The Software Architecture of Materialize
February 23, 2023
important
Materialize is a fast, distributed SQL database built on streaming internals. Data and software engineering teams use it to build apps and services where data must be processed and served at speeds and scales not possible in traditional databases. To see if it works for your use-case, register for access here.
Introduction
Materialize is divided into three logical components: Storage (including Persist), Adapter, and Compute. These are hosted by two physical components: environmentd and clusterd. Broadly speaking, clusterd handles data plane operations, which run in Timely Dataflow. It can be scaled to arbitrarily many processes (for throughput) and replicas (for reliability). environmentd, on the other hand, handles control plane operations; e.g., instructing clusterd to perform various operations in response to user commands, maintaining the catalog of SQL-accessible objects, and so on.
Here is an illustration of the high-level architecture:
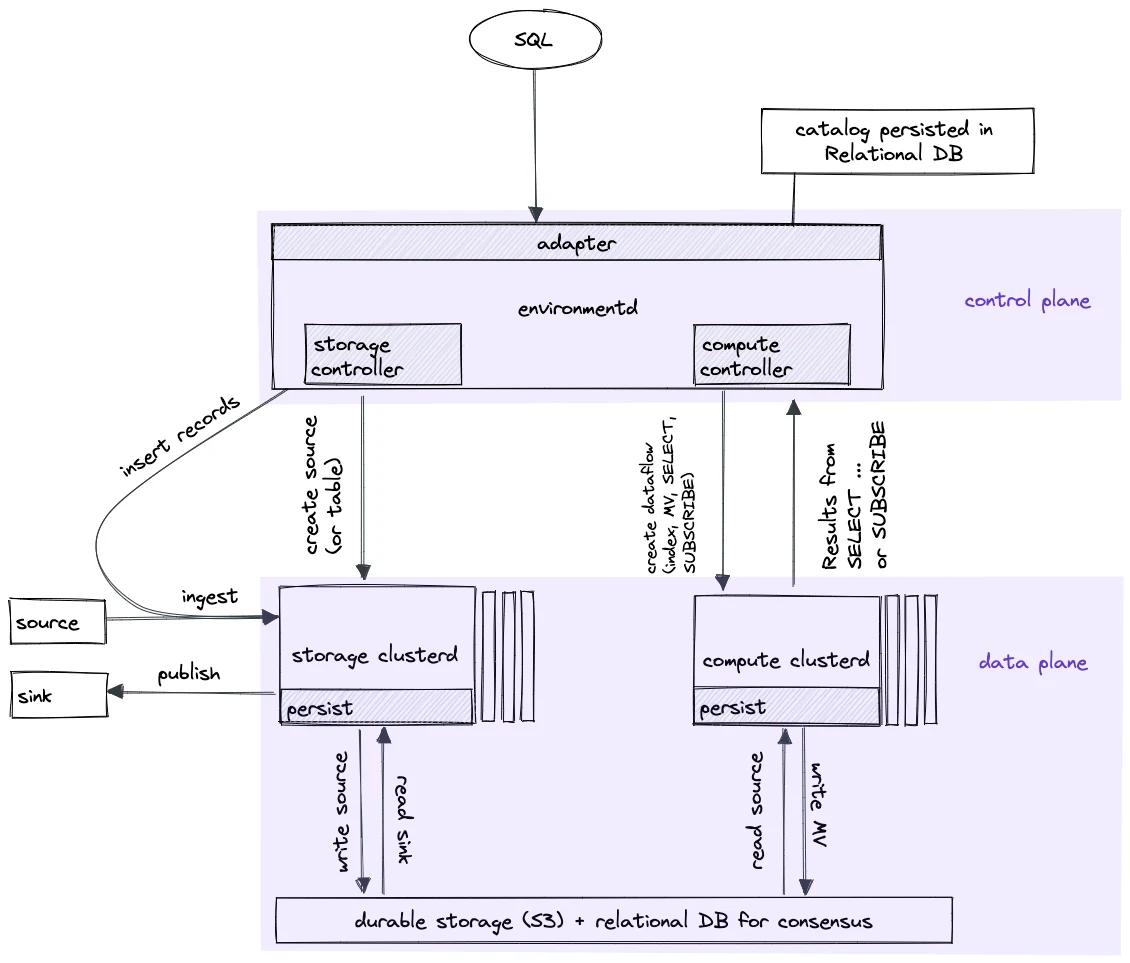
In this post, we will dive further into each of the aforementioned logical components, and explain how they fit together.
Logical Structure
Key Abstraction: Persist and pTVCs
Persist is a library widely used by the rest of Materialize for maintaining durable named time-varying collections: a term that was invented at Materialize and therefore requires some explanation. A collection is a set of rows along with their counts (which can be negative); other than the fact that a count can be negative, collections can be thought of as corresponding to the durable relations (tables and materialized views) maintained by other familiar databases. A time-varying collection (TVC), as the name suggests, models a sequence of versions of a collection, each version representing the value of the collection at a point in time.
