Join Kafka with a Database using Debezium and Materialize

The Problem
We need to provide (internal or end-user) access to a view of data that combines a fast-changing stream of events from Kafka with a table from a database (which is also changing).
Here are a few real-world examples where this problem comes up:
- Calculate API usage by joining API logs in Kafka with a user table
- Join IoT sensor data in Kafka with a sensor config table
- Generate affiliate program stats by joining pageviews with an affiliate user table
Solution: Stream the database to Kafka, materialize a view
The guide below walks through joining Kafka with a database by first streaming the database into Kafka using Debezium to do change data capture (CDC), and then using Materialize to maintain a SQL view that joins the two Kafka topics and outputs the exact data needed. (More context on Debezium and Materialize is provided below.)
Our Solution
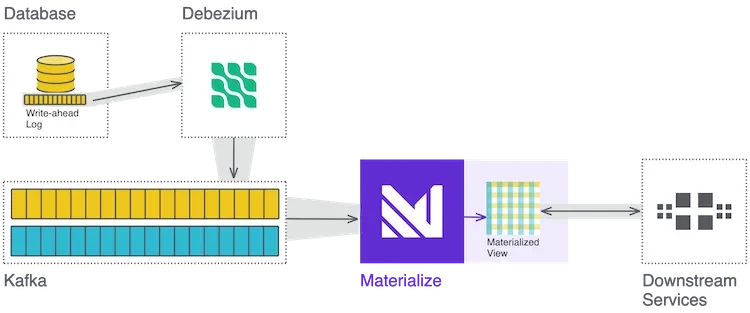
Why stream the database into Kafka?
The extra step of getting everything into Kafka is necessary because:
- Solutions that query the database on every Kafka event take away the scale and throughput benefits of a message broker by reintroducing limitations of a database.
- Solutions that munge the Kafka data back into a traditional database where a join can be done eliminate the "real-time" benefits of a stream by falling back to "batch" intervals.
NOTE: For PostgreSQL users, Materialize will soon be beta testing a direct Postgres connection that removes the need for Kafka by reading directly from Postgres and the Postgres WAL. Get in touch if interested in testing this out.
Important considerations for this approach
The Debezium + Materialize approach to joining Kafka with a database doesn't fit every use case. Consider the following factors:
- This is not creating a traditional stream-table join where Kafka events are enriched (e.g. new fields added) and sent to another Kafka broker because here we are aggregating the data into a materialized view. If you set out to build a stream-table join, this may still be useful to you: one-in-one-out enrichment often ends up in an aggregated view downstream. In those cases, the solution below is an opportunity to remove complexity.
- It's necessary to use Debezium when the data in the database is changing. If the data needed from the database is static (e.g. country codes and names) the simplest solution is to remove the database dependency entirely and load the data into Materialize using dbt seeds or the
COPY TOcommand.
Table of Contents
The remainder of this guide is split into a conceptual overview followed by a hands-on walkthrough with code examples.
Learn about the components
Debezium
Debezium is an open-source Kafka Connect component that listens for changes to a database (INSERTS, UPDATES, DELETES), translates them into change data capture (CDC) events, and pushes them to a message broker.
Here's a more tangible example of how Debezium works.
Upon running this update query:
1 | |
Debezium produces an event like this to a Kafka topic matching the name of the table:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
The change data capture event contains metadata about the table and the state of the entire row before and after the update.
Further reading on Debezium
Materialize
Once all the data is in Kafka, the next step is to join the Kafka-native data and the CDC data in a materialized view that outputs the exact structure we need. For that, we use Materialize, an engine for maintaining views on fast-changing streams of data.
What is a materialized view?
Imagine all your data was in a spreadsheet instead of Kafka. The source data would be in massive "Raw Data" worksheets/tabs where rows are continually modified and added. The materialized views are the tabs you create with formulas and pivot tables that summarize or aggregate the raw data. As you add and update raw data, the materialized views are automatically updated.
Why use Materialize?
Materialize works well for this problem for a few reasons:
- Capable of complex joins - Materialize has much broader support for JOINs than most streaming platforms, i.e. Materialize supports all types of SQL joins in all of the expected conditions.
- Strongly consistent - Eventual consistency in a streaming solution can cause unexpected results. Read Eventual Consistency isn't for Streaming for more.
- Simple to configure and maintain - Views are defined in standard SQL, and Materialize presents as PostgreSQL, making it easy to connect and query the results from existing PostgreSQL libraries.
Materialize is source-available and free to run forever in a single-node configuration. There's also a private beta of Materialize Cloud open for registration.
Further reading on Materialize
Build the solution
We'll be using this ecommerce-demo repo because it has convenient examples of Kafka-native and database data:
pageviews- a Kafka-native stream of simulated JSON-encoded web analytics pageview events. Sample pageview event:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
users- a table in a MySQL database with simulated e-commerce shop users with the following attributes:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
The steps below create a real-time join of the pageviews in Kafka and the users table in the database. The resulting materialized view can be read via a query or streamed out to a new Kafka topic.
