Enterprise streaming SQL on your infrastructure
Run the live data layer for apps and agents inside your own cloud. Keep sensitive data within network boundaries while powering up-to-the-second SQL views with enterprise control and compliance.

Built for operational workloads
Control your data infrastructure
Deploy Materialize in your cloud environment with complete visibility into operations, data flow, and system performance.
Handle complex operational workloads
Move complex analytical queries from operational databases to Materialize. Handle joins across multiple tables and real-time aggregations without impacting transaction processing.
Create live dashboards that update as source data changes. Join data from multiple systems with strong consistency guarantees for accurate business metrics.
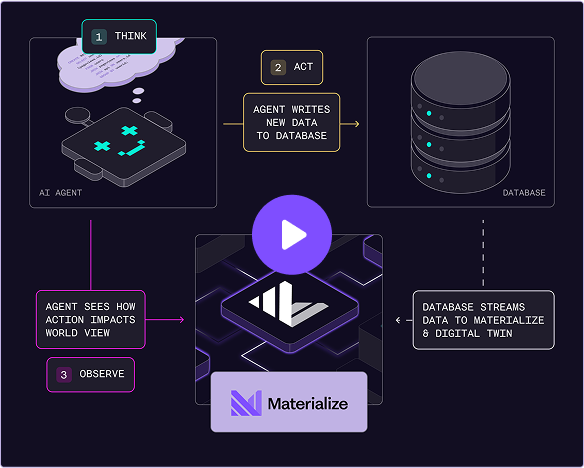
Provide AI agents with current business context through digital twins. Maintain fresh views of customers, orders, and operational state for agent decision-making.
Generate reliable events as data changes to update search indexes, send alerts, or initiate workflows. Subscribe to query results for push-based notifications.
Maintain complex feature computations incrementally. Generate features for fraud detection, recommendation systems, and real-time inference workloads.
Built on proven stream processing technology
Materialize uses Timely and Differential Dataflow, developed at Microsoft Research over a decade ago. These mature foundations are proven in production across financial services, e-commerce, and large-scale data systems.. Handle inserts, updates, and deletes correctly while maintaining sub-second data freshness.
Write standard SQL transformations
Create materialized views using familiar PostgreSQL-compatible SQL. Support for complex joins, window functions, recursive CTEs, and aggregations. No need to learn new APIs or stream processing frameworks—use the SQL knowledge your team already has.
Architecture and operations
Understand how Materialize Self-Managed integrates into your infrastructure and operational practices.
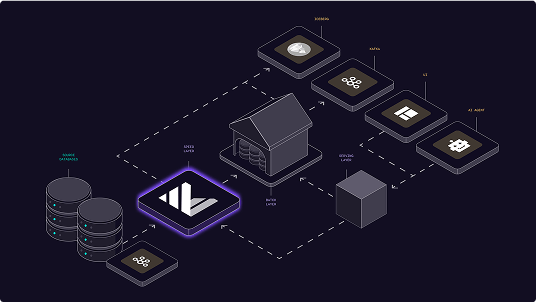
Runs on Kubernetes 1.20+ or Docker. Requires persistent storage and network access to source systems. Supports horizontal scaling across multiple nodes with automatic resource management.
Connect via Change Data Capture (CDC) from databases, consume from Kafka topics, or use direct SQL inserts. Built-in connectors for PostgreSQL, MySQL, SQL Server, and other common sources.
Expose Prometheus metrics for system health, query performance, and resource utilization. Integrate with existing monitoring stacks and alerting systems. Access detailed query plans and execution statistics.
Support for point-in-time recovery and automated backups. Replicate data across availability zones for high availability. Export materialized view definitions and data for disaster recovery scenarios.
Deploy Materialize in your environment
Start with a proof of concept using our containerized deployment. Scale to production with enterprise support and professional services for implementation guidance.