It is not possible to physically represent most TVCs in their entirety, since the set of possible times is nearly unbounded. Instead, Persist operates on partial time-varying collections (pTVCs), which are TVCs restricted to a particular interval. Every pTVC managed by Persist is associated with lower and upper bounds. As readers of a pTVC declare that they are no longer interested in past times, the lower bound advances (allowing old versions to be discarded); as writers declare that they have finished writing data for a given timestamp, the upper bound does so as well. Thus, these bounds are also called read frontiers and write frontiers, respectively. To be clear, advancement of the read frontier does not mean discarding old data, assuming that data is still present in the up-to-date version of the collection. It only means discarding the ability to distinguish between several old versions. For example, if a record is inserted and later updated, and then the read frontier moves past the timestamp at which the update occurred, the old value of the record can no longer be recovered.
The conceptual reason for representing relations as TVCs, rather than as point-in-time collections, is twofold. The first reason is that this representation can in principle allow time-travel queries; that is, it can allow users to query past states of relations. However, this functionality has not yet been implemented in Materialize except for on a few system-managed metadata tables. The second and more fundamental reason is that it allows updating the results of downstream computations based on differences, rather than recomputing them on the entire relation. Indeed, pTVCs are physically represented as a stream of diffs: rather than storing separate full versions of each collection, we associate each timestamp with the list of rows that were added or removed at that timestamp. The key insight behind Differential Dataflow is that this representation makes it possible for result sets to be incrementally maintained; all of our compute operators translate lists of input diffs to lists of output diffs, rather than whole input relations to whole output relations. This is what allows Materialize to operate as a true streaming-first operational data warehouse, which one might succinctly define as a data warehouse that requires effort proportional to the sizes of the changes in inputs and outputs to compute updated results, rather than proportional to the sizes of the inputs and outputs themselves.
Storage
The Storage component is responsible for maintaining pTVCs, as well as providing an API connecting them to the outside world. It is thus considered to include both Persist (described above), as well as "Sources and Sinks", which we describe in this section.
Sources and Sinks handles ingestion of data from external sources into Materialize, as well as emission of data (after processing) to downstream systems like Redpanda or Kafka. Since durable relations in Materialize are represented as pTVCs maintained by Persist, another way to describe this component is to say that it translates between Persist's native representation and those understood by the outside world.
A fundamental role of Sources is to make data definite: any arbitrary decisions taken while ingesting data (for example, assigning timestamps derived from the system clock to new records) must be durably recorded in Persist so that the results of downstream computations do not change if re-run after process restart.
Storage workflows run on clusters -- potentially the same clusters that are used for compute workflows.
Adapter
Adapter can be thought of as the "Brain" that controls the other components, as it is what takes requests from the user and in response issues instructions to Storage and Compute. It handles a variety of different tasks which are described below.
Postgres protocol termination
Materialize intends to be mostly PostgreSQL-compatible, and the relevant code lives in the Adapter component. It presents to the network as a PostgreSQL database, enabling users to connect from a variety of tools (such as psql) and libraries (such as psycopg).
SQL interpretation and catalog management
Queries to Materialize arrive as SQL text; Adapter must parse and interpret this SQL in order to issue instructions to other systems. Adapter is responsible for managing the catalog of metadata about visible objects (e.g., tables, views, and materialized views), performing name resolution, and translating relational queries into the IR understood by Compute.
Timestamp selection
Every one-off query in Materialize occurs at a particular logical timestamp, and every long-running computation is valid beginning at a particular logical timestamp. As discussed in the section on Persist, durable relations are valid for a range of timestamps, and this range is not necessarily the same for every collection. Adapter must therefore track the available lower and upper bounds for all collections, in order to select a timestamp at which it will be possible to compute the desired result. This task is further complicated by the requirements of our consistency model; for example, in the default STRICT SERIALIZABILITY mode, time cannot go backwards: a query must never return a state that occurred earlier than a state already reflected by a previous query.
Compute
The Compute component transforms durable pTVCs into other pTVCs (either durable materialized views stored in Persist, or in-memory indexes) according to programs written in Materialize's internal IR. This language supports all the typical operations of relational logic that are familiar to SQL users, such as joins, reductions (GROUP BY), and scalar transformations.
When a user instructs Materialize to perform a computation (either a one-off SELECT query, a materialized view, or an in-memory index), Adapter supplies Compute with a compiled description of the query: an IR program describing the computation to run, a logical timestamp at which the computation should begin, and a set of Persist identifiers for all the durable inputs and outputs of the computation. Compute then transforms the IR according to several optimization passes, and finally compiles it into a Differential Dataflow program which streams input data from Persist and emits the required result -- either returning it to Adapter in the case of a one-off query, arranging it in memory in the case of an index, or writing it back to Persist in the case of a materialized view.
