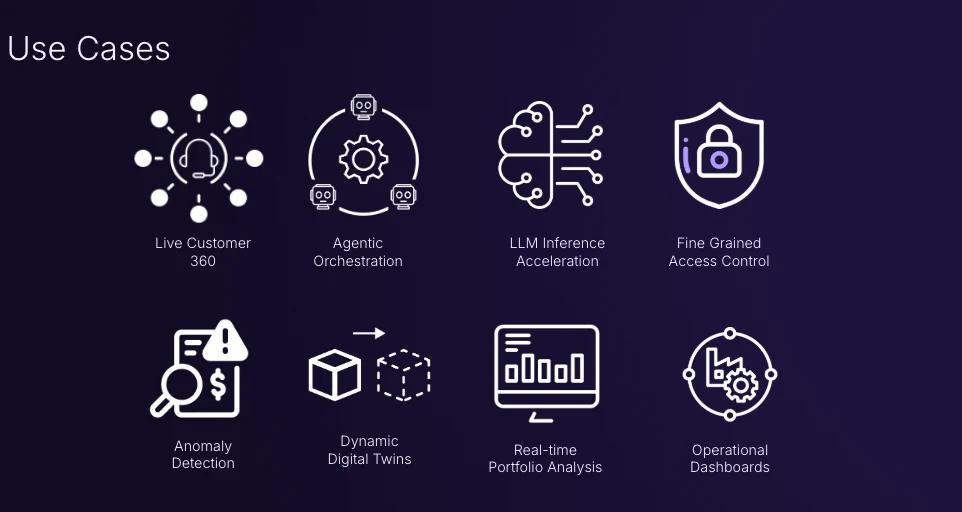
Wondering how you can use Materialize today? Here are some ideas for what you can do with Materialize.
Ready to learn more?
- Visit our docs to learn more details about setup and configuration.
- Join our Community Slack to swap tips, ask questions, and meet other real-time data enthusiasts.
- Star our Github repo to keep up to date on the latest developments.
Whether through our cloud product or a self-managed edition, we can’t wait to see how your team benefits from the time, energy, and cost savings that Materialize delivers.