Initialize the starting infrastructure
Start by creating the following infrastructure as Docker containers:
Before continuing, make sure you have Docker and Docker-compose installed. Clone the repo and use the included docker-compose.yml file to spin up the above containers.
1 | |
2 | |
3 | |
The last line above tells Docker to spin up five specific containers (kafka, zookeeper, schema-registry, mysql and loadgen) from the docker-compose.yml file.
All components need network access to each other. In the demo code this is done via a Docker network enabling services in one container to address services in other containers by name (e.g. kafka:9092).
Start Debezium
Start the Debezium container with docker-compose:
1 | |
This uses the config specified in docker-compose.yml to start a container named debezium with port 8083 accessible to the host using the debezium/connect:1.4 image with the environment variables listed below included:
Point Debezium to MySQL
Debezium is running, but it needs to connect to the database to start streaming data into Kafka. Send the config to Debezium with a curl command:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
The code above sends JSON-formatted config data to the Debezium container which has its internal port 8083 open externally (mapped to host port 8083).
Here is more detail on the above configuration variables:
At this point, debezium is connected to the mysql database, streaming changes into kafka, and registering schema in schema-registry!
Start Materialize
Spin up Materialize in Docker:
1 | |
Materialize is now running in a container named materialized with port 6875 accessible to the host.
Specify data sources in Materialize
Connect to Materialize via the psql command-line interface and specify where to find Kafka data using CREATE SOURCE statements. For convenience, psql is packaged in a Docker container, run:
1 | |
This is equivalent to running psql -U materialize -h localhost -p 6875 materialize
In the psql CLI, create sources for pageviews and users.
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
The code above creates two sources, raw_pageviews, which is currently just raw BYTES, and append-only, and users from the database via Debezium, which is Avro-encoded and uses a special Debezium envelope that takes advantage of the fact that Debezium provides the old and new data in each message.
Create the SQL that converts raw_pageviews into typed columns using CREATE VIEW syntax:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
This is a two-step query that:
- Encodes raw bytes in UTF8 and casts to Materialize
jsonbtype:convert_from(data, 'utf8')::jsonb - Uses PostgreSQL JSON syntax
pageview_data->'user_id'and type casting::<TYPE>to extract four fields into typed columns.
At this point, Materialize still hasn't ingested any data because none of the sources or views have been materialized.
Step 2: Create a materialized view
Time to join the streams. Create a materialized view of pageview counts by channel, segmented by VIP and non-VIP users:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
This looks almost identical to traditional SQL. The only special syntax is CREATE MATERIALIZED VIEW, which tells Materialize to:
- Create a dataflow and arrangements (indexes) to compute and maintain the view.
- Consume all applicable events from Kafka and process them through the dataflow.
- Once caught up with real time, continue to process new events and maintain the view.
Materialize will maintain the view until it is removed with DROP VIEW. No specific time window is necessary. Materialize is joining across all the Kafka events it can ingest.
Test the view by running:
1 | |
Running it multiple times should show the pageview_count updating.
Read output from Materialize
There are two primary ways to access the output of the view, these can be thought of as "poll" (PostgreSQL query) and "push" (Materialize streams output via TAIL or sinks out to a new Kafka topic, downstream service consumes.)
Poll Materialize with a PostgreSQL query
If the joined data is only needed "upon request", for example, in a business intelligence dashboard, admin view, or generated report, a simple PostgreSQL query to the results may be sufficient.
In this approach, the downstream application is given credentials to query Materialize as if it were a PostgreSQL database, this also means that many existing PostgreSQL drivers will work out-of-the-box.
Here is a very simple Python example that uses the psycopg2 module to connect to Materialize and fetch data:
One key difference between querying Materialize and querying a traditional database is that Materialize is doing almost no compute work to respond to each query (the work is done when new data appears in Kafka) so it is perfectly fine to write polling queries that run every second.
Stream output via TAIL
Materialize can stream changes to views out via the TAIL command. For a practical example of how a downstream application can subscribe to the TAIL command see A Real Time Application Powered by Materialize’s TAIL Command.
Stream output into a new Kafka topic
If the end goal is better served by streaming data out into another Kafka topic, use a sink. (See CREATE SINK syntax.) The format of events produced to sinks are similar to CDC events described above, where each event consists of a before and after When a sink is first created, by default Materialize pushes an initial snapshot of the table to Kafka, followed by streaming events for each change to the materialized view specified in the sink.
Connect to Materialize via psql again and add a sink for the view created earlier:
1 | |
2 | |
3 | |
4 | |
5 | |
The code above takes the materialized view pageviews_by_user_segment and creates a sink named pageviews_by_user_segment_sink going to a Kafka topic named pageviews-user-segment-sink in Avro format.
Conclusion + Where to go from here
Hopefully, the explanation and code examples above have helped to demonstrate at a conceptual level how Debezium and Materialize can be used as powerful tools for joining, reducing, and aggregating high-volume streams of data from Kafka and databases into whatever output format your use case demands.
Moving beyond the conceptual phase, there are several next steps to think about like scaling and load, handling schema evolution, and deployment and maintenance of Materialize. If you have questions or are interested in connecting with others using Materialize, join the community in Slack.