Physical Structure
The logical structure of Materialize components intentionally does not directly correspond to the physical layout in terms of networked processes. The split was chosen to allow user-defined scaling and redundancy of code that runs on the data plane.
Concretely speaking, there are two classes of process in a Materialize deployment: environmentd, which contains all of Adapter as well as part of Compute and Storage (in particular, the controllers that maintain the durable metadata of those components), and clusterd, which contains the rest of Compute and Storage (in particular, the operators that actually process data). Furthermore, all Materialize processes run the Persist library, which handles storing and retrieving data in a durable store.
The key difference between the two is that clusterd deployments are controlled by the user (with commands like CREATE CLUSTER and CREATE SOURCE), whereas environmentd is managed by Materialize itself and its size and number of machines is not configurable.
Clusters and replicas
clusterd processes are organized into clusters and replicas, whose existence and size are under the control of the user. Each cluster is associated with a set of dataflow programs, which describe either compute tasks (such as maintaining an in-memory index or materialized view, or responding to a query) or storage tasks (such as ingesting Avro data from a Redpanda source into Persist or emitting data from Persist to a Kafka sink). Each cluster is further associated with zero or more replicas, which contain the actual machines processing data. Note that a cluster with zero replicas is not associated with any machines and does not do any useful work: a cluster is only a logical concept, and what might be called an "unreplicated cluster" in other systems would be called a "cluster with one replica" in Materialize.
Each replica may, depending on its size, be made up of one or more physical machines across which indexes (both user-visible indexes and internal operator state) are distributed. The communication among processes of a replica is an implementation detail of Timely Dataflow and Differential Dataflow -- final results are assembled by environmentd into a cohesive whole; thus, the user need not be concerned with how data is sharded among a replica's processes (except perhaps for performance optimization reasons).
The compute and storage controllers in environmentd ensure that each replica of a given cluster is always executing an identical set of dataflow programs. For a given query, the controller simply accepts the results of whichever replica returns first. Because all queries executed by Compute are deterministic, this has no bearing on results. For data that is written by Compute to Persist (to maintain a materialized view), Persist's consensus logic ensures that the data for a given range of timestamps is only written once.
Persist details
Persist is not a separate process; it is distributed across all Materialize processes; that is, compute clusters (which read the inputs and write the outputs of computations), storage clusters (which write data from the outside world into Persist), and the environmentd process (which uses metadata from Persist to determine the timestamps at which queries may validly be executed).
Concretely, the various processes' Persist instances store their pTVCs in S3 and maintain consensus among themselves using a distributed transactional database.
Communication among processes
Materialize processes communicate directly in the following ways:
- Processes within the same replica exchange data via the Timely Dataflow network protocol, which is outside the scope of this document; and,
- The Compute and Storage controllers in
environmentdcommunicate with eachclusterdto issue commands and receive responses.
And that's it! Note in particular that there is no direct network communication between different clusters, nor even between different replicas of the same cluster. Thus, the only way for clusterd processes to consume their inputs or emit their outputs is by reading or writing them in S3 via Persist. It follows that clusters are the domain of state sharing; an in-memory index lives on a particular cluster and is not visible to others. To share data between Compute workflows on different clusters (for example, if one cluster does initial transformation of some data, which is then further transformed by several different workflows downstream), the user would create a materialized view in one cluster and read from it in another, causing the data to be transferred via Persist and S3.
Future work
We think the current architecture works well for a wide variety of use cases. However, there are a variety of major improvements that should be made in the future, of which I call out a sample here.
Moving computation to sources
Currently, at source ingestion time only a restricted menu of pre-defined logic can be applied; for example, decoding bytes as Avro or interpreting Debezium-formatted data. Arbitrary user-defined logic only runs in Compute clusters.
The limitation of this approach is related to the fact that the full output of all sources is stored in Persist, which may be prohibitive. For example, a source may consist of a long series of historical events, when the user only cares about the last five minutes. The temporal filter to restrict the source to that window can only be applied downstream, in the compute cluster, requiring the entire source to be stored in S3 first.
Thus, it is useful to be able to push some subset of our compute capabilities (that subset which is particularly useful for "stream processing") upstream into the sources. This feature is under active development, so stay tuned!
Scalability and fault-tolerance of environmentd
As discussed above, environmentd only handles control plane operations, and so a rather small single-process deployment can manage the entire Materialize instance for a wide variety of workloads, even those involving large volumes of data. However, there are possible usage patterns for which environmentd can become a bottleneck, especially those involving very large volumes of concurrent connections or queries.
To this end, we plan to split environmentd into several processes, so that potentially expensive pieces of it (e.g., the query optimizer) can be scaled independently, and limit as much as possible the set of code that has to run in a single main thread.
We also plan to allow replication of environmentd components (as we already do for clusters), further improving the reliability of the system.